운영체제 3편 - 컴퓨터 구조와 I/O(Interrupt & Trap)
이 글은 학부 운영체제 수업을 듣고 정리한 글입니다.
맥락없이 운영체제에 대한 내용들이 불쑥 등장하니 양해부탁드립니다.
이번에는 운영체제를 이해하기 위한 컴퓨터 구조에 대한 내용이다.
Bus, I/O 기초를 설명한다.
Bus
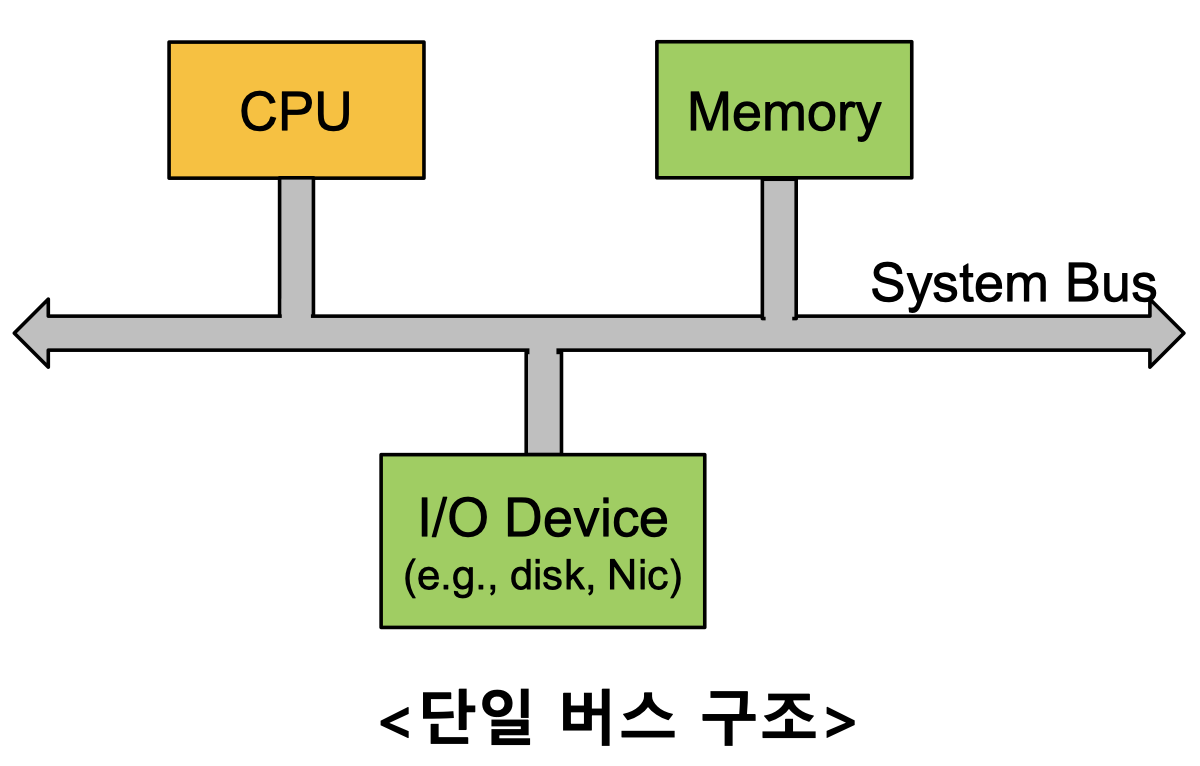
단일 Bus
초창기에는 Bus가 1개였다. CPU와 Memory가 붙어있는 구조이다.
이 방식은 CPU, Memory, I/O의 속도가 비슷했던 초창기에 사용했던 모델이다.
그런데 CPU, Device 들은 발전하는 속도가 각각 다르다.
1995년도에는 CPU clock이 45MHz였다. 지금은 거의 3.5GHz 정도이다.
속도는 CPU > Memory > IO 속도 순으로 빠를 것이다.
