이번 글에서는 Hadoop에서 지원하는 파일저장시 지원하는 자료구조 2가지를 알아본다. 파일에 데이터를 저장시 그냥 blob 전체를 한개의 파일에 그대로 몽땅 저장하는 방식을 생각해보자. 그러면 파일의 내용은 block 크기로 잘라져 논리적으로 연속된 block으로 보일 것이다. 다만 이런 방식이면 경우에 따라 확장성에 좋지 않을 수 있다. 따라서 다양한 상황을 위해 Hadoop은 여러 파일 기반의 자료구조를 지원한다. 즉 스토리지에 저장시에 고려하는 자료구조이다. 여기서 볼 자료구조는 SequenceFile과 MapFile이다.
SequenceFile
SequenceFile은 로그파일과 잘맞는다. 로그파일은 record 한개당 하나의 행이다. 이런 로그파일을 그냥 binary로 저장하는것은 이후에 이 로그파일을 기반으로 무언가 작업을 할 예정이라면 확장성이 없는 방식이다. Hadoop에서 제공하는 SequenceFile은 이런 형식의 데이터를 저장하기에 적절하다. SequenceFile은 binary key-value 쌍에 대한 storage-level의 자료구조를 제공한다. 예를들어 로그의 포맷이라면 key를 Hadoop의 LongWritable로 표현되는 timestamp로, value를 로그의 내용으로 저장할 수 있겠다.
SequenceFile format
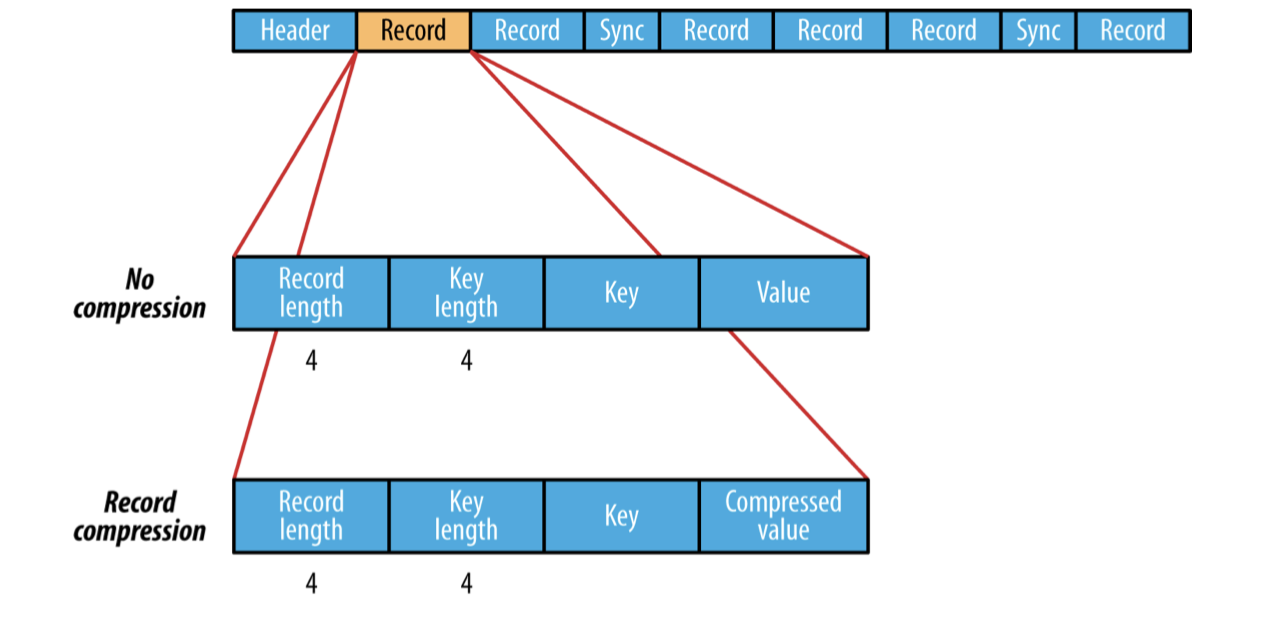
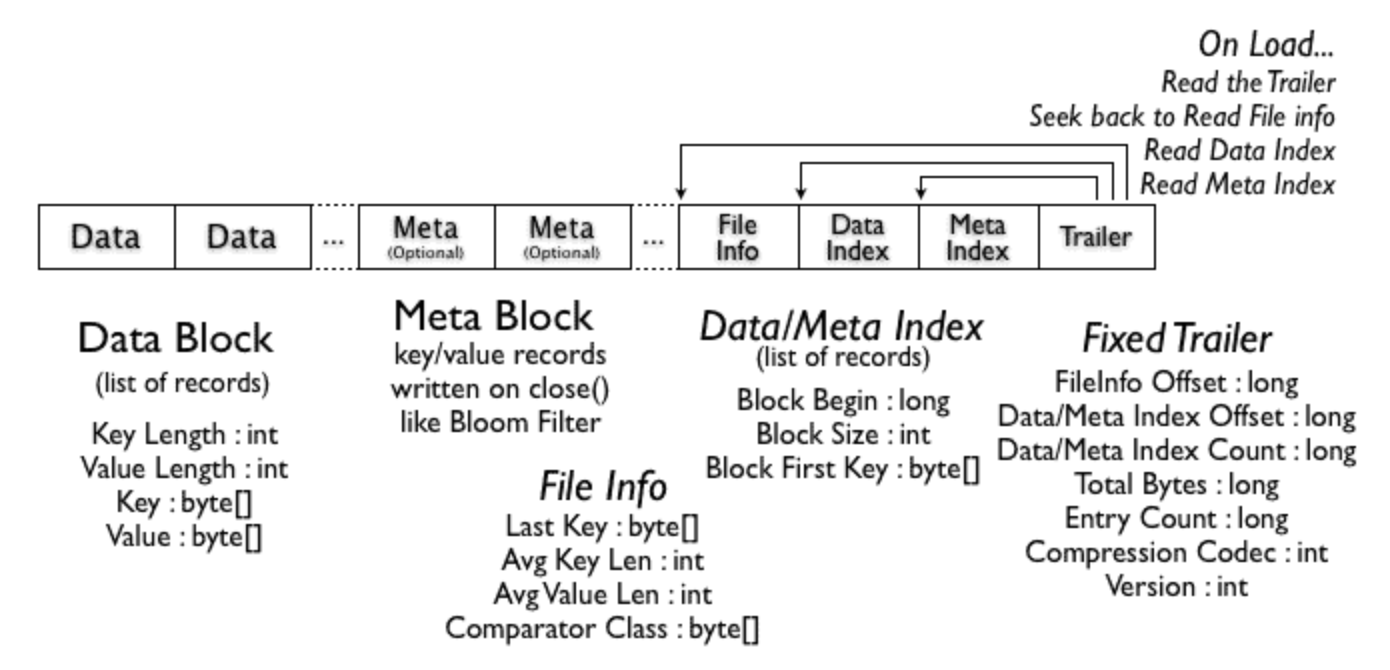
SequenceFile의 포맷을 조금 더 자세히 보자. SequenceFile의 대략적인 내부구조는 다음과 같다.
맨앞에는 header가 오고 그 뒤에는 하나이상의 record들이 위치한다. header에는 key, value 클래스의 이름, 압축이 되어있다면 압축관련정보 그리고 sync marker등이 존재한다. SequenceFile에서는 sync point라는 것이 존재한다. SequenceFile에 write 할때 몇개의 record 단위마다 sync point를 marking 해놓는다. 이 sync point는 반드시 record 경계에 맞추어진다. 이 sync point는 reader가 record 경계를 잃어버렸을때 record 경계를 다시 동기화 하는데에 사용할 수 있다. 예를들어 파일의 위치가 record 경계에 있지 않으면 reader의 읽기 메서드가 예외를 반환한다. 이런 경우에 SequenceFile.Reader의 sync(long position) 메서드를 호출하면 position 이후의 바로 다음 sync point로 read point를 이동시켜준다. 그러므로 그 다음부터는 읽기를 다시 정상적으로 수행할 수 있다. 위 그림에서도 몇개의 record 단위마다 sync point가 저장되어있는 것을 확인할 수 있다. 각 SequenceFile은 랜덤하게 생성된 sync marker가 있고 이 값이 header에 존재한다. 그리고 이 sync marker가 위에서 본 sync point 마다 값이 저장되어 있는것이다.
이제 record는 내부구조가 어떤지 살펴보자. 만약 record가 압축되어있지 않다면 각 record 들은 위의 그림과 같이 byte 단위의 record length, key length, key, value로 구성된다. record가 압축이 되어있는 경우는 압축하지 않은 경우와 거의 동일하지만 value가 header에 명시된 codec으로 압축된 binary 인 점만 다르다.
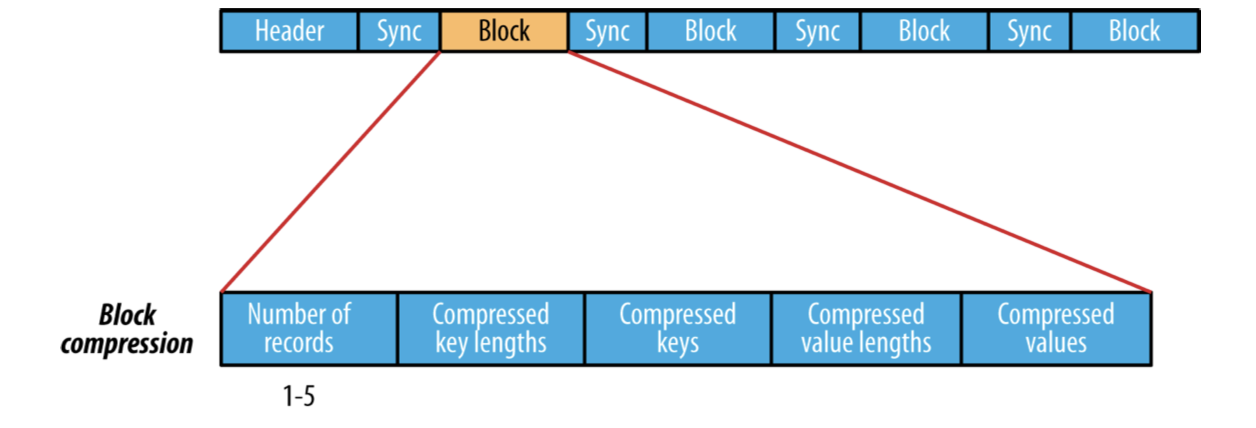
여러개의 record을 모아 block을 구성하고 이 block을 압축하는 방식도 있다. 여러개의 record로 구성된 block 자체를 압축하므로 record 단위 압축보다 압축도가 높고 가까이 있는 record 간에 유사성이 높으므로 효율도 더 좋을 수 있어 record 단위의 압축보다는 block 단위 압축방식이 더 선호된다. record들은 io.seqfile.compress.blocksize 설정값에 정의된 크기에 이를때까지 하나의 block에 계속 추가된다. 이 설정의 기본값은 1MB이다. Block compression 방식의 내부구조는 다음과 같다.
이 SequenceFile은 대용량 dataset에 적합하다. 효율적으로 대용량 dataset을 처리하는데 효율적으로 설계되었으며, 각 SequenceFile 의 부분들을 병렬로 처리하도록 설계할 수도 있다. 또 파일의 순차접근에 강하며 파일을 저장할때 그냥 binary format으로 저장하기 때문에 매우 심플하고 다른언어에서도 이를 쉽게 다룰 수 있다.
다만, Parquet 이나 ORC 같은 포맷에 비해서는 공간효율적이지는 못하다. 그리고 random access 를 위해 설게된 것은 아니기에, random access 가 자주 사용되는 애플리케이션에서는 SequenceFile이 비효율적 일 수 있다. 그리고 schema 변화를 제한적으로만 지원하기 때문에 데이터 구조를 변경하는 것이 힘들다.
MapFile
MapFile은 key를 기준으로 정렬이 되어있는 SequenceFile이다. 앞에서 본 SequenceFile은 record들이 정렬되어있을 필요는 없었다. 다만 MapFile은 반드시 record 들이 key 기준으로 정렬되어있어야 한다. 그리고 MapFile은 index를 통해 key로 record를 빠르게 검색할 수 있다. MapFile을 생성하게 되면 directory가 생성되고 이 내부에 data 파일과 index 파일이 각각 존재한다. 여기서의 data 파일과 index 파일 모두 SequenceFile이다. data 파일은 key로 정렬된 record들로 구성되어 있으며 index 파일도 내부에 key들의 fragment들을 포함하고 있는 SequenceFile이다. index는 기본적으로 data record의 128번째마다 key를 저장해둔다.
MapFile에서 key 검색을 위해서는 index를 메모리에 올려 index를 기준으로 data record의 위치를 찾는다. MapFile은 SequenceFile과 조금 다르게 파일에 쓸때에는 반드시 key로 정렬된 순서로 write해야한다. 그렇지 않으면 예외가 발생한다.