1GHz면 명령어 처리에 1 nano second 속도이다. 이와 비교하여 Disk 속도는 ms 단위이다. nano second와 milli second 차이는 100만배 차이이다. 고속도로에서 빠른차와 느린차와 같이 다닐 수 있을까? 불가능하다.
이처럼 같은 버스에 연결된 device들 간의 속도차이로 인해 병목현상이 발생한다. 시스템속도는 결국 느린 시스템 속도로 결정이 되게 된다.
위처럼 단일 Bus에서 CPU와 Disk를 붙여놓으면 CPU는 대부분 놀고있게 된다.
계층적 버스구조
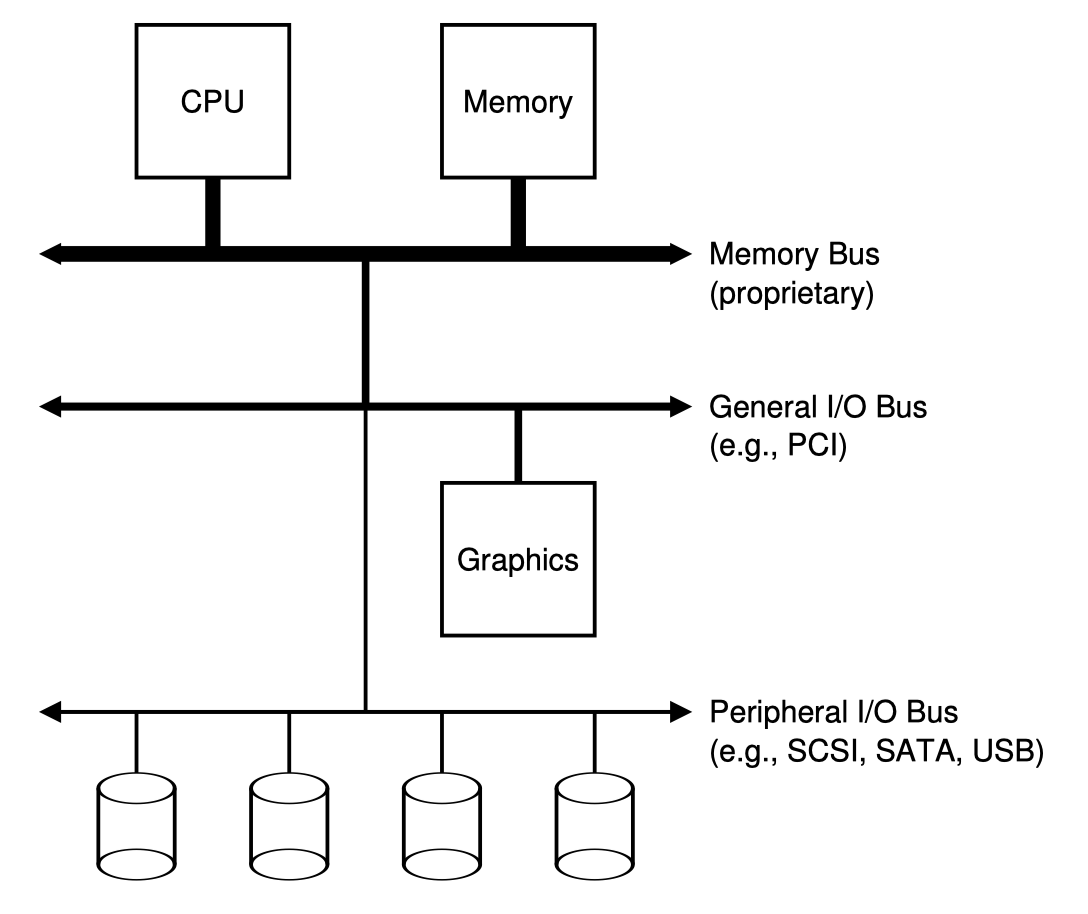
이를 해결하기 위해 Bus를 나누게 된다.