Other File format
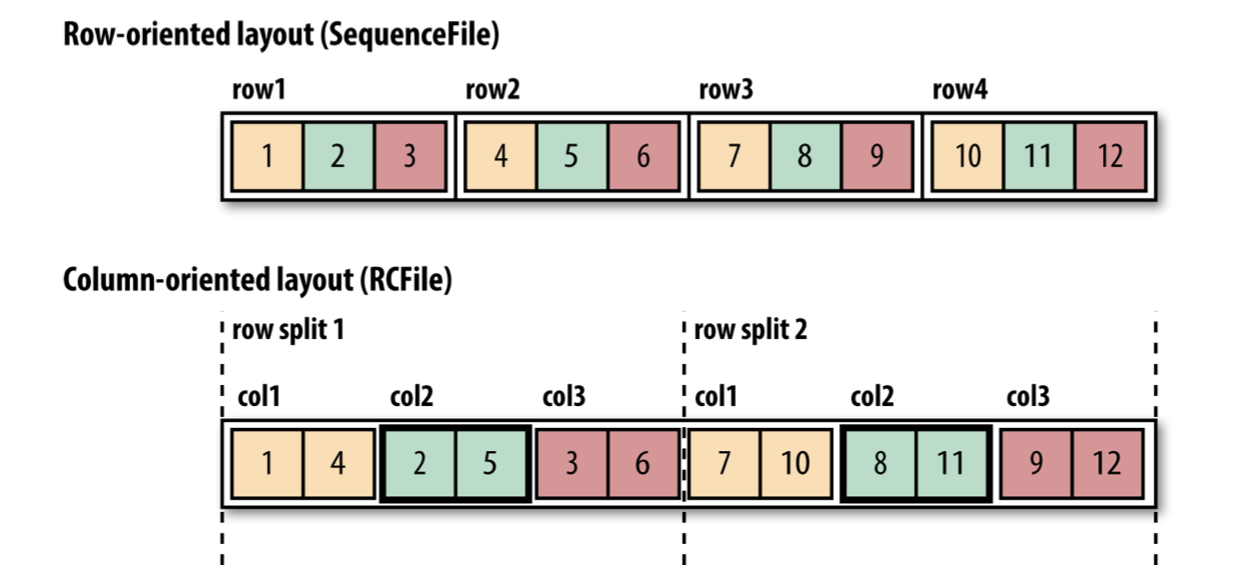
Hadoop은 SequenceFile과 MapFile 말고도 다른 새로운 파일포맷도 많이 제공한다. SequenceFile, MapFile은 모두 row 기반의 파일포맷이지만 이 방식 말고도 column 기반의 파일포맷도 존재한다. column 기반의 파일포맷에서는 각 row를 컬럼기준으로 나누어 저장한다. 예를들어 다음 그림처럼 첫번째 column이 먼저 저장되고, 그 다음 column이 저장되는 방식이다.
만약 이 data들이 table의 데이터고 table에서 특정 column만 쿼리하는 과정을 생각해보자. 기존의 row 기반의 파일포맷은 관련있는 row를 모두 읽어 메모리로 읽어들인 후에 이들을 역직렬화하여 column을 뽑아내야한다. 하지만 column based 파일포맷은 직접 필요한 소수의 column만 읽어들일 수 있는 장점이 있다.
HBase는 데이터들을 table안에 구성한다. table 이름은 String으로 파일시스템 path로 사용하는데 문제없도록 구성한다.
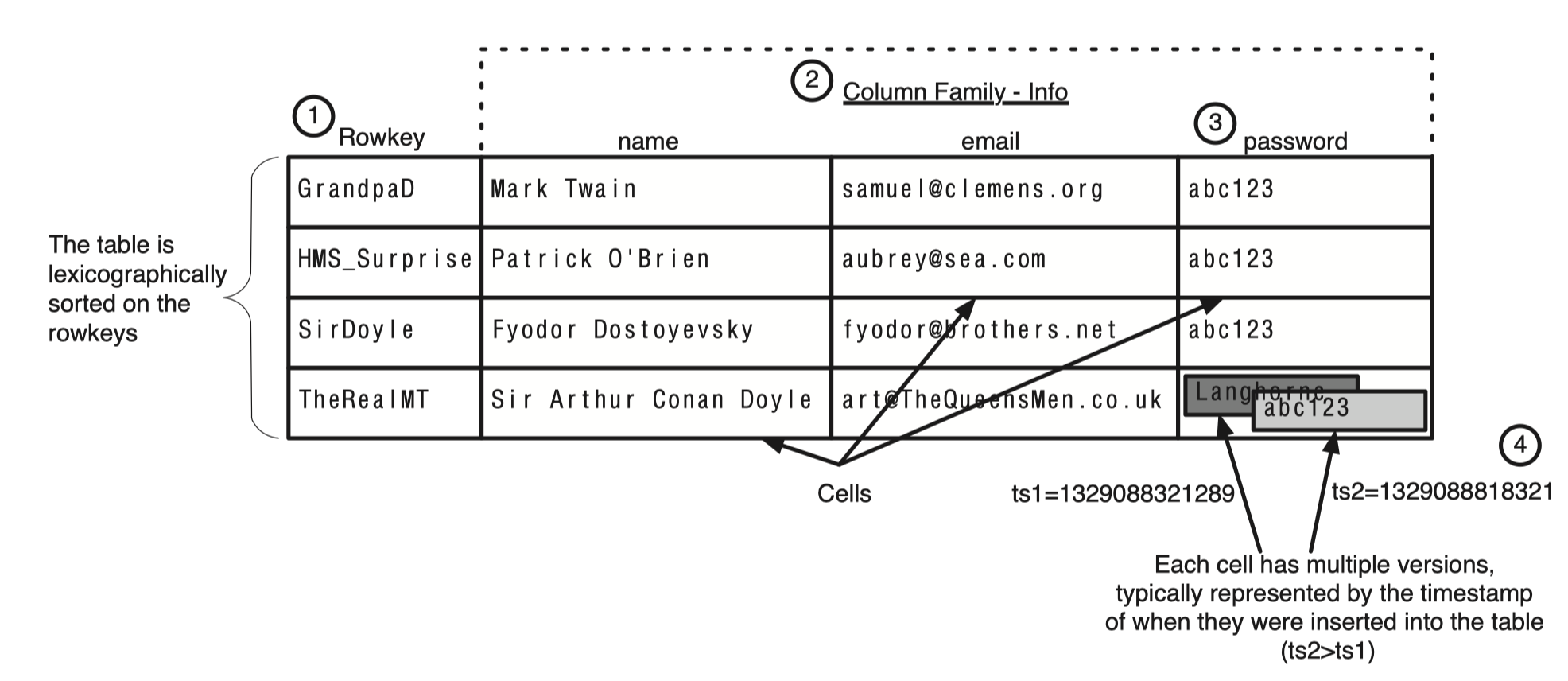
Row
Table 안에서 데이터는 table의 row에 따라 저장된다. Row는 rowkey에 의해 유일하게 식별되고 rowkey는 다른 data type을 가지지 않고 byte[]로 구성된다. 한개의 Row는 한개 혹은 여러개의 record로 구성된다.
Column Family
HBase에서의 column들은 Column Family 라고 부르는 일종의 그룹에 속한다. HBase의 테이블은 최소한 한 개 이상의 column family를 가져야 한다. Row의 record들은 column family로 그룹화된다. Column Family는 중요한데 HBase에서 데이터 저장에 있어 물리적인 특성과 관련이 깊다. 각 column family 마다 storage 관련 속성(caching 여부, 압축여부 등)을 지정할 수 있다.
Column Qualifier
column family 안의 데이터들은 column qualifier를 통해 표현된다. 만약 column family가 info 라면 column qualifier는 info:name 나 info:email 등이 될 수 있겠다. column qualifier는 미리 정의되어있을 필요가 없으며 각 row들마다 일관성없이 다른 column qualifier들을 가질 수 있다. Column Qualifier은 그냥 column 이라고도 불리고 qual 이라고도 불린다.
Cell
Cell은 rowkey, column family, column qualifier의 조합이다. 이 조합이 cell을 식별한다. 이 cell에는 value로 데이터가 저장되어있고 version을 의미하는 timestamp도 포함한다.
Version
Cell 내부의 value들은 version 별로 저장이 된다. version은 long 타입의 timestamp이며 이 값을 따로 지정하지 않으면 현재 timestamp 값으로 설정된다. HBase에서 각 column family 마다 cell 마다 유지되는 version 개수를 설정할 수 있으며 기본값은 3이다.
위의 6가지 개념에 대해 이해한다면 앞으로 HBase를 이해하는데 크게 도움이 된다. 다음 그림을 보자.
각 row는 한개 이상의 cell들로 구성되어있고 각 row는 rowkey를 기준으로 정렬되어있다. 각 cell에는 여러개의 version이 저장되어 있는 것도 확인할 수 있다.
Cell Coordinate
HBase에서 cell 값은 coordinate에 의해 접근된다. 말 그대로 좌표라는 의미이다. coordinate는 rowkey, column family, column qualifier 순서의 조합이다. 논리적인 그림으로 생각했을때에 결국 HBase는 coordinate를 key로 각 coordinate의 데이터를 value로 가진 key-value 저장소로 생각할 수 있다. HBase에서 데이터를 얻기위해 Get 요청을 할때 coordinate 정보 전체를 제공하지 않아도 된다. 만약 rowkey, column family, column qualifier로 요청한다면 version 별 map을 결과로 얻을 수 있다.
Cell Key
HBase에서 cell key는 rowkey, column family, column qualifier, version 의 조합이다. 밑에서 보게되겠지만 HBase는 HFile 이라는 형식으로 데이터를 저장하는데 HBase의 cell key는 이 HFile의 key 이고 이 cell key로 정렬이 되어있다.
HBase는 엄격한 데이터 규칙이 없는 semi-structured 데이터들을 위해 설계되었다. 이런 semi-structured 논리 모델로 데이터들은 각 데이터 컴포넌트들 간의 느슨한 연결을 가지도록 하고 이런 구조로 물리적으로 scale을 쉽게 해준다. 애초에 HBase는 scale을 염두에 두고 설계되었고 이런 결정이 물리모델에 영향을 끼치고 있다. 다만 이런 물리적 모델 특성으로 RDBMS에서 제공하는 multirow transaction을 지원하지 못한다. 밑에서 HBase의 논리적 모델과 물리적 모델을 살펴보자.
Logical Model
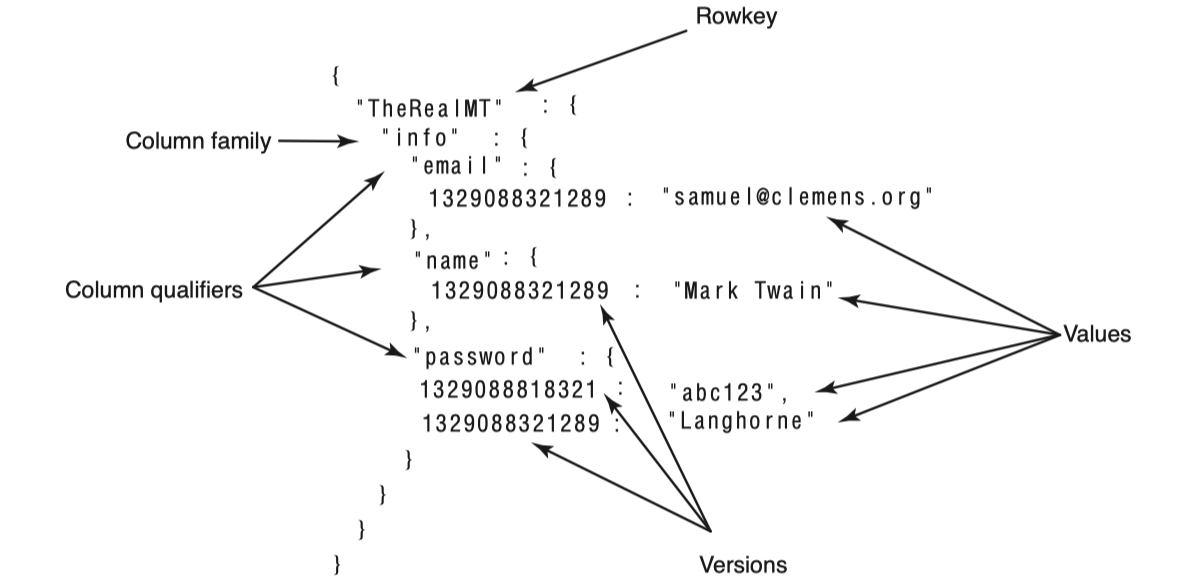
HBase가 논리적으로는 어떤 모델을 가지고 있는지 이해하면 HBase를 쉽게 이해할 수 있다. HBase는 맵들의 정렬된 맵(sorted map of maps)이라고 바라볼 수 있다. 먼저 다음 그림을 보며 이해해보자.
이처럼 논리적으로 데이터를 map 구조로 표현할 수 있다. 이는 “TheRealMT” 라는 rowkey의 데이터를 가지고 온 내용이다. Map을 자세히 보면 map의 가장 안쪽에서는 cell의 version이 key이고 저장된 데이터가 value이다. 그 한단계 위에서는 column qualifier가 key이고 cell이 value이다. 결국 이를 자바로 표현하면 이와 같을 것이다. Map<RowKey, Map<ColumnFamily, Map<ColumnQualifier, Map<Version, Data>>>>
또하나 주목할 점은 sorted map이라는 것은 key로 정렬되어있다는 것이다. 위 예제에 password는 2가지 version이 존재하는데 항상 새로운 version이 더 앞에오도록 정렬되어있다. HBase는 내림차순으로 version timestamp을 정렬한다. 그러므로 최근 version에 대한 빠른 접근을 가능하게 한다. version이 아닌 다른 key들은 모두 오름차순으로 정렬되어있는 것을 확인할 수 있다. 이런 특징은 schema 설계시 매우 중요하다.
Physical Model
HBase는 HFile에 key-value 형식으로 저장이 된다. 위에서 보았던 “TheRealMT” 라는 rowkey를 가진 데이터는 다음과 같이 HFile에 저장된다.
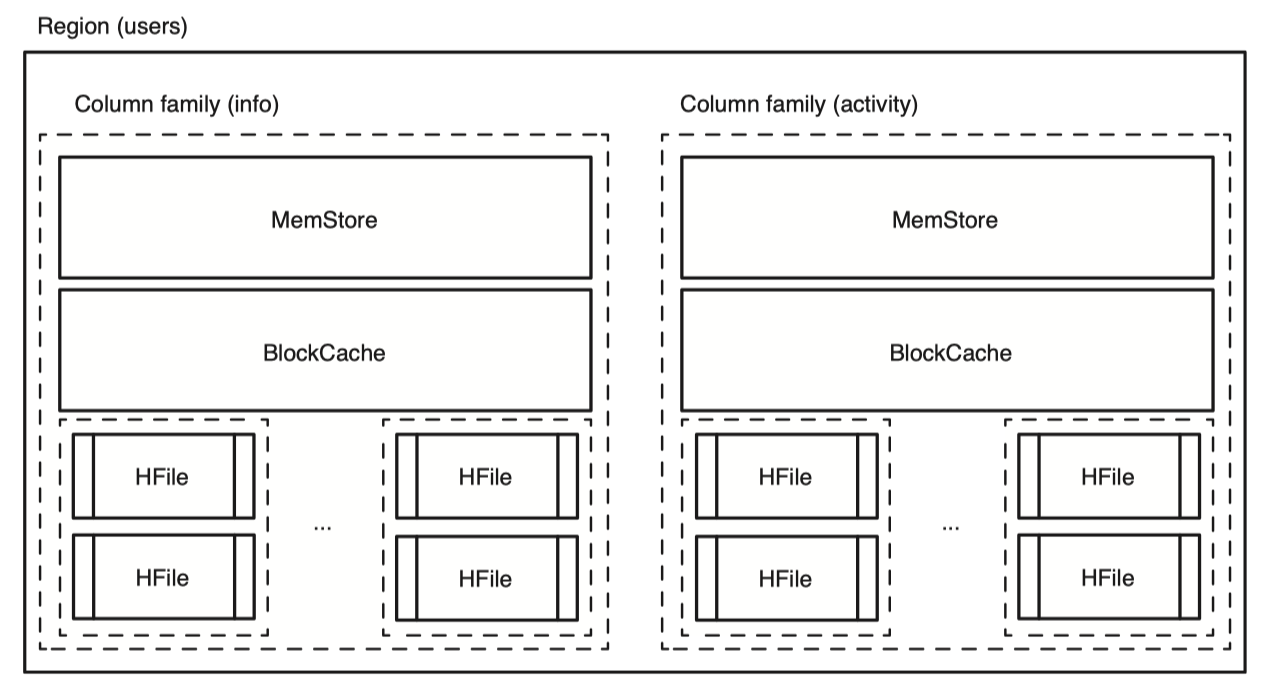
이처럼 row 1개는 HFile 안에서 여러개의 record로 이루어져 있다. 또한 사용되지 않거나 null인 record가 없다. HBase는 데이터가 없을시에는 아예 아무것도 저장하지 않는다. 또 한가지 주목할 점은 HFile은 column family 별로 따로 생성된다. 하지만 같은 column family를 가진 single row도 동일한 HFile에 같이 존재하지 않을 수 있다. 이미 존재하는 rowkey에 새로운 column qualifier로 데이터를 넣는과정을 예시로 들 수 있겠다. 그러므로 single row 전체를 다 읽으려면 모든 HFile을 다 확인해야한다. 각 column family 별로 별도의 HFile을 사용하므로 HBase는 read 수행시 요청된 column family에 해당하는 HFile들만 읽으면 된다. 이런 물리적인 특성들은 storage를 더 효율적으로 사용하고 빠른 읽기를 가능하게 한다.
위 그림처럼 새로운 column family인 “activity”를 추가했다고 해보자. 이는 더 많은 HFile을 만들어내고 기존의 “info” column family와는 격리되어있고 전혀 다른 HFile을 만들어 내고있다. activity column family 내의 데이터가 커져도 info column family 성능에는 영향을 주지 않는다.
Data in HBase
HBase 테이블의 모든 row는 rowkey라는 유일한 식별자를 가지고 있다. 이는 테이블 내에서 유일한 값이다. HBase에 저장된 모든 데이터들은 byte array 형태의 raw data로 저장된다. 자바 클라이언트 라이브러리에서는 이를 위해 Bytes 클래스를 제공해 다양한 형태의 데이터를 byte array로 바꿀 수 있다.
위에서 보았듯이 cell은 [rowkey, column family, column qualifier] 좌표로 결정된다. 밑의 예제를 한번 보자.
여기서 Put 객체를 만들었는데 이는 새로운 data를 저장할때나 기존에 존재하는 row를 수정할때 사용한다. 여기서는 info라는 column family에 속한 name, email, password라는 column에 값을 설정했다. 이름을 저장하고 있는 cell의 coordinates는 [TK-one, info, name] 이다.
HBase write
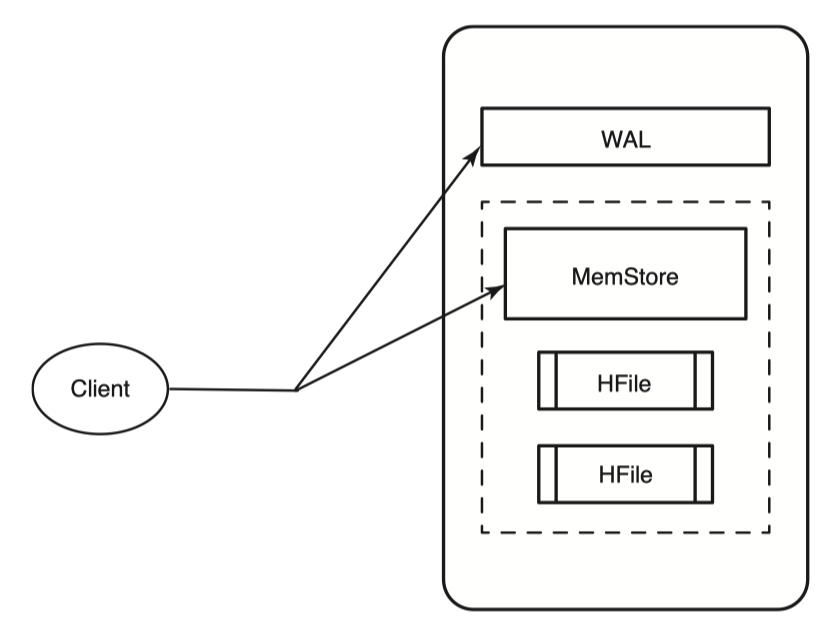
새로운 row를 만들때나 기존 row를 수정할때나 내부 프로세스는 동일하다. HBase는 command를 받으면 변경사항을 저장하고 만약 저장에 실패했으면 예외를 발생시킨다. 변경사항을 저장할때 기본적으로 두곳에 변경사항을 저장한다. 첫번째는 WAL(Write Ahead Log)에 저장한다. 이는 HLog라고도 불린다. 두번째는 MemStore에 저장한다. HBase는 기본적으로 data의 내구성을 위해 두곳에 모두 저장한다. 두곳에 모두 저장해야 write가 완료된다.
Memstore는 HBase에서 disk에 write하기 전에 HBase 메모리에 데이터를 모아놓은 buffer이다. 나중에 Memstore가 가득차게되면 HFile이라는 형태로 disk에 flush된다. 이미 존재하는 HFile에 append하는게 아니라 매 flush 마다 새로운 파일을 만든다. 여기서의 HFile은 HBase에서 사용하는 storage용 format이라고 생각하면 좋다. HFile은 1개의 column family에 속해있다. 즉 하나의 HFile은 여러개의 column family로 이루어진 데이터를 가질 수 없다. Column family 당 1 개의 Memstore를 가지고 각 Memstore들은 가득차면 HFile로 flush 된다. 이 HFile도 HDFS에 저장된다.
HBase에도 장애가 발생할 수 있다. 만약 서버가 다운되어 in-memory data를 모두 잃었을때는 아직 flush되지 않은 Memstore의 내용은 모두 유실될 것이다. HBase는 write 시에 WAL(Write Ahead Log)에 data를 write 하기때문에 이 WAL를 다시 replay 함으로서 MemStore 내용을 복구할 수 있다. HBase는 모든 변경사항을 WAL에 쓴다. 그리고 HBase는 이 WAL을 HDFS에 쓴다. HBase의 Region 서버가 다운되어도 WAL을 HDFS에 썼다면 replica 3개중 아무곳에서 데이터를 제공받아 recover 할수있다. 만약 WAL이 Region 서버의 local disk에만 제공된다면 data loss가 발생할 수 있으므로 HDFS에 write 한다. 이 말고도 HDFS는 HBase Region 서버들에게 단일 namespace 파일시스템으로서 역할을 하기때문에 모든 Region 서버들은 다른 Region 서버들이 쓴 데이터들을 모두 볼 수 있다. 그러므로 Region 서버 장애시 다른 Region 서버에서 손쉽게 해당 WAL을 읽어 복구가 가능하다. 그러므로 Region 서버의 설계자체를 조금 더 간단하게 할 수 있는 장점이 있다.
WAL에 recording이 성공해야 write operation 이 성공했다고 간주한다. WAL은 HBase 서버당 한개씩 존재하고 그 서버의 모든 table들이 이를 공유한다.
HFile
HBase는 random access를 지원한다. HDFS 위에서 어떻게 이를 가능하게 할까? 이를 위해서는 HFile를 이해해야한다. 먼저 HFile을 알아보기 전에 Hadoop의 파일기반 자료구조인 SequenceFile과 MapFile에 대한 개념이 있어야한다. 해당 내용은 Hadoop 파일기반 자료구조(SequenceFile, MapFile)에 정리해놓았다.
HBase 버전 0.20 이전까지는 데이터를 저장하는데 Hadoop의 MapFile을 사용했다. MapFile은 SequenceFile의 확장판으로 data 파일과 index 파일을 포함하고 있는 디렉토리이다. MapFile의 데이터는 key를 기준으로 정렬된 key-value 데이터이고 매 구간의 key를 index에 offset과 함께 저장해놓음으로서 index scan만 함으로서 fast lookup을 가능하게 한다.
HBase with MapFile
초기버전의 HBase는 MapFile을 사용했는데 key로는 rowkey, column family, column qualifier, timestamp, type으로 구성했다. value로는 row 내용이 들어갈 것이다.
여기서의 type은 해당 row가 삭제되었는지를 나타내는 flag인데 이는 밑에서 자세히 알아볼 것이다. 위와같이 MapFile을 구성하면 만약 row를 수정하면 어떻게 다음 조회에 수정된 내용을 반환할 수 있을까? 같은 row중 더 큰 timestamp를 가진 row를 반환할 수 있겠다. MapFile에서의 data 파일은 반드시 key로 정렬이 되어있어야 한다. 하지만 HBase에 write하는 데이터는 정렬된 순서로 도착하지 않는다. 이를 해결하기 위해 위에서 보았듯이 HBase는 write command시 MemStore에 데이터를 저장하고 있다가 가득차면 flush 한다. MemStore는 ConcurrentSkipListMap과 동일하므로 이미 key로 정렬되어있다. 이를 MapFile로 flush하고 해당 MapFile은 더이상 수정하지 않는다. 그러므로 데이터를 찾을때에는 모든 MapFile을 대상으로 검색해야한다. 이는 성능에 좋지않으므로 성능을 개선하는 방법을 밑에서 자세히 알아볼 것이다.
HFile version 1
HBase 0.20 버전부터 HBase는 MapFile을 사용하지 않고 직접 구현한 MapFile과 비슷한 HFile 이라는 파일기반 자료구조를 사용한다. HFile은 MapFile과 유사하지만 index를 다른 파일로 분리하지않고 같은파일에서 관리하도록 하며 여러 metadata를 담을 수 있다. HFile 내부에는 data block이 여러개가 존재한다. 여러개의 연속된 data block들이 존재하고 index도 같이 존재한다. 이 data block에는 실제 key-value 데이터를 담고있다. 각 data block의 첫번째 key가 index에 기록된다. data block은 기본설정으로 64KB의 크기를 가진다. 각 HFile의 data block에는 HBase cell 들이 KeyValue 형태로 연속해서 저장되어 있다. 아래는 HFile version 1의 구조이다.
Block index에는 각 entry마다 block의 size, key 정보 등이 들어있다.
HFile에는 위와같이 metadata를 담는 block인 Meta Block과 File Info 가 존재한다. version 1에서는 이 Meta Block을 Bloom Filter 정보를 담는데에 활용하였다. data scan시 해당 data가 이 HFile에 있는지 bloom filter를 활용하면 빠르게 판단할 수 있는데 bloom filter는 false positive가 발생한다. 그래서 HFile이 너무 오래되었는지 확인하기위한 Max SequenceId, Timerage 등을 File Info에 저장해 false positive를 한번 더 필터링한다.
HFile version 2
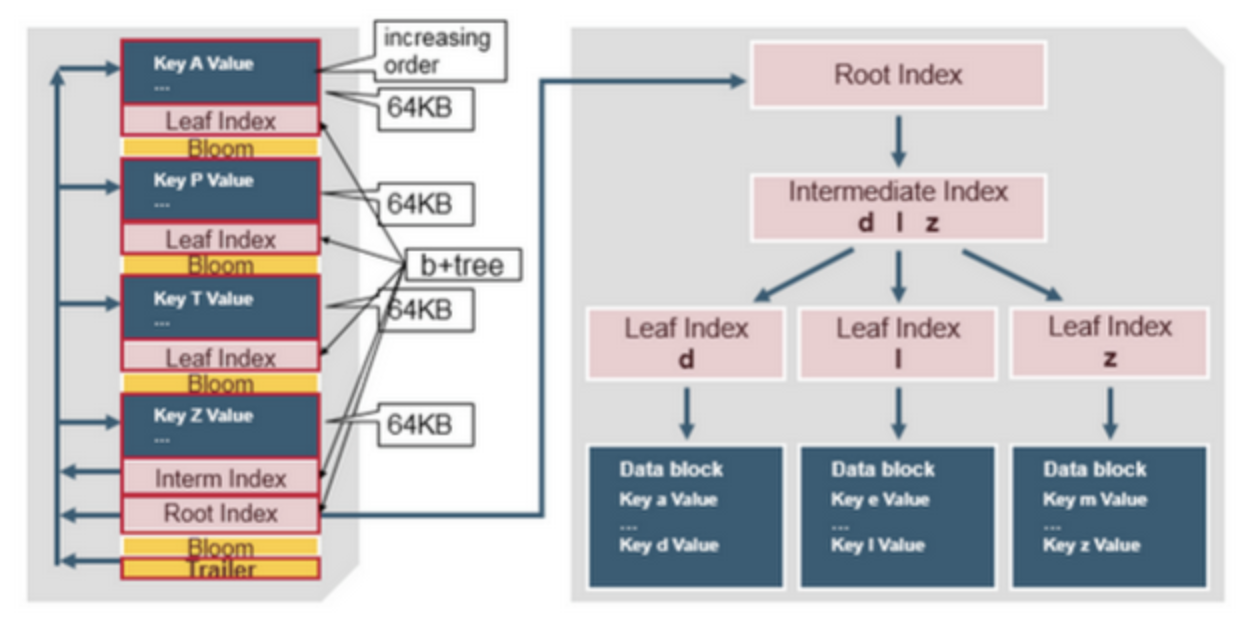
HBase 0.92 버전에서는 많은 데이터가 저장될 때 성능개선을 위해 HFile 형식이 조금 변경되었다. 위의 HFile version 1에서는 데이터를 읽기 위해서는 해당 HFile의 전체 데이터 정보를 담고있는 단일 index와 bloom filter를 메모리에 모두 올려놓아야 했다. 이를 개선하기 위해 HFile version 2 에서는 bloom filter를 block 별로 두고, multi-level index를 사용하도록 개선했다.