이를 계층적 버스구성이라고 하는데, 접근 빈도가 적고 처리속도가 느린 device들은 System Bus에 직접 연결하지 않고 I/O Bus를 거쳐 연결해서 stall 현상을 방지하는 것이다.
위 그림을 보게되면 CPU는 Memory와 Memory Bus(System Bus)로 연결되어있고, 몇몇 device들은 General I/O Bus에 연결된다. 현대 시스템에서는 이 general I/O bus가 PCI가 될 것이다.
높은 성능이 필요한 I/O device 들이나 graphic card를 이 general I/O bus인 PCI에 연결한다. 더 밑에는 Peripheral Bus가 위치하는데 여기에는 SCSI, SATA, USB 등이 속한다. 여기에는 disk, mouse, 키보드 같은 속도가 느린 device들이 연결된다.
memory bus는 매우 높은 성능이 필요한데 이처럼 매우 성능이 높은 bus는 비용문제, 난이도 문제로 device를 plug할 수 있는 공간자체를 크게 설계할 수 없다. 따라서 시스템 디자이너들은 이런 계층적 버스구조를 선택했고 I/O Bus도 종류에 나누어 높은성능이 필요한 device들은 CPU에 가깝게 배치하였다.
Peripheral bus는 조금 느린대신 많은 device들을 배치할 수 있다.
Modern 시스템 구조
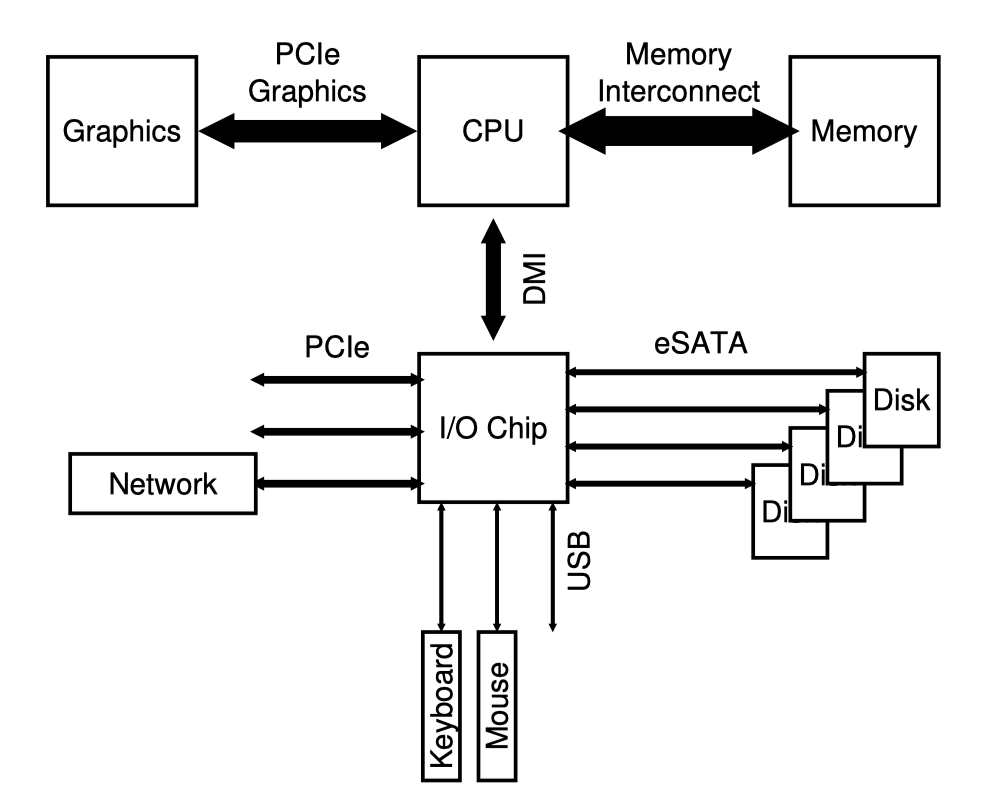
요즘에는 점진적으로 특수화한 chipset을 많이 사용하고 있고 성능향상을 위해 point-to-point interconnect를 많이 사용한다.