HFile version 2 에서는 bloom filter block과 index block을 data block과 나란히 배치한다. bloom filter block과 index block 모두 random read을 최적화하기위한 용도로 사용된다. index block은 index data로 빠르게 검색할 수 있도록 하며, bloom filter block은 해당 data가 있는지 없는지를 빠르게 필터링하는데에 사용된다.
Index block 에는 3가지가 있다. Root Index block, Intermediate Index block, Leaf Index block 이다. Root Index block은 HFile을 읽을때 바로 memory로 올린다. Root Index는 각 entry가 Intermediate Index block을 가리킨다. 그리고 Intermediate Index의 각 entry는 Leaf index block을 가리킨다. 마지막으로 Leaf index block은 실제 data block 을 가리킨다. 이는 b+tree와 매우 유사한 구조이다.
각 index entry에서의 key를 구성하는 것은 크게 두가지 방식이 있다. Rowkey-based index 와 Column-based index 이다. Rowkey-based index 는 HBase 의 built-in 인덱스 방식으로 rowkey 를 기반으로 특정 row를 빠르게 찾도록 도와준다. rowkey-based index 는 key로 rowkey를 포함한다.
Column-based index 는 HBase 의 secondary index 구현에 사용된다. 이는 특정 column qualifier 값의 질의를 빠르게 매칭하는데 사용한다. column-based index 는 index table 이라고 불리는 HBase 의 또다른 테이블에 저장된다. index table 구조는 HBase 의 테이블과 유사하며 동일한 rowkey 와 column 을 사용한다. 하지만 value 는 기존의 테이블의 부분만 가지고있다. 따라서 특정 쿼리에서 column-based index 를 사용해야한다고 판단할때는 index table 을 보고 일치하는 row를 먼저 골라낸다. 그 다음 해당 row를 실제 main table 에서 찾는다. 따라서 특정 column qualifier value를 조회할때에는 column-based index 가 조회가 필요한 row 만 필터링해줄 수 있으므로 성능향상을 가져올 수 있다.
HFile block
HBase 에서 조회를 할때 조회해야하는 row가 포함되어있는 HFile block을 찾는다. 이는 index 에서 rowkey로 검색하여 찾을 수 있다. 그리고 그 HFile block을 rowkey를 활용해 찾으면 이 block 전체를 메모리에 올린다. 이들은 정렬되어있는 key-value 쌍이므로 binary search 로 원하는 row 조회 및 특정 column qualifier 조회를 수행할 수 있다.
Data block에도 header를 포함한다.
header에는 Block Type을 포함하여 해당 block이 data block인지 Index 인지 다른 내용인지를 구별하도록 한다. 또한 이전 block의 offset도 저장하여 빠른 backward seek을 가능하도록 한다.
HBase는 이처럼 데이터를 HFile이라는 큰 파일에 저장한다. 보통 HFile은 몇백 MB 부터 시작해 GB 단위로 커져간다.
HBase read
HBase의 read는 쉽다. 먼저 Get command instance를 통해 읽고싶은 cell을 지정하고 table에 보내면 된다.
위에서는 addColumn() 메서드를 통해 원하는 column을 명시했지만 addFamily() 메서드를 활용하면 해당 column family의 전체 column을 가져올 수도 있다.
HBase는 대부분의 읽기를 millisecond 단위로 제공한다. 보통의 일반적인 방법과 같이 HBase도 빠른 data access를 위해 data를 정렬된 상태로 유지하고 memory에 많이 올려놓는다. 그리고 위에서 설명하였듯이 write는 MemStore에 저장되지만 MemStore는 HFile로 flush되므로 read command를 처리하기 위해서는 HFile과 MemStore에서 적절하게 데이터를 잘 찾아야한다.
HBase는 BlockCache라는 LRU Cache를 내부적으로 사용한다. 이 BlockCache는 JVM heap에 MemStore옆에 위치한다. BlockCache는 HFile에서 자주 접근되는 data들을 캐싱해서 in-memory hit를 하고 disk read를 줄이기 위한 목적이다. 각 column family마다 BlockCache를 가지고있다. HBase를 최적의 성능을 내도록 하기위해서는 BlockCache를 이해하는게 중요하다.
BlockCache
BlockCache의 Block은 HBase에서 disk에서 한번에 읽는 데이터 단위이다. 위의 HFile 에서의 data block이 이것이다. HBase가 데이터를 읽기위해 HFile을 뒤져야할때는 HFile의 index 를 보고 binary search를 통해 key를 포함하고 있는 block의 위치를 알아낸 뒤 그 block(64KB)를 HDFS로 부터 읽어낸다. block size는 column family 별로 다르게 설정될 수 있으며 기본값은 64KB이다. 만약 Application이 HBase에서 random lookup이 많다면 block size를 작게하는게 도움이 될 수 있다. 반면 block size가 작아지면 block의 개수가 많아지므로 index는 조금 더 커질 것이다. sequential lookup이 많다면 block size를 반대로 크게 하는게 도움이 된다.
BlockCache는 기본적으로 enable 된다. 즉 모든 read operation은 그에 연관된 block을 BlockCache에 올릴것이다. BlockCache는 내부적으로 block들의 종류에 따라 evict 정책을 다르게 가져간다. 예를들어 hbase:meta table 내용은 최대한 BlockCache에서 evict 되지 않도록한다. HFile의 index 들도 BlockCache에 올라가는데 자주 사용되지 않는 index들은 evict된다. HFile index들은 multi-layered index로 HBase에서 data를 찾을때 빠르게 찾을 수 있도록 도와준다. 이 말고도 BloomFilter도 활성화되어있다면 BlockCache에 올린다. 기본적인 key-value data 들도 당연히 BlockCache에 올라간다. 같은 데이터를 여러번 접근하는 패턴은 BlockCache의 이득을 최대로 볼 수 있다.
HBase에서 row를 읽을때에는 먼저 MemStore를 확인한다. 그 다음 BlockCache를 확인하고 해당 row가 BlockCache에 올라와있는지 확인한다. 최근에 row가 접근된 적이 있다면 BlockCache에 존재할 확률이 높다. 만약 BlockCache에도 찾지못한다면 그때 관련된 HFile들을 확인한다. 이때에는 disk read가 발생한다. 완전한 row를 찾기위해서는 모든 HFile을 뒤져야한다.
HBase delete
Delete는 HBase의 데이터를 저장하는 방식과 비슷하게 작동한다. 먼저 Delete를 하려면 Delete command의 인스턴스를 생성해야한다. 다음은 rowkey를 명시하여 해당 row를 삭제하는 코드이다.
실제 삭제는 어떻게 진행될까? 실제로 Delete command는 해당 값을 바로 삭제하지 않는다. 대신에 해당 record가 삭제되었다는 마킹만 한다. 이는 HFile을 생각해보면 당연한 설계이다. HFile은 immutable하다. 그러므로 애초에 record를 수정하거나 삭제할 수가 없다. 그러므로 해당 record가 삭제되었다는 새로운 record를 write한다. 이를 tombstone 이라고 한다. 그래서 보통 HBase 에서 삭제한다고 하면 tombstone marking을 했다고 표현한다. 이 tombstone mark는 Get이나 Scan을 할때 해당 record가 결과에 포함되지 않도록 보장한다. 실제 삭제가 되었어야 하는 original 데이터는 계속해서 HFile에 남아있을 수 밖에 없는데, 이런 데이터들은 밑에서 볼 major compaction 단계에서 제거된다.
HBase Compaction
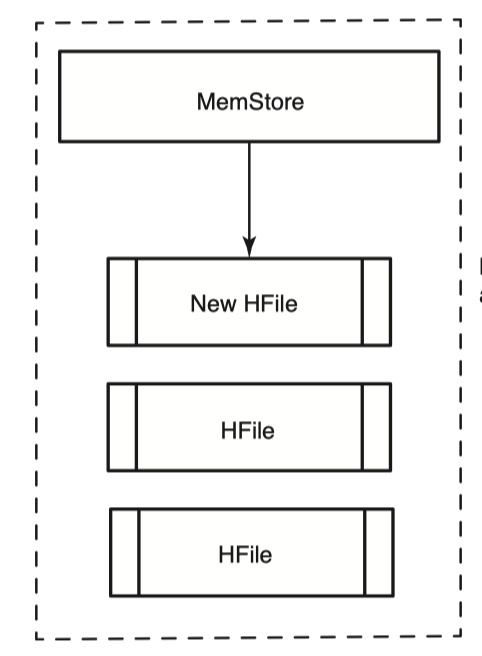
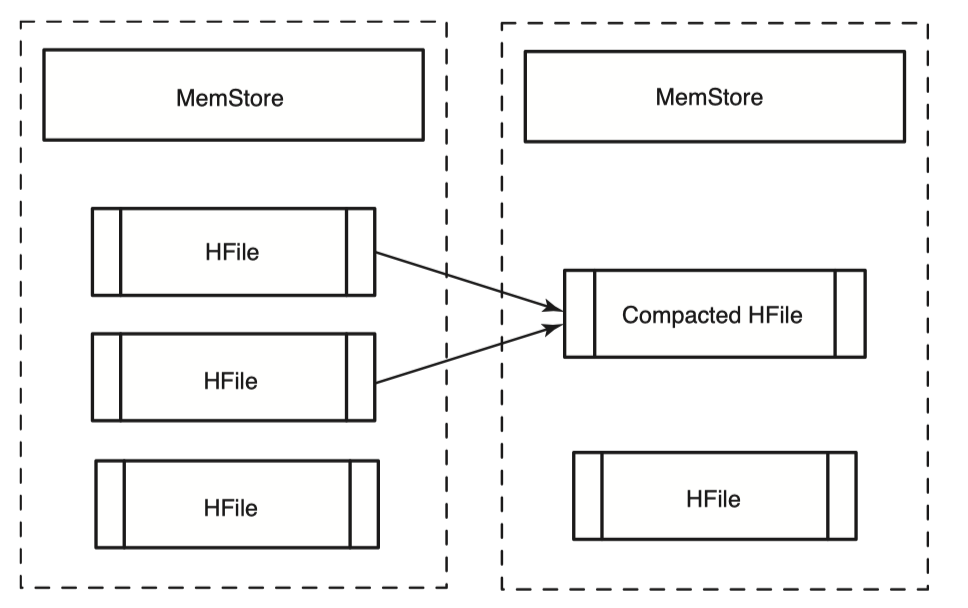
Memstore가 어느정도 크기에 도달하거나 Region 서버가 Memstore에 너무 많은 메모리를 쓰고있다고 판단되면 Memstore는 flush를 하여 새로운 HFile을 만들어낸다고 했다. 매 flush마다 새로운 HFile이 생성되므로, 우리는 Get과 Scan을 수행할때 key를 찾기위해 해당 요청과 관련있는 모든 HFile을 다 뒤져봐야하므로 이는 성능이 좋지않다. 즉 HFile의 개수를 제한하는 것이 성능에 매우 중요한 부분을 차지한다. 이를 극복하기위해 HBase는 HFile의 개수가 특정개수를 넘어갈때 Compaction을 진행하여 여러개의 HFile을 하나의 큰 HFile로 병합한다.
HBase의 compaction에는 2가지 종류가 있다. Minor Compaction과 Major Compaction이다.
Minor Compaction
minor compaction은 간단하다. 작은 HFile 여러개를 하나의 큰 HFile로 합친다. minor compaction 과정은 HBase에 성능저하를 최소한으로 있도록 설계되었기 때문에 minor compaction 대상이되는 HFile 개수는 상한선이 있다. 이 값은 설정값으로 조정이 가능하다. minor compaction은 작은 HFile 들로부터 record를 읽어 이들을 정렬하고 큰 HFile에 새로 write한다. 과정은 다음 그림과 같다.
Major Compaction
major compaction은 column family의 모든 HFile를 대상으로 수행되는 compaction이다. major compaction이 완료되면 해당 column family의 모든 HFile들은 하나의 HFile로 병합된다. 이 major compaction은 비용이 비싸므로 자주 일어나지 않는다. 다만 minor compaction은 빈번하게 일어난다. major compaction 단계에서는 tombstone marker로 표시해둔 record를 완전히 삭제한다. 또한 tombstone marker record 자체도 같이 삭제한다.
왜 minor compaction은 이와같은 deleted mark record를 삭제하지 못할까? 실제로 삭제대상의 record가 있는 HFile과 tombstone marker record가 있는 HFile은 다를 수 있고 삭제대상의 record가 어느 HFile에 있는지 모르기 때문이다. minor compaction은 작은 몇개의 HFile을 대상으로만 진행된다. 그러므로 major compaction에서 이를 담당한다.
HBase data locality
HBase는 HDFS로부터 HFile을 읽을때 어느 node에서 읽을까? 이를 위해서는 먼저 HBase와 HDFS가 같은 cluster에 있는지 확인해야한다. 만약 같은 cluster에 없다면 HFile은 항상 HBase의 Region server와 다른 노드에 있으므로 network 비용이 발생한다. 만약 같은 cluster에 존재한다면 Region Server가 HDFS에 HFile을 쓸 때 HDFS는 가능하면 그 파일을 쓰는 datanode에 replica가 저장될 수 있도록 해준다. 따라서 Region Server에서 HFile 접근시 local disk에 접근하므로 data locality를 보장할 수 있다. 만약 Region Server가 문제가 생겨 새로 서버가 시작되었다고 하더라도 처음에는 다른 HFile을 읽기위해 다른 HDFS datanode로 부터 파일을 읽어오겠지만, 충분한 시간이 지난다면 major compaction이 발생하고 결국 HFile을 새로 다시 쓰기때문에 이 부분에서 다시한번 data locality를 보장할 수 있다.
HBase 분산모드
HBase의 테이블은 row와 column으로 구성되어 있고 수십억개의 row와 수백만 개의 column으로 확장이 가능하다. 각 테이블은 petabyte 단위까지도 증가할 수 있다. 다만 단일머신에서는 이를 서비스하기 힘들다. 어떻게 이를 가능하게 할까?
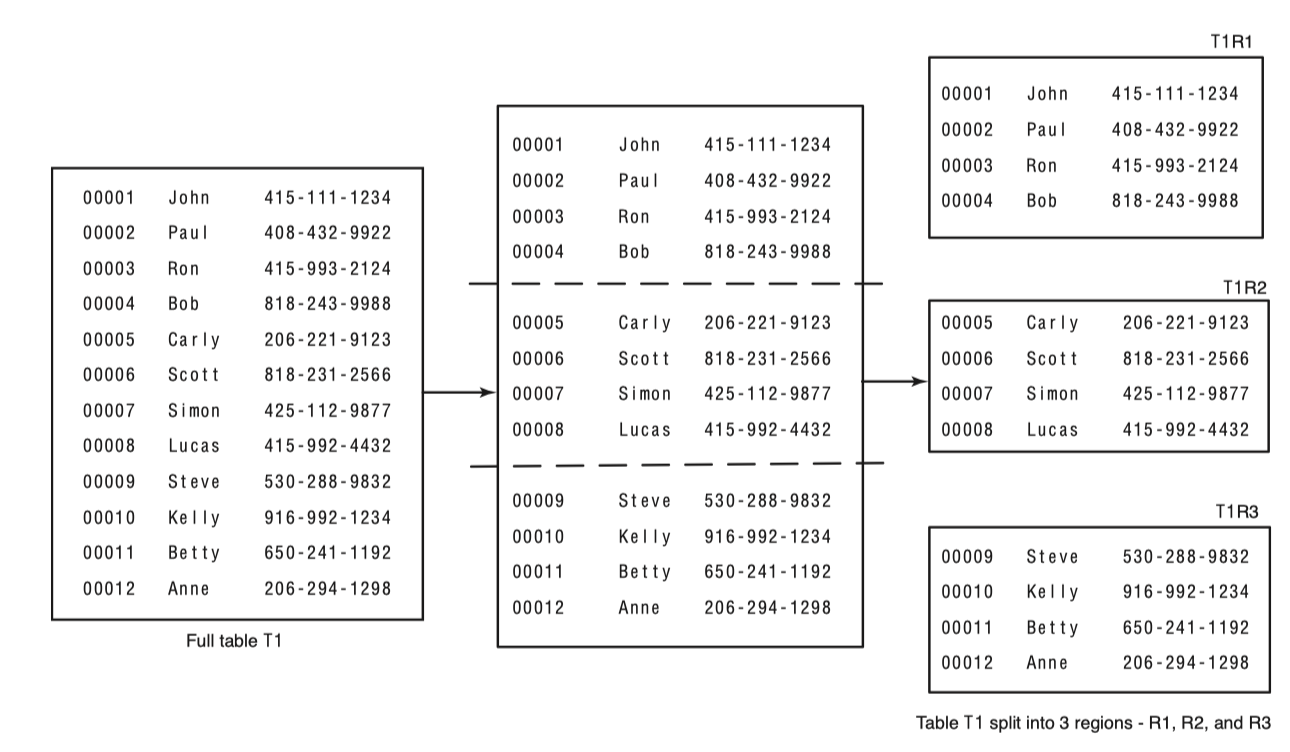
HBase는 table을 작은 단위로 분할시키고 이를 여러 서버에 나누어 서비스한다. 이 작은 단위를 Region 이라고 부른다. 이 Region을 서비스하는 서버를 RegionServer 라고 한다. 일반적으로는 RegionServer 들은 HDFS datanode와 같은 물리적인 서버에 위치해 있다. 꼭 같은 물리서버에 위치해야할 필요는 없지만 locality를 얻기위해 그리고 성능최적화를 위해서는 같은 물리적 서버에 위치하도록 하는게 좋다. RegionServer 들은 HDFS의 입장에서는 HDFS를 사용하는 클라이언트중 하나이다. HMaster라 불리는 process가 region을 할당하고 분배하는 역할을 수행하고 각 RegionServer는 일반적으로는 여러개의 Region을 서비스한다. Region은 table을 rowkey를 기준으로 적절하게 범위를 나누어 할당된다. 다음 그림으로 Region의 분리를 볼 수 있다.
Region이 너무 커지거나 Region이 나누어져야 하는 특정조건을 만족하면 RegionServer는 Region을 다시 작은 크기로 쪼갠다.
client 가 특정 row에 접근하고자 할때는 어느 Region에 있고 이를 어떤 RegionServer가 호스팅하고 있는지 어떻게 알 수 있을까? 이 정보는 .META. 라는 HBase 내의 table이 도움을 준다. 실제 table 이름은 hbase:meta 이며 HBase의 모든 region 정보를 가지고 있다. 그리고 zookeeper가 hbase:meta table의 위치를 저장한다. .META. 테이블은 1개의 region으로만 사용하고 있다.
따라서 client는 특정 row에 접근할때 zookeeper로부터 hbase:meta region을 서비스하는 RegionServer를 알아내고, 이 .META. table 정보를 들고있는 RegionServer에 해당 rowkey를 어떤 region과 RegionServer 에서 제공하고 있는지 질의한다. 그에 대한 RegionServer 정보를 받으면 그 RegionServer로 해당 row의 읽기나 쓰기작업을 진행한다.
현 회사에서 Hadoop을 적극적으로 사용하고 있고 저장소로 HBase를 사용하며 MR(MapReduce)을 다루는 경우가 많기 때문에 Hadoop 관련 내용을 정리하면 좋겠다고 생각했다. 이 글을 읽기 전에 파일시스템 1편 - 하드디스크 를 먼저 읽으면 도움이 될 수 있습니다.
먼저 Hadoop distributed file system을 알아보자.
HDFS
HDFS는 Hadoop Distributed File System 의 약어다. HDFS는 하둡의 대표적인 분산파일시스템이다. 그렇다고 하둡에서 꼭 HDFS를 사용해야하는 것은 아니다. 하둡은 범용 파일시스템을 추구한다. 하둡은 파일시스템의 추상화개념을 가지고있고 HDFS는 그 구현체 중 하나일 뿐이다. 데이터가 단일 디스크의 저장용량을 초과하면 이 데이터들을 쪼개서 여러개의 머신에 저장해야한다. 이렇게 여러개의 머신으로 파일을 저장하고 서로 네트워크로 묶으면 여러머신의 스토리지를 관리할 수 있는데 이를 분산파일시스템이라고 한다.
HDFS는 여러개의 머신으로 구성된 클러스터에서 실행되고 대용량 파일을 다룰 수 있도록 설계된 파일시스템이다. HDFS는 petabyte단위의 파일을 다룰 수 있고 하드웨어는 항상 장애가 날 수 있는데 노드장애가 발생하더라도 대형 클러스터에서 문제없이 실행되도록 설계되었다.
HDFS는 기본적으로 빠른 응답시간을 요구하는 애플리케이션에는 맞지않다. 설계자체가 높은 데이터 처리량을 제공을 목표로 하기 때문이다. 빠른 응답시간을 원하면 HBase가 선택지가 될 수 있겠다. 그리고 HDFS는 파일을 생성하거나 파일 끝에 append하는 것은 가능하지만 파일 중간에 내용을 update하는 것은 불가능하다. 한번의 쓰기작업 그리고 여러번 읽는 방식이 가장 효율적인 방식이도록 설계되었기 때문에 데이터를 수정하려면 현재 데이터를 삭제후 수정한 데이터를 새로 생성해야 한다.
HDFS Block
여기서 말하는 block은 흔히 파일시스템에서 말하는 block을 말한다. 보통 우리가 아는 단일디스크에서의 파일시스템에서 사용하는 block는 4KB이고, 디스크 자체는 기본적으로 512KB의 sector size를 가진다. 이와같이 HDFS도 block 개념이 있는데 HDFS block은 size가 굉장히 크다. HDFS block size는 기본적으로 128MB이며 보통은 이것보다는 큰 block size를 사용한다.
HDFS block이 큰 이유는 기본적으로 탐색비용(disk에서의 seek time + rotational delay)을 줄이기 위함이다. (SSD에서도 sequential read가 random read 보다 빠르다) Disk seek 비용은 상당히 비싸다. Hadoop은 전체 dataset을 탐색하도록 설계되었기 때문에 큰 block size로 sequential read를 통해 성능을 크게 개선할 수 있다. 예를들어 position time(seek time + rotational delay)가 10ms 이고, disk 전송률이 100MB/s 일때 position time을 전송시간의 1%로 만들고 싶다면 block size를 100MB로 잡으면된다.(position time 10ms + 100MB 전송에 1초가 걸리므로)
또 만약에 block size가 작으면 파일에 대한 block의 개수자체도 많아질텐데 뒤에 보면 알겠지만 HDFS는 파일시스템 metadata를 메모리에서 관리한다. 그러면 모든 block에 대해 metadata를 들고 있어야 하는데 block 개수자체가 많아지므로 metadata가 너무 커지는 문제가 있다. 결국 block이 너무 많으면 오버헤드가 발생하고 네트워크 트래픽이 증가하는 문제가 발생할 수 있다. HDFS에서의 파일은 우리가 단일디스크 파일시스템에서 파일을 저장할 때처럼 block size별로 chunk되어 저장된다. 다만 HDFS는 데이터가 block size보다 작을경우, 해당 block(128MB)을 모두 차지하지는 않는다(기본적인 단일디스크 파일시스템에서는 데이터가 4KB 보다 작아도 4KB block을 모두 차지한다). 그러므로 파일크기가 block size보다 작다고 공간이 버려지지는 않는다.
HDFS에도 block 개념이 있기때문에 여러가지 이점이 있는데 먼저 단일디스크에 있는 파일시스템에 다 담지 못하는 크기의 파일도 여러 block으로 나누어 여러 디스크에 저장할 수 있다. 그리고 block 단위의 추상화가 들어가면 스토리지의 subsystem을 단순화할 수 있고 metadata 관리가 편하다. 또 block은 fault tolerance와 availability를 제공하기 위한 replication을 구현하는데에 적합하다. block 마다 replicaion factor 개수만큼 여러머신에 중복저장하고 특정 노드에서 block을 읽을 수 없다면 다른 노드를 사용하게 할 수있다.
Namenode And Datanode
HDFS cluster는 master인 네임노드와 worker인 데이터노드로 구성되어 있다. 네임노드는 파일시스템 트리, 그리고 그 트리에 포함된 모든 파일, 디렉터리에 대한 metadata를 유지한다. 파일시스템에서 inode를 네임노드에서 관리하고 있다고 이해하면 좋겠다. 그리고 이 내용은 namespace image와 edit log라는 두 종류의 파일로 local disk에 영구히 저장된다. 네임노드는 모든 HDFS block이 어느 데이터노드에 있는지 모두 알고있다. 하지만 이 정보는 local disk에 영속 저장하지는 않고 시스템 시작시 데이터노드로 부터 받아서 재구성한다. 따라서 네임노드를 다른 것으로 교체할 때 전체 데이터노드에서 충분한 block report를 받아 안전모드를 벗어날때까지 요청을 처리할 수 없는데 이 시간이 30분이상 걸리기도 한다.
사용자가 직접 네임노드, 데이터노드와 통신해야 하는것은 아니고 이 모든 것을 HDFS client가 대신해서 이들에게 접근한다. 데이터노드는 HDFS client나 네임노드의 요청이 있을때 block을 저장하고 탐색하며, 주기적으로 저장하고 있는 block list들을 네임노드에 보고한다. 또 네임노드는 모든 파일과 각 block의 참조정보를 다 메모리에 들고있다. 그래서 대형 cluster에서는 메모리가 걸림돌이 되는데 이부분은 HBase Federation을 적용하여 해결할 수 있다. 이는 네임노드를 여러개두고 각 네임노드가 특정 namespace를 담당하도록 하는 것이다. 예를들어 어떤 네임노드는 /user을 관리하고 어떤 네임노드는 /bar를 관리할 수 있다. 그러면 특정 네임노드가 장애가 나도 다른 namespace의 가용성에는 영향을 주지 않는 장점도 있다. HDFS는 네임노드가 정말 중요한데 네임노드가 장애면 시스템의 어떤 파일도 찾을 수 없다. 모든 block 정보를 이용해 네임노드가 파일을 재구성하기 때문이다. 그래서 네임노드의 장애극복은 필수적이며, Hadoop은 이를위해 2.x 부터 HDFS HA를 지원한다.
HA는 보조 네임노드를 운영한다. 네임노드를 Active-StandBy 구조로 한 쌍으로 구성하여 Active 네임노드에 장애가 발생할 경우 StandBy 네임노드가 이를 이어받는 방식이다.
File read
클라이언트가 HDFS의 파일을 읽을때 내부적으로 어떤 일이 일어나는지 살펴보자.
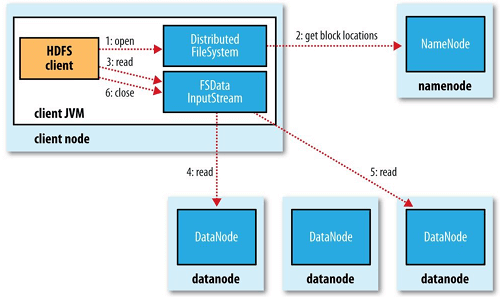
먼저 클라이언트는 hadoop에서 제공하는 FileSystem 객체의 open()을 호출하여 원하는 파일을 열어야한다. 그러면 해당 파일의 첫번째 block이 어디있는지 파악하기 위해 RPC로 네임노드를 호출한다. 그러면 네임노드는 block 별로 해당 block의 복제본을 가진 데이터노드의 주소를 반환한다. 이때 데이터노드의 순서는 cluster의 network topology에 따라 클라이언트에 가장 가까운순으로 정렬되어 반환된다. 예를들어 클라이언트 자체가 데이터노드고 해당 block의 복제본을 본인이 가지고 있으면 첫번째 데이터노드는 로컬이 될 것이다.
block 위치정보를 반환받으면 이 정보를 기반으로 데이터를 읽을 수 있도록 FSDataInputStream을 반환한다. 이는 스트림으로 클라이언트는 read 메서드를 호출하면된다. 그때 내부적으로 첫번째 데이터노드와 연결해 데이터를 전송받는다. 만약 block의 끝에 도달했으면 다음 block의 데이터노드와 연결해 데이터를 전송받는다. 이 과정은 내부적으로 일어나며 클라이언트는 스트림을 읽는것처럼 보인다.