위 그림은 나름 최신?인 2017년에 인텔에서 출시한 Z270 chipset의 대략적인 구조이다.
CPU는 memory에 가장 가깝게 배치하고 높은 성능이 필요한 graphic card도 가깝게 배치한다.
CPU는 I/O chip에 Intel이 만든 DMI(Direct Media Interface)를 통해 연결하고 나머지 device들은 이 I/O chip에 연결을 한다.
I/O chip의 오른쪽에는 하드디스크들을 eSATA 인터페이스를 통해 연결하고, 그 밑에는 USB(Universal Serial Bus) 연결로 키보드나 마우스들을 연결할 수 있다.
왼쪽에는 PCIe(Peripheral Component Interconnect Express)를 통해 더 높은 성능의 device들이 연결될 수 있다. 이 그림에서는 NIC(Network Interface Card)가 연결되었다.
높은 성능이 필요한 NVMe 같은 스토리지 device들도 이곳에 연결되기도 한다.
이제 I/O 기초에 대해 알아보자.
Interrupt
Interrupt는 비동기적인 이벤트를 처리하기 위한 기법이다. CPU는 외부에서 일어나는 이벤트를 모른다. 그래서 Hardware 적으로 알려주는게 Interrupt이다.
예를들어 CPU는 10ms로 time slice를 한다고 할때, 10ms가 경과하는걸 어떻게 알 수 있을까? Timer가 interrupt를 날려준다.
또 다른 예로 packet이 도착한다. 그러면 packet을 읽어줘야 하는데, 어떻게 읽을 수 있을까? 패킷이 도착하면 Interrupt를 발생시킨다. 그러면 현재 수행하고 있는 프로그램을 잠시 멈추고 ISR(Interrupt Service Routine)을 수행한다.