만약 데이터노드와의 통신에 문제가 생기면 해당 block을 저장하고 있는 다음 데이터노드와 연결을 시도하고, 문제가 생긴 데이터노드는 네임노드에 report한다. 전반적인 읽기는 클라이언트가 데이터노드에 직접 접근하여 데이터를 읽어오고, 네임노드가 각 block의 데이터노드를 적절하게 알려준다. 이런 과정을 통해 File 읽기에 대한 트래픽은 모든 데이터노드에 고르게 분산된다. 네임노드는 모든 클라이언트의 요청을 처리해야하지만 메타데이터를 메모리에 저장하여 memory read로 끝나기때문에 많은 클라이언트의 요청을 동시에 처리할 수 있다.
File write
클라이언트가 HDFS의 파일을 쓰게될때 어떤 일이 일어나는지 살펴보자.
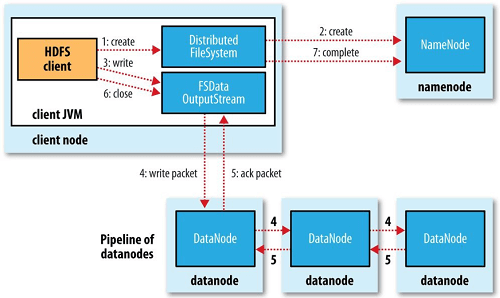
클라이언트는 DistributedFileSystem의 create() 메서드를 호출하여 파일을 생성한다. 그러면 네임노드에 RPC를 보내는데 이때는 파일생성권한이 적절하게 있는지 동일파일이 존재하는지 등 검사를 진행한다. 검사가 통과되면 새로운 파일의 레코드를 만들어 저장하고 반환한다. 이때 block 정보는 반환하지 않는다. 클라이언트는 file read와 마찬가지로 FSDataOutputStream을 반환받고 이를 스트림으로 write할 수 있다. 다만 쓸때는 read 과정과 조금 다르다.
클라이언트가 파일에 데이터를 쓸때에는 각 데이터를 패킷으로 나누어 분리하고 클라이언트의 내부 queue인 data queue라고 불리는 queue에 해당 패킷들을 쌓는다. 그러면 DataStreamer가 이 패킷들을 처리한다. 먼저 block을 어느 데이터노드에 써야하는지 모르므로, 네임노드로부터 복제본을 저장할 데이터노드 목록을 요청하고 반환받는다. 다만 이 데이터노드들은 pipeline을 형성하는데 replication factor가 3이라면 세개의 노드가 pipeline에 속한다. DataStreamer는 첫번째 데이터노드에 먼저 패킷들을 전송한다. 첫번째 데이터노드는 이를 저장하고 나서 이를 다음 pipeline의 데이터노드로 보낸다. 이어서 두번째 데이터노드는 다시 패킷을 저장하고 다음 pipeline의 데이터노드로 저장한다. 그림을 보면 이와같은 내용을 설명하고 있다.
클라이언트는 내부 패킷을 저장하는 ack queue를 들고있어 각 데이터노드로 부터 ack 응답을 전부 받으면 해당 패킷이 queue에서 삭제된다. 만약 데이터노드의 쓰기에 문제가 있다면 ack를 받지못한다. 그러면 장애복구작업이 시작되는데 ack queue에 있는 패킷들이 다시 data queue에 들어가서 재시도된다.
즉 file write는 비동기적으로 pipeline을 통해 데이터노드에 써주게되는데 dfs.namenode.replication.min에 설정된 개수의 데이터노드에만 block 저장이 성공하면 write은 성공한 것으로 반환된다. 기본값은 1 이다. 그리고 dfs.replication 값인 replication factor에 도달할때까지 클러스터에 걸쳐 복제가 비동기적으로 수행된다. replication factor의 기본값은 3이다.
클라이언트가 file write을 다했을때는 close() 메서드를 호출한다. 그러면 클라이언트는 데이터노드 pipeline으로 남아있는 모든 패킷을 flush하고 ack를 기다린다. 그 이후에는 네임노드에 file write이 완료되었음을 알린다. dfs.namenode.replication.min 만큼의 block이 복제가 완료되었으면 성공을 반환한다.
복제본 배치
네임노드는 복제본을 저장할 데이터노드를 어떻게 선택할까? 노드간의 쓰기 대역폭을 줄이기위해 단일노드에 모두 복제본을 배치하면 복제의 의미가 없다. 해당 노드가 장애시 data loss가 일어난다.
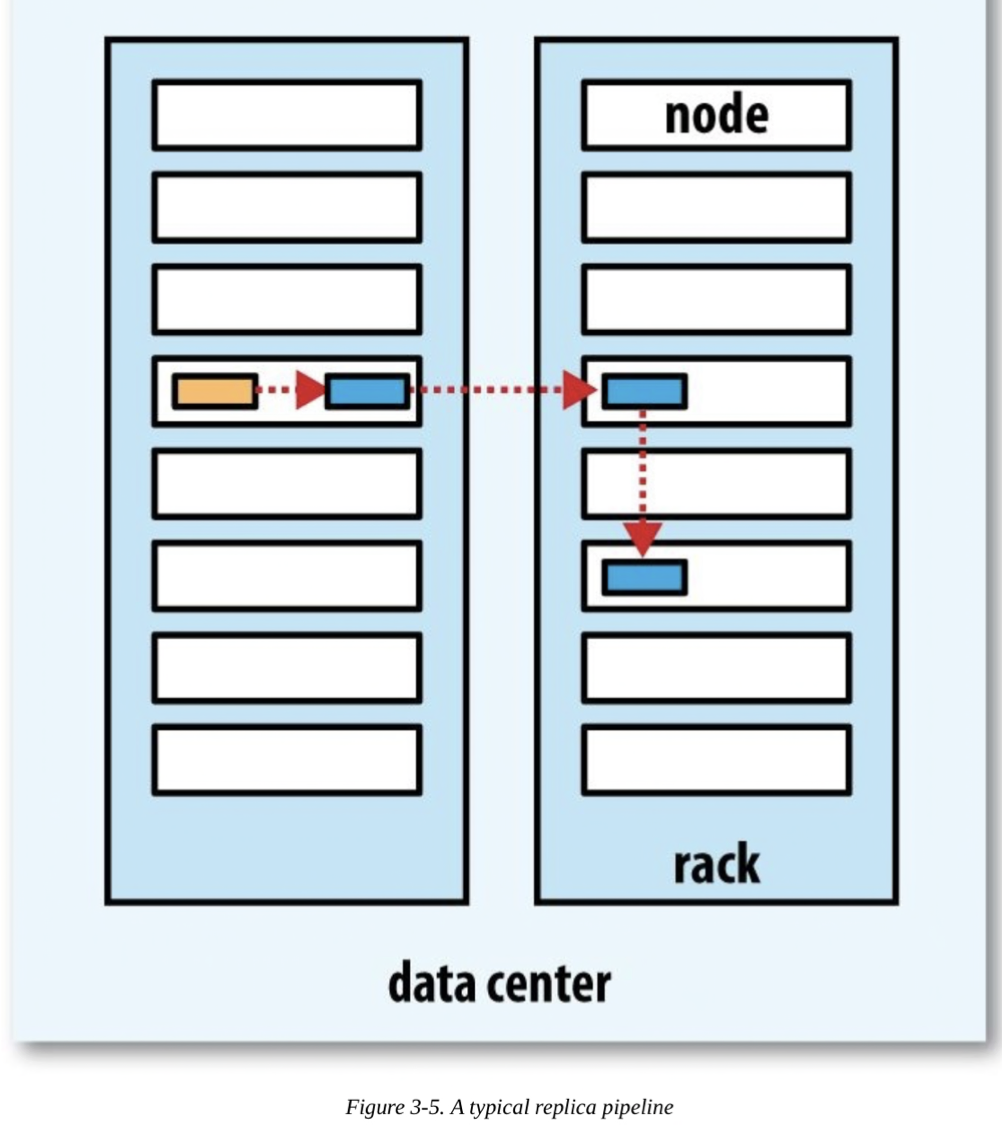
하둡에서는 첫번째 복제본은 클라이언트와 같은 노드에 배치한다. 그런데 클라이언트가 cluster 내부의 노드가 아니라면 무작위로 노드를 선택한다. 이 과정에서 노드들의 파일개수나 해당 노드의 자원상황을 고려한다. 두번째 복제본은 첫번째 복제본을 저장한 노드와 다른 랙에서 노드를 무작위로 선택한다. 세번째 복제본은 두번째 복제본이 저장되는 랙과 동일한 랙에서 다른 노드를 선택한다. 그 이상의 replication factor를 가졌다면 다음 노드들은 무작위로 선택한다.
하둡은 block을 두개의 랙에 저장함으로서 신뢰성을 가지고, 쓰기 대역폭은 하나 혹은 두개의 네트워크 스위치만 통하도록 설계되었다. 읽기 성능을 위해서도 두개의 랙중 가까운 것을 선택하도록 한다. 그리고 전반적인 cluster의 block 분산의 균형을 적절하게 맞춘다.
일관성 모델
일관성 모델은 coherence model 로 부른다. 이는 파일에 대한 read, write에 대해 visibility 가 어떻게 되는지 설명한다. HDFS에서 파일을 생성하면 HDFS namespace에서 파일의 존재를 확인할 수 있다.
일단 file의 데이터가 한 개의 block 넘게 기록이 되면, 그 file의 첫번째 block은 reader들이 볼 수 있다. 다만, 현재 쓰여지고 있는 block은 다른 reader 들에게 보이지 않을 수 있다.
HDFS는 모든 buffer들이 데이터노드들에 강제로 flush 할 수 있는 hflush() 라는 메서드를 제공한다. hflush()가 성공하면, HDFS는 write pipeline에 속한 모든 데이터노드들에 file write에 대한 요청이 도달했음을 보장해준다. 그러므로 모든 다른 reader들이 이를 읽을 수 있다.
한가지 주의해야 할 점은 hflush()는 데이터노드가 해당 파일을 disk에 썼음을 보장하지 않는다. 오직 데이터노드의 메모리에 썼음을 보장한다. 따라서 hflush()를 호출했음에도 data center 장애가 일어나면 데이터 유실이 일어날 수 있다. 데이터노드에서의 disk write도 보장하고 싶다면 hsync()를 호출해야 한다.
hsync()는 POSIX의 fsync()와 같다. 파일시스템 편에서의 buffer cache를 flush 하기 위한 fsync()를 기억하라.
이런 HDFS의 일관성 모델을 보고 애플리케이션의 디자인을 어떻게 해야할지 결정해야한다. hflush()나 hsync() 없이는 block의 저장을 보장할 수 없다. 하지만 이에도 tradeoff가 있다. hflush()는 비싼작업은 아니지만 그래도 오버헤드가 존재하고 hsync()는 비용이 더 비싸다. 애플리케이션에서 적절하게 일관성 모델을 정하고 그에 맞게 HDFS의 hflush와 hsync를 활용하여 성능과 데이터 신뢰성을 잘 결정해야 한다.
결론부터 말하자면 2022년 3월 3일 코로나19 양성판정을 받았다. 계속 언제, 어디서부터 감염되었는지 생각해봤는데 아무리 생각해도 잘 모르겠다. 간 곳이라고는 집앞에 있는 스터디카페밖에 없었고 그 스터디카페는 정말 큼지막해서 사람간의 동선도 거의 겹치지 않는다.
확진받은 날인 3월 3일 아침에 일어났을때 평소보다 목이 조금 잠겨있었다. 이거 코로나인가..? 라고 생각은 들지 않았을만큼 아주 미세한 차이였고 그래도 뭔가 찝찝해서 아침에 집에 있는
키트를 사용하여 진단해본 결과 음성이 나왔다. 그래서 내가 확진되었다는 생각은 전혀 하지 못했지만, 오후에 갑자기 엄마가 확진판정을 받았다고 했다. 그 말을 듣자마자 나도 바로 PCR검사를 받으러 갔고 결과는 다음과 같다.
흑흑흑.. 처음에 카톡으로 알림이 왔을때 나한테 잘못온줄 알았다. 아니 내가 걸린다고? 심지어 당일 아침에 자가진단키트로는 음성이 나왔어서 더 예상을 못했던 것 같다.
기가막히게 확진을 받은 다음날 새벽부터 오한이왔고 심한 목감기처럼 통증이 심해졌다. 회사에도 현 상황을 공유해드리고 아픈건 맞지만 어차피 재택근무이고 업무하는데에는 무리가 없다는 개인적인 판단하에 계속해서 재택근무를 하기로 결정했다. 감사하게도 회사에서 상비약을 마련해서 바로 퀵으로 보내주셨고 정말 많은 도움이 되었다. 양도 굉장히 많아서 우리가족 다같이 나눠먹었다.
이제 자가격리가 3일 남았는데 얼른 끝났으면 좋겠다… 공부해야될게 산더미인데 스터디카페를 못간다니..
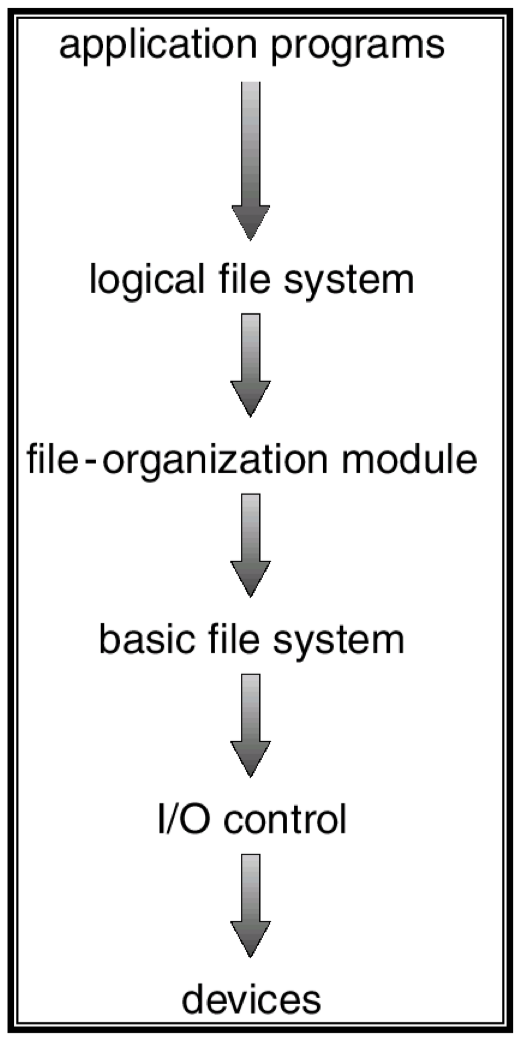
파일시스템은 계층화가 잘되어있다. 일반적으로 파일시스템은 여러 개의 layer로 나뉘어져 구성된다.
위의 그림에서 각 layer를 간단하게 살펴보자.
Logical file system
여기서는 파일시스템의 메타데이터를 관리한다.
File-organization module
이 layer에서는 파일의 logical block 주소를 physical block 주소로 변환해준다. 예를들어 하드디스크를 매체로 사용하게되면 sector 주소로 접근해야 하는데 이를 위한 변환을 진행한다.
Basic file system
여기서는 위에서 변환된 physical block 주소를 가지고 읽고 쓰도록 command를 날린다. 여기서 DMA를 사용한다.
I/O control
이는 device driver다. device driver가 하드웨어에 맞게 명령을 전달한다.
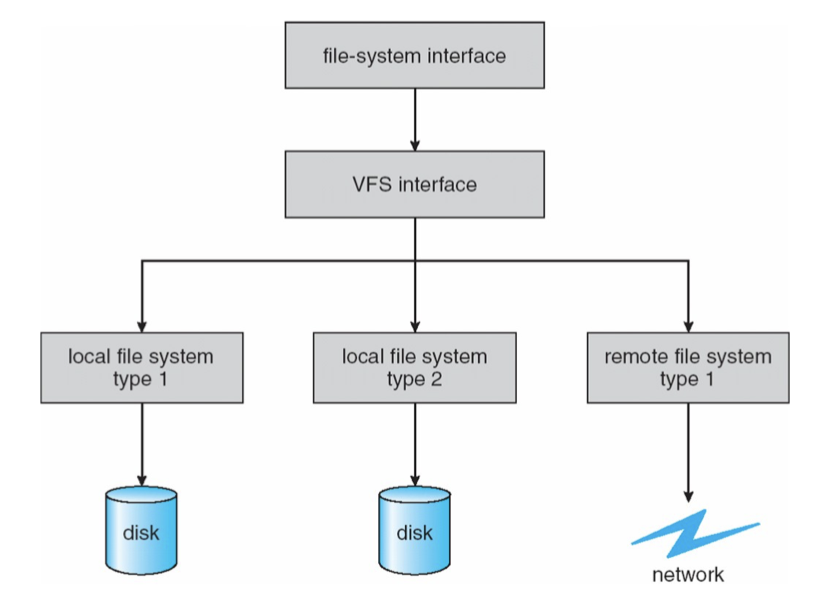
Virtual File System
파일시스템은 어쩔 수 없이 사용하는 매체에 의존성이 있다. 그래서 파일시스템은 종류가 여러가지가 있을 수 있다. 예를들어 요즘은 잘 안쓰지만 CD-ROM이 있을 수 있고 USB, SSD, Disk 그리고 파일이 현재 호스트가 아닌 다른 네트워크의 호스트에 있을 수도 있다. Linux kernel 에서는 여러가지 파일시스템을 지원한다. VFS는 다양한 logical file system 들을 추상화한다. 따라서 VFS를 통해 실제로 시스템에는 여러개의 다른 파일시스템이 사용되더라도 마치 1개의 파일시스템만 사용하는 것처럼 프로프래밍 할 수 있다. 이는 OOP의 개념과 같은데 특정 파일에 대해 read/write syscall 이 호출되면 해당 파일이 속한 파일시스템 구현체의 read/write 가 호출되는 방식이다.
File System data structure
파일시스템에서 사용하는 자료구조를 알아보면서 파일시스템에 대한 이해를 높여보자. On-disk 그리고 In-memory 에서 사용하는 자료구조들을 볼 것이다.
On-disk data structure
On-disk 자료구조들은 이미 이전 포스트인 파일시스템 디자인-1 에서 vsfs(very simple file system)에서 살펴봤던 내용들이 많다.
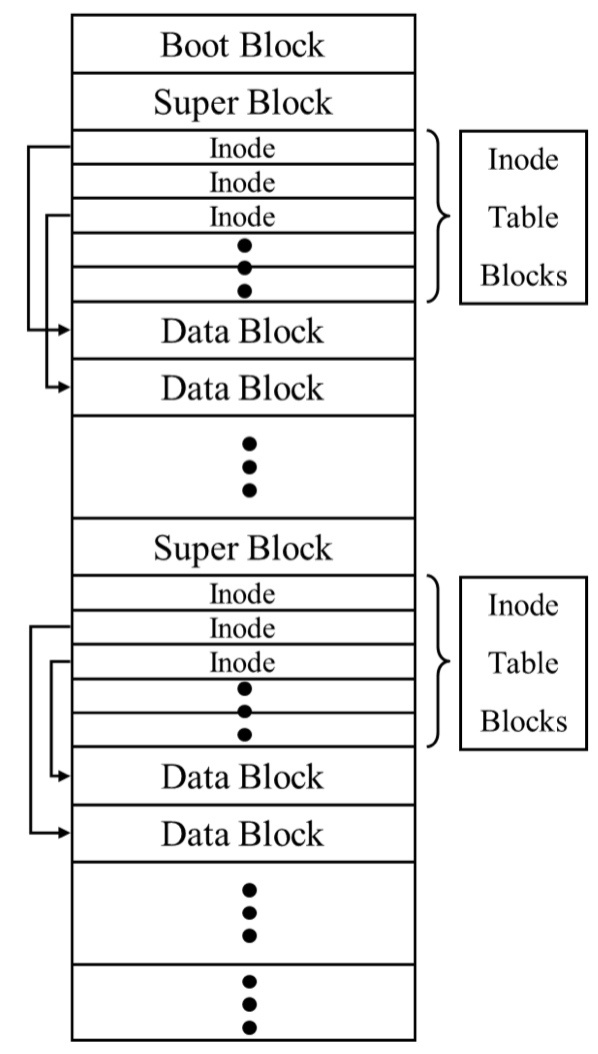
Boot block 첫번째 block으로 운영체제가 booting 하기위해 필요한 정보를 담아놓는 block이다. 하지만 이를 안만드는 경우도 많다.
Super block 파일시스템 관련 정보들이 어디에 저장되어있는지에 대한 metadata를 저장한다. 예를들어 inode table은 어디서 시작인지, data block은 어디 block부터 시작하는지, root directory에 대한 inode 번호 등을 저장한다. Super block은 보통은 각 disk partition의 첫번째 block 에 할당하고 이 super block 이 손상되면 파일시스템의 복구가 힘들기때문에 보통 중복해서 super block을 저장한다. 그리고 이 super block은 in-memory data structure로 메모리에 올려 캐싱한다.
File control block FCB(file control block)은 결국 inode와 같다. inode 자체도 disk에 저장이 필요하다.
다음의 disk structure layout를 살펴보자.
여기서 각 inode table을 여러개로 나누어 저장한 이유는 data block과 inode가 가까우면 성능을 높일 수 있기때문에 조금씩 inode 들을 나누어 설계했다. 다만 이런 내용들은 전적으로 파일시스템 구현에 달라진다. 결국 여기서의 그림을 보면 파일 접근을 위해서 super block, inode, data block 에 대한 접근으로 파일 하나의 접근에 대해 3번의 disk access가 필요하다.
In-memory data structure
보통 파일시스템에서의 in-memory data structure 들은 거의 caching을 통한 성능향상 그리고 파일시스템 관리가 목표이다.
Dentry 이는 directory cache 이다. directory 접근을 위해 on-disk 의 super block 그리고 root directory 의 inode 부터 접근해서 dentry 라는 directory cache를 만든다. dentry로 파일접근시 해당 파일의 inode를 알기위해 여러번 disk 에 접근할 필요가 없이 memory 에서 처리할 수 있다.
open file table 이는 예전에 살펴본 내용으로 system-wide open file table 그리고 per process open file table 이 있는데 각각 open 한 file을 관리한다. per-process open file table 에서 각 index 번호가 file descriptor 가 된다.
Buffer cache 최근에 사용한 data block 을 memory 에 캐싱한다.
Buffer Cache
Buffer cache는 조금 더 자세히 살펴보겠다. Buffer cache는 파일의 메타데이터가 아닌 data block 자체를 메모리에 올려둔다. 보통 같은 data block을 다시 접근해야 하는 경우가 많기때문에 이를 캐싱해두면 다시 disk를 조회하지 않아도된다. 다만 buffer cache는 완전한 software로 구현된다. 이 말은 virtual memory의 주소변환을 위해 TLB 같은 하드웨어를 도입하는게 아닌 순수한 software 레벨에서 구현한 캐시라는 의미이다. Buffer cache는 보통 물리메모리의 1 ~ 10% 정도로 할당하고 이는 kernel parameter로 수정이 가능하다. Buffer cache 도 공간이 한정되므로 교체알고리즘을 사용한다. 보통 disk access 에는 locality가 나타나기 때문에 LRU 방식을 사용한다. 다만 DBMS 나 multimedia application은 LRU 로 이득을 볼 수 없는 경우가 대부분이기 때문에 이들은 buffer cache를 거치지 않고 바로 disk 에 접근할 수 있는 flag를 사용해서 buffer cache를 거치지 않도록 프로그래밍 한다.
Read syscall 과 Write syscall 각각의 동작방식을 buffer cache 의 관점에서 살펴보자.
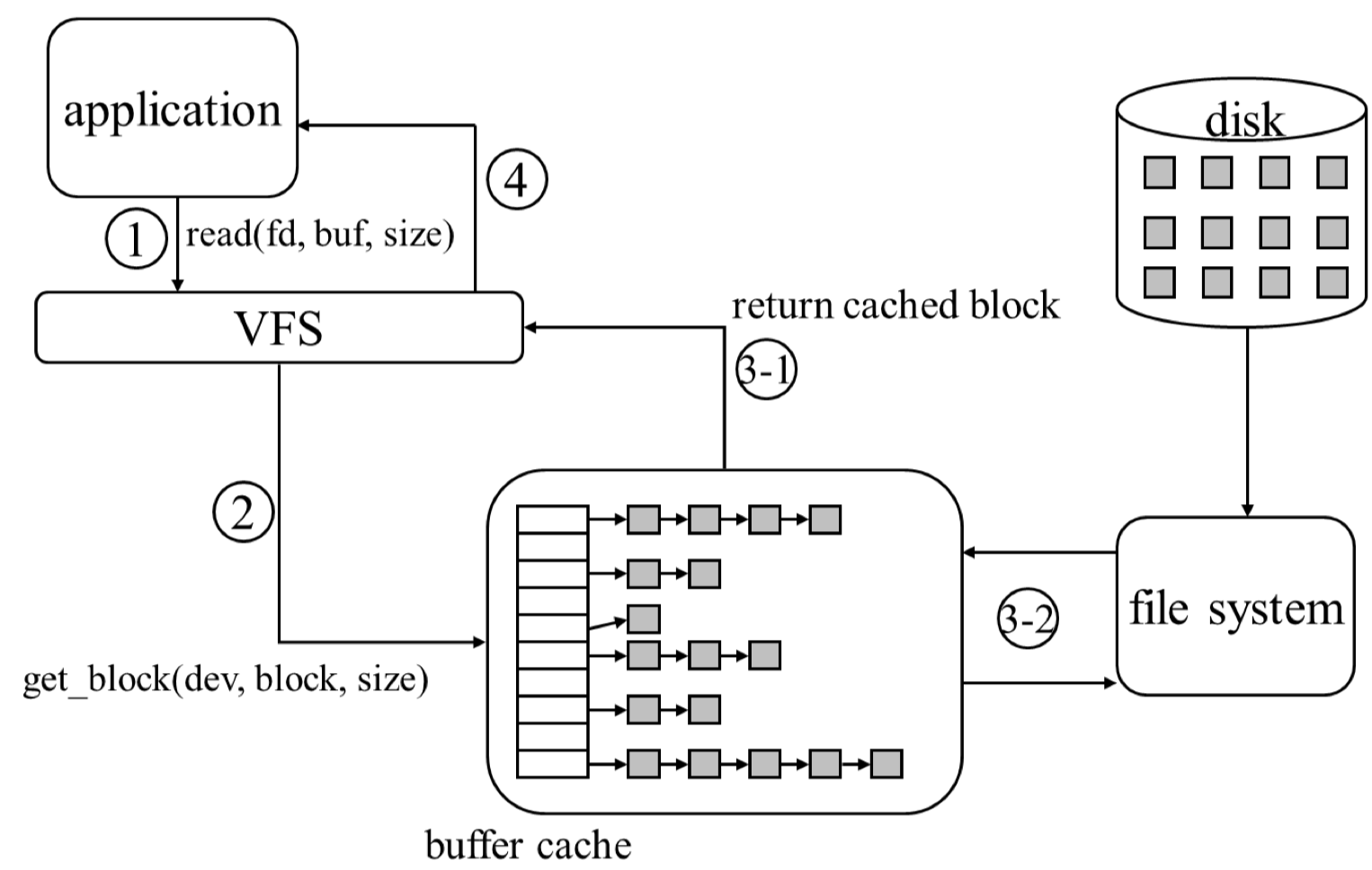
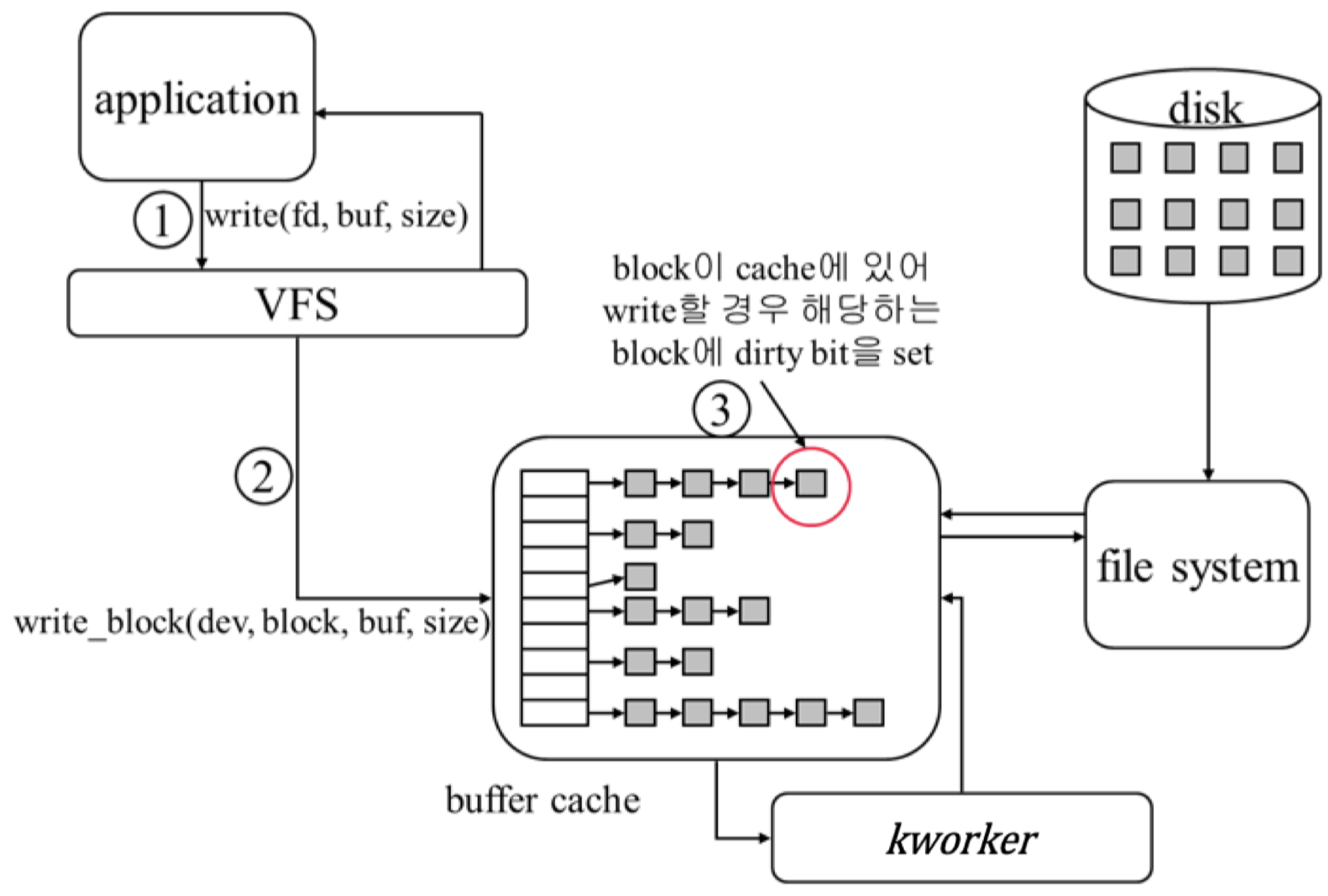
Read syscall
먼저 read(fd, buf, size) syscall 을 호출한다. read syscall 의 두번째 인자인 buf 는 사용자의 buffer를 의미한다. 그다음 VFS에서는 file descriptor를 보고 file이 있는 device를 알아낸 후 logical block number 를 physical block number 로 변환한다. buffer cache 쪽에 해당 block이 있는지 확인을 하고 block 이 없다면 파일시스템에서 가져와야한다. 만약 buffer cache에 이미 cache된 block이 있으면 VFS에 반환한다. cache된 block이 없다면 파일시스템에 block을 요청하고 이 read 를 요청한 프로세스는 sleep 한다. 즉, context switching 이 일어난다. I/O가 필요하기 때문이다. 나중에 disk에서 block을 읽어오면 interrupt 가 발생하고 그 block 을 다시 caching 해주고 block 을 반환한다. VFS에 반환할때는 application의 buf에 block들을 copy해주고 읽어온 byte 수를 반환한다.