ISR을 수행하고 다시 멈췄던 곳으로 돌아가 수행을 계속한다.
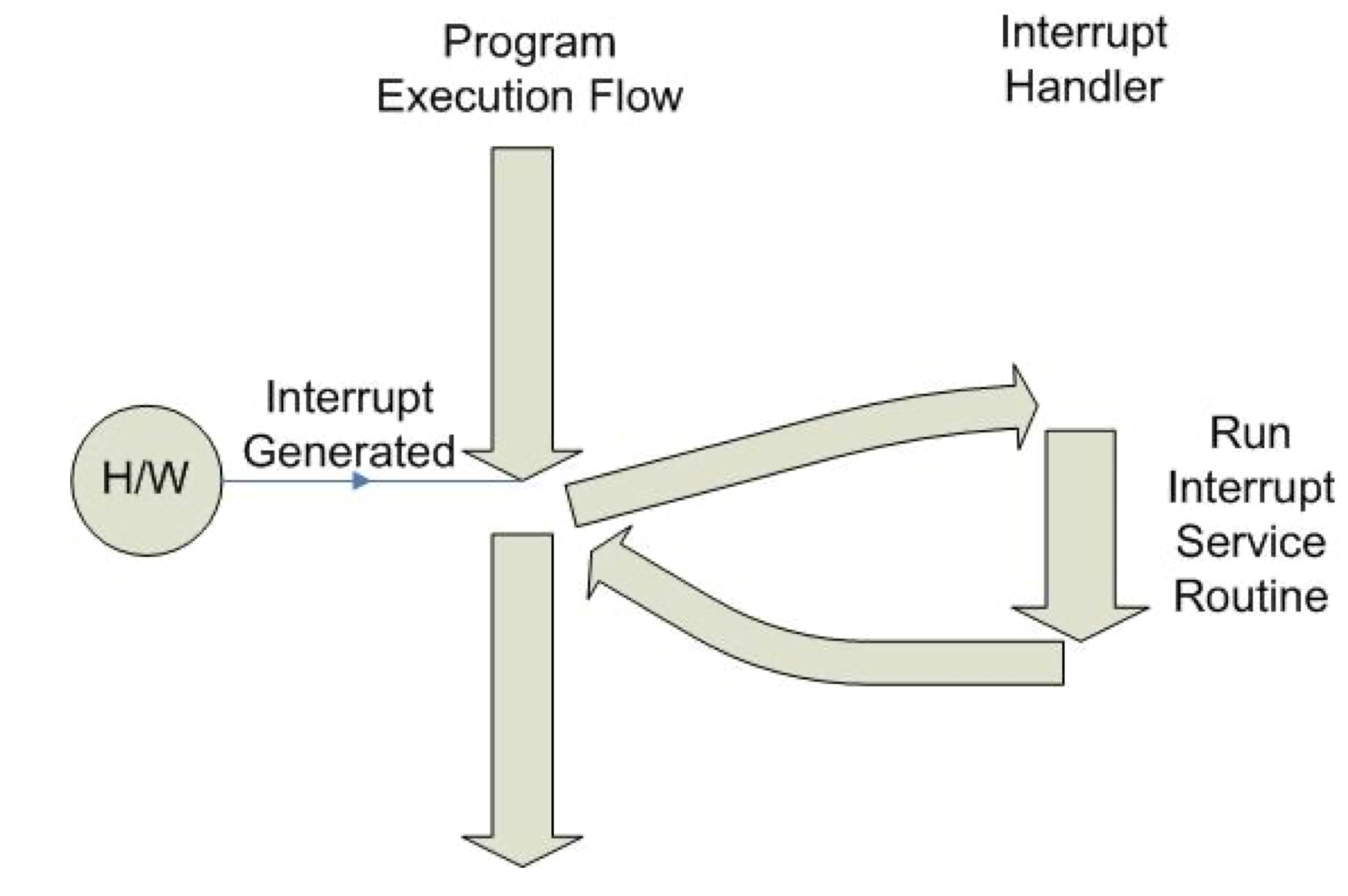
Interrupt 처리순서
- 현재 state를 저장
- ISR(Interrupt Service Routine)으로 점프
- ISR 수행
- 저장한 state를 복원
- Interrupt로 중단된 지점부터 다시 시작
ISR은 interrupt 종류마다 따로 존재한다. Disk에서 IO block을 읽으면 그에 대한 ISR로 jump 하고, 네트워크 패킷을 읽으면 그에 대한 ISR로 jump 한다.
ISR로 jump를 한 후 전부 처리한 후 다시 멈췄던 곳으로 어떻게 다시 돌아가 프로그램 수행을 계속할 수 있을까?
이를 위해 ISR로 jump 하기전에 context를 저장을 해야한다. context는 현재 실행 상태를 의미한다.
CPU register를 저장해 현재의 state를 저장해야하며, Program Counter 즉 어디까지 수행하다가 멈췄는지를 저장해야한다. ISR 수행을 마치면 저장했던 state를 복구한 후 수행을 계속 이어나간다.
인터럽트에는 우선순위가 있다. 이는 Hardware 장치별로 우선순위가 다르게 설정된다.
그리고 ISR은 짧아야한다. 너무 길면 다른 Interrupt들이 제 시간에 처리되지 못할수 있다. ISR을 들어갈 때 interrupt를 disable 시킨다. 그렇지 않으면 하염없이 중간에 계속 interrupt가 중첩될 수 있다.
Interrupt flow는 간단하게 다음 그림과 같다.