만약 read 를 하더라도 buffer cache 에 대상 block 이 존재하여 cache hit 이 된다면, 해당 프로세스는 sleep 하지 않는다. 그리고 buffer cache 쪽을 보게되면 hash table 구조로 구현되어 있고 value로는 linked list 로 각 cache 되어있는 data block 들이 있는 것을 확인할 수 있다. hash 의 key로는 보통은 block number 를 사용한다고 한다.
Write syscall
먼저 write(fd, buf, size) syscall 을 호출한다. VFS에서 device 및 block number로 변환하여 buffer cache에 해당 block이 이미 있는지 확인한다. 만약 write 하려는 block 이 buffer cache에 없다면 먼저 파일시스템에서 읽어오도록 요청한다. 이 과정에서도 write를 요청한 프로세스는 sleep 한다. 파일시스템에서 읽어왔으면 다시 write를 시도하면 해당 block이 buffer cache 에 존재하므로 이 경우에는 해당 buffer cache의 data block에 직접 write를 수행하고(in-memory) 해당 block이 disk에 있는 block과 일치하지 않는다는 표시를 하기위해 dirty bit를 체크한다. 만약 처음부터 buffer cache에 write 시도시 해당 block 이 buffer cache에 있었다면 바로 그 block에 write 하고 반환한다.
이런 방식이면 buffer cache와 disk 의 sync가 깨지게 되는데 이는 다른 worker 스레드가 주기적으로 dirty bit가 체크된 data block 들을 disk에 sync 시켜준다.
kworker
이 kworker 라는 kernel thread가 buffer cache와 disk block 간의 동기화를 수행한다. 예를들어 data block은 30초, metadata는 5초마다 동기화를 시킬수도 있다. 다만 이런 구현은 실제 OS 구현마다 다르며 파일시스템 구현마다도 다르다. 다만 이런 방식이면 순간적으로 머신이 꺼지거나 할때 동기화가 되지 않은 부분은 유실될 수 있다. 즉 write를 하더라도 그 내용이 disk에 반영된다는 보장이 없다. 이를 위해 저널링 파일시스템 같은 대안을 사용한다. Application 에서 fsync system call을 사용하면 강제적으로 buffer cache의 내용을 disk에 반영한다. DBMS도 구현마다 다르지만 매번의 update 마다 fsync 를 수행하지는 않는다. DBMS에서는 이를 write ahead log 과 transaction을 이용해 해결한다.
Memory-Mapped File(mmap)
mmap은 파일을 프로세스의 address space 한 부분으로 mapping 한다. 파일을 프로세스의 memory space 에 그냥 가져다가 붙힌다고 생각하면 쉽다. 이렇게 되면 단순히 memory access instruction 을 통해 파일에 대한 read, write을 할 수 있다. kernel은 이런 memory access instruction 을 적절하게 read, write로 변환하여 수행해준다. mmap 함수는 다음과 같다.
void* mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset)
start는 단지 이 주소를 사용했으면 좋겠다는 의미로 0을 보통 넣는다. 그리고 offset 부터의 length 만큼의 바이트를 start 주소로 매핑하기를 원한다는 의미이다. fd는 파일에 대한 file descriptor 로 이미 존재하는 파일에 대한 file descriptor 를 넘겨 이를 읽거나 수정할 수도 있고, 새로운 파일을 O_CREAT flag 와 함께 open 하여 이 file descriptor 를 넘겨 새로운 파일을 쓸 수도 있다.
유저는 파일에 대한 I/O 를 단지 memset, memcpy 같은 memory access 로 단순화 할 수 있다. 그리고 여러개의 프로세스에서 동일한 파일을 open 하여 사용할 경우 kernel 은 동일한 파일에 대한 내용을 memory에 1개만 들고있으면 된다.
mmap 파일의 동작을 그림으로 보자.
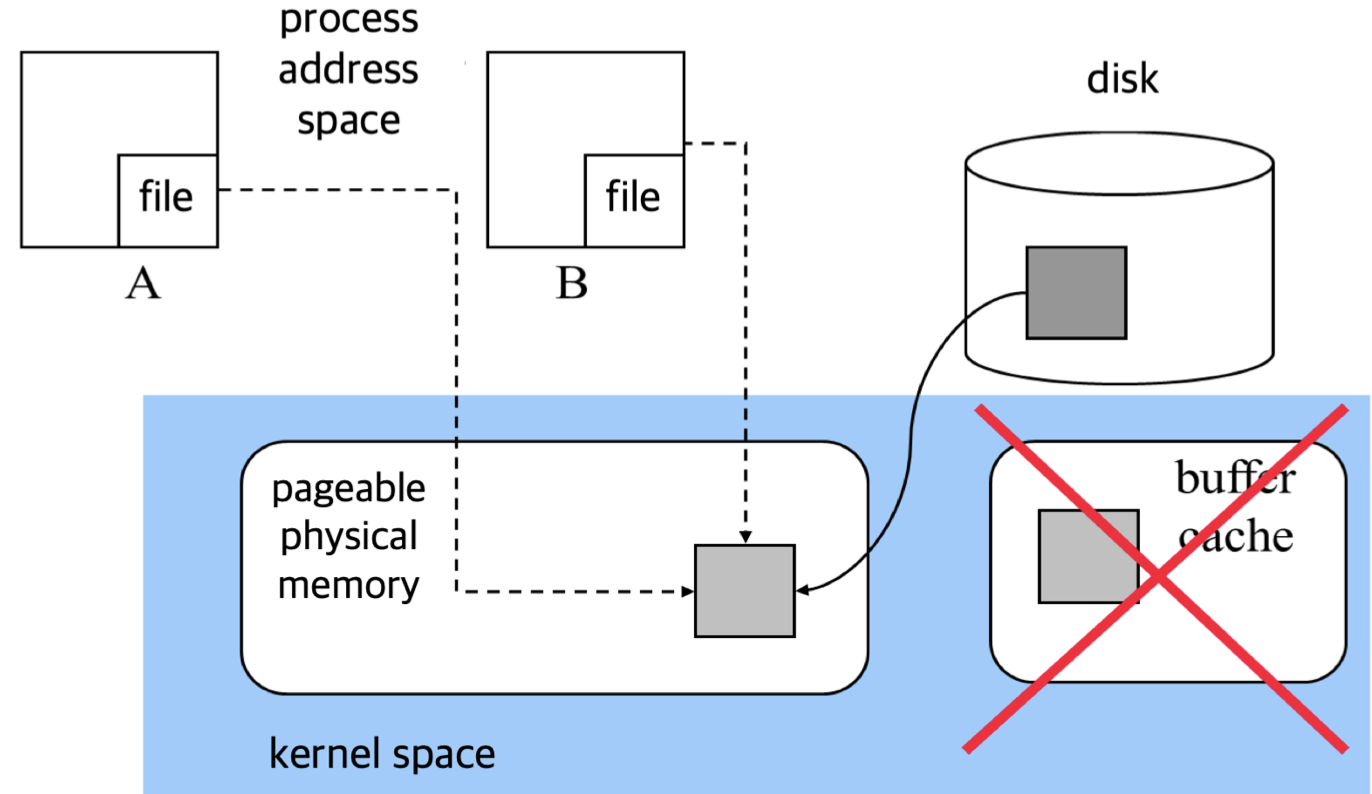
먼저 mmap 을 사용하지 않는 경우를 생각해보면, disk 에서 DMA로 data block을 가져오면 이를 buffer cache에 올리고 그다음 사용자 buffer 로 copy를 해야한다. buffer cache 로는 DMA 가 copy 해주지만, buffer cache 에서 user buffer 로는 CPU가 직접 copy 해야한다. 따라서 file IO 가 빨라지려면 CPU도 중요하다.
mmap은 조금 다르다. mmap은 buffer cache를 사용하지 않는다. mmap은 buffer cache에 data block을 쓰지 않고 바로 kernel space로 DMA가 쓴다. 그리고 이를 프로세스의 address space 에 page table을 통해 매핑한다. 따라서 user buffer 로의 copy가 존재하지 않는다. 위의 그림에서는 process A 와 process B 가 각각 mmap 되어있는 physical fragment 를 공유하고 있다. mmap 에서는 flag에 MAP_SHARED flag 를 통해 다른 프로세스와 mmap 된 파일을 공유할 수 있다. 하지만 다른 동기화 같은 장치는 제공하지 않는다. process A 에서 먼저 특정 파일을 mmap 하였을때 그 다음 process B 에서 같은 파일에 대해 mmap을 하게되면 서로 반환받는 virtual address 주소는 다르지만, 결국 page table 에 매핑된 physical address 주소는 같아 같은 파일을 바라보게 된다.
이 글은 학부 System Programming 수업을 듣고 파일시스템 관련내용을 정리한 글입니다.
파일(File)이란?
파일은 무엇일까? 파일은 linear array of bytes 이다. 이게 무슨말일까? 이전 운영체제 메모리편에서 보았듯이 address space는 sparse 하다. 즉 프로세스가 사용하는 주소공간은 중간부분을 사용하지 않고 비어있을 수 있다. 그러므로 효율적으로 사용하고자 multi-level page table을 사용하곤 했었다. 이와 다르게 파일은 linear array of bytes로 중간이 비어있지 않다. 그리고 파일은 byte addressable하다. Byte 단위로 접근이 가능하다는 것이다. 그리고 여기서의 linear array는 밑에서 보겠지만 logical한 block이 linear하다는 것이다.
하드디스크와 다르게 Flash는 메모리나 CPU처럼 트랜지스터 들로 구성이 되어있다. 즉 disk의 arm이 움직이거나 platter가 회전하는 물리적인 움직임이 없다. Reliability 측면에서도 disk에 비해 훌륭한 편이다. Disk는 물리적인 head crash가 날수도 있고, dead block(더이상 사용할 수 없는 block) 자체가 생길 수 있다. 물리적으로 읽고 쓰기 때문이다. 그리고 disk는 생각보다 자주깨진다. 이와는 다르게 Flash는 순수한 silicon으로 구성되어 있으며 전자적으로 동작하기에 더 신뢰성이 높다. Flash는 또한 매우 빠른 access time을 제공하고 power가 적게드는 반도체 특성으로 disk에 비해 매우매우 저전력이다. Flash Memory는 여러타입이 있는데 보통은 NAND-Flash를 의미한다.
다만 Flash가 가진 특이한 특성들 때문에 이를 해결하기 위해 몇가지 기법들을 적용해야한다. 이들은 밑에서 자세히 알아볼 것이다.
Flash chip은 하나의 transistor의 1개 이상의 bit를 저장할 수 있다. SLC(Single-Level Cell) flash는 오직 1개의 bit만 transistor에 저장할 수 있고, MLC(Multi-Level Cell) flash는 2개의 bit를 저장할 수 있다. 그러므로 00, 01, 10, 11을 저장할 수 있다. TLC(Triple-Level Cell) flash는 3개의 bit를 저장가능하다. 전반적으로 SLC가 더 성능이 좋고 가격이 비싸다.