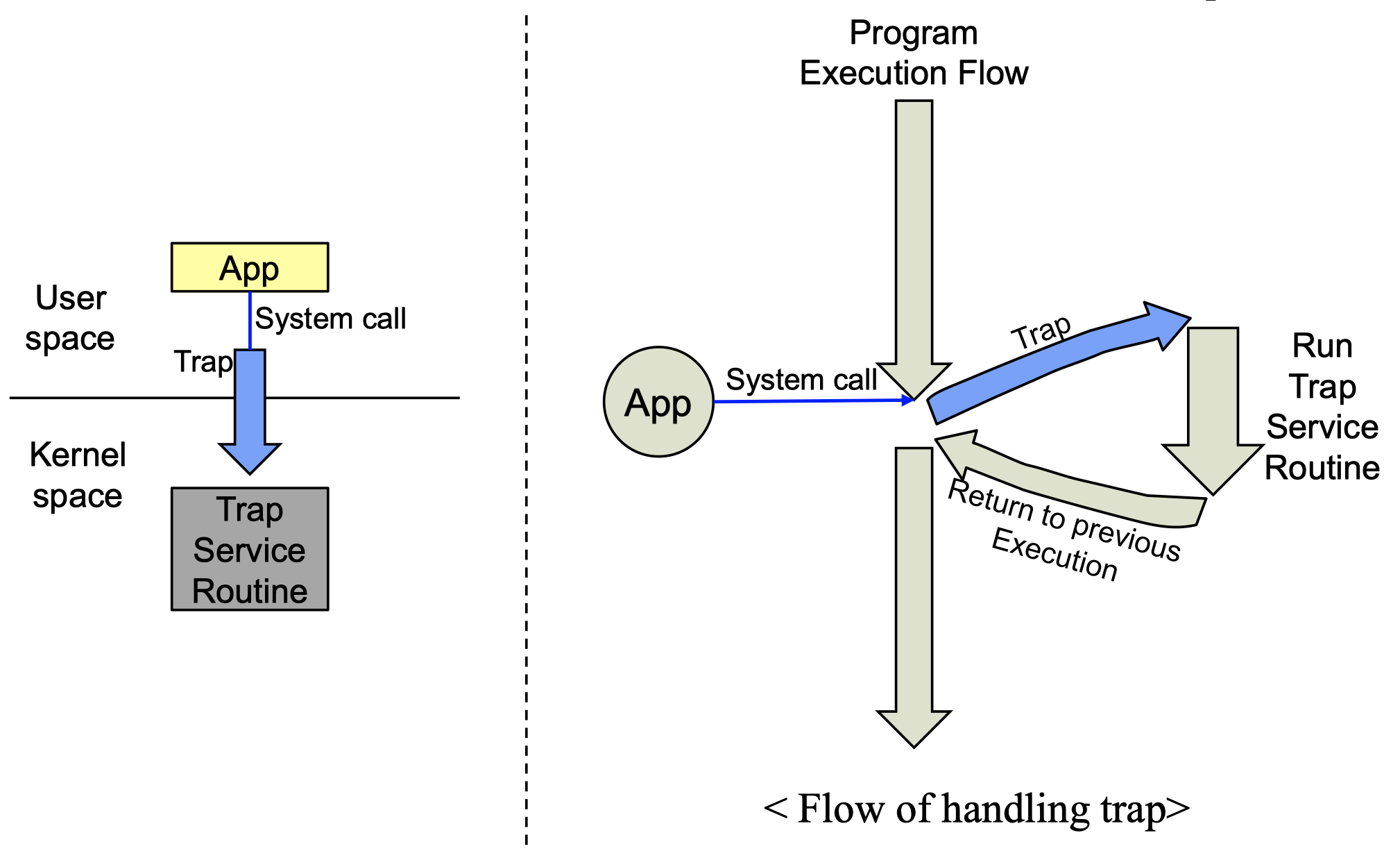
Trap
Trap은 Interrupt와 유사하다. Interrupt가 비동기적인 이벤트를 처리하기 위한 기법이였다면 Trap은 동기적인 이벤트를 처리하기 위한 기법이다. 동기적이라는 의미는 현재 수행하고 있는 프로그램에 의해 발생한다는 것이다.
Trap은 kernel 안에 있는 Trap handler를 invoke 시키는 event라고 이해하면 쉽다.
예를 들어서 divide by zero 하면 멈춘다. divide by zero하면 어떻게 이를 인지할 수 있을까? 바로 Trap 이다. 하드웨어가 divide by zero를 하면 스스로에게 trap을 건다.
divide by zero 뿐만 아니라 잘못된 메모리 주소에 접근하려고 하면 segmentation fault가 발생하는데 이때 스스로에게 Trap을 건다.
혹은 process가 특별한 instruction을 실행하면 Trap이 발생한다. 이 경우는 보통 system call을 처리하기 위한 Trap이라고 볼 수 있는데, system call은 call의 name과 arguments들을 register나 stack에 저장을 하고 user-initiated한 trap을 발생시킨다.
그러면 Trap Handler인 Trap Service Routine을 실행하는데 내부적으로 trap의 타입을 보고 system call에 대한 요청일 경우 call의 name을 보고 그에 맞는 kernel procedure를 호출한다. 그리고 다시 원래의 프로그램 진행을 계속 한다.
System call이 trap을 발생시키는 이유는 user mode에서 kernel mode로 변경해야하기 때문이다.
Interrupt와 다른점은 interrupt는 발생하였을때 context를 전부 다 저장한 후 ISR로 넘어간다. 다만 trap은 따로 context를 저장할 필요가 없다.
여기서의 context는 대표적인 예로 register가 있다. Interrupt는 발생했을때 CPU의 register state를 모두 저장하는데 trap은 이들을 저장할 필요가 없다. .
그렇다고 모든 상태를 저장하지 않는다는 이야기는 아니고 trap는 현재의 Program Counter와 stack pointer 등을 하드웨어적으로 자동으로 저장한다. Trap은 무수히 많이 발생하므로 하드웨어적으로 자동으로 저장하도록 처리해놓아 직접 state를 저장할 필요 없고 가볍게 하드웨어적으로만 저장하기 때문에 state를 저장하지 않는다고 표현한다. (TA라는 instruction으로 현재의 stack pointer를 하드웨어적으로 저장하고 수행을 마치고 복구할때는 RTT라는 instruction으로 복구시킨다)
사실 조금 더 정확히 말하면 위에서의 Program Counter는 정확히말하면 Kernel mode와 User mode가 각각 서로 따로 PC를 가지기 때문에 따로 저장하지 않는다고 한다. Interrupt Service Routine도 Trap도 모두 kernel mode에서 실행된다.
Trap은 짧을 필요는 없다. 시스템 콜을 봐도 수행시간이 긴 시스템 콜도 존재한다. 시스템 콜을 할 때에는 중간에 interrupt를 허용하기도 한다.
간단하게 Trap flow는 다음과 같다.
I/O Device
운영체제의 관점에서는 I/O Device를 어떻게 바라볼까?
일반적으로 하드웨어에는 장치를 제어하는 controller라는게 있다. 이 controller 안에는 대부분 크게 4가지 종류의 register를 가진다.
Control(command) register, Status register, Data register(Input register, Output register) 이다.
I/O 라는 것은 결국 CPU가 I/O Device의 register에 읽고쓰는 동작이라고 이해할 수 있다.
Disk에 데이터를 쓴다는 것은 Disk의 control register에 쓰기 명령을 주는 것이다. 그리고 data register에는 어떤 내용을 write할 건지에 대한 정보를 준다.
I/O하는 과정은 대략적으로 다음과 같다.
- Status Register가 BUSY 상태가 아닐때까지 기다린다.
- Data register에 값을 쓴다.
- Control Register에 command를 쓴다. 그러면 device가 command를 수행을 시작한다.
- Device 작업이 끝날때까지 기다려야 하므로 Status Register가 다시 BUSY 상태가 아닐때까지 기다린다.
- 작업이 끝났으면 Data register를 보면 그 결과에 대한 값이 올라와있다.
Data Register는 Input, Output 용을 나누어 Input Register, Output Register로 나누기도 한다.
이것이 운영체제가 바라보는 I/O Device model 이다.
여기서의 device register에는 어떻게 접근할까? 보통 이들의 register는 메모리 영역에 mapping을 해놓는다. Memory mapped I/O라고도 부르는데 나중에 더 자세히 다루겠지만 매핑된 영역의 주소로 memory read, write instruction만 수행으로 Device Register에 읽고 쓸수있다고 생각하면 쉽다.
I/O 처리기법
만약에 Device에 읽기 요청을 보냈다. 그런데 언제 이 읽기요청이 완료되었는지 모른다. 이를 어떻게 알 수 있을까?
CPU는 크게 2가지 방법있다. Polling과 Interrupt이다.
Polling
위에서 예시로 본 I/O 과정은 CPU가 직접 Device의 Status Register가 준비된 상태인지 확인한다. 그리고 Device 작업이 끝났는지 확인하기 위해 계속해서 Device Status Register를 확인한다. 이 방식이 Polling 방식이다.
Polling은 loop이나 time-delayed loop에서 특정 이벤트의 도착여부를 계속 확인하는 방식이다.
Polling을 한 후에는 PIO(programmed I/O)라는 것을 수행한다. 이는 CPU가 직접 I/O를 한다. Disk를 read할 때 Disk로 부터 block이 도착했다면 이를 memory로 copy하는 것까지 CPU가 모두 처리해 주어야 한다. 그러면 CPU는 너무 할일이 많고 다른 process를 수행하는 시간도 줄어들게된다.
Using Interrupt
위의 Polling 방식에서의 CPU 낭비를 줄이기 위해서 Interrupt를 활용할 수 있다. Device를 polling 하는 방식이 아닌, I/O를 요청한 process를 sleep하게 하고 CPU는 context switching을 하여 다른 프로세스를 수행한다. Device가 operation 수행을 끝냈으면 hardware interrupt를 발생시키고 CPU는 ISR을 수행하면 해당 I/O를 요청한 프로세스를 다시 깨운다. 그리고 다시 스케줄링을 받아 수행을 이어가게 된다.
얼핏보면 위에서 본 Polling 방식보다는 Interrupt 방식이 훨씬 좋아보인다. 그럼에도 polling이 유리한 상황이 있다.
Device에 굉장히 짧은 주기로 빠르게 operation을 해야하는 경우에는 polling이 유리하다.
예를들어 화면을 보여주는 display device를 생각해보자.
Frame buffer라는 곳이 있는데 이 frame buffer에 frame들을 쓰면 화면에 바로 찍히게 된다. Frame buffer에 계속해서 pixel들을 던지고 refresh 하고 이 일들을 계속 반복한다. 이렇게 빠르게 동작하는 장치는 interrupt로 처리하는 것보다 계속 polling을 하는 것이 효과적이다.
이를 Interrupt 방식으로 구현한다면 전체 시스템이 굉장히 느려질 수 있다. 한번 Display Device에 쓸때마다 해당 프로세스는 sleep하고 Context Switching이 일어난다. 그러면 operation이 완료되면 hardware interrupt가 발생하고 해당 프로세스는 다시 ready queue에 들어가 스케줄링을 기다린다.
하지만 1초에 60번씩 계속 Device에 써줘야 하는 상황이라면 과도한 Context Switching만 발생할 뿐이다. 이런 경우에는 polling이 유리하다. Interrupt handling과 Context Switching 대한 비용이 polling 비용을 넘어갈 수 있다.
Polling 방식과 Interrupt를 합친 하이브리드 방식도 존재한다.
DMA
위에서 본 Programmed I/O 방식은 크기가 큰 data를 device에 전달하기 위해서는 CPU가 많은 작업을 수행해야 한다. 다음 그림은 이런 상황을 묘사한다.

프로세스 1 이 수행중이고 disk에 data를 쓰기를 원한다. Interrupt 방식을 사용한다면, 먼저 I/O를 하기위해 write하고 싶은 데이터를 메모리로부터 device로 전송해주어야 한다. 정확히는 data register에 이를 copy하여 써주어야한다. 이에 대한 수행시간을 c(copy)로 표현했다.
Data copy가 완료되었으면 disk는 I/O operation을 수행하고 CPU는 Context Switching 하여 다른 프로세스 2 를 수행할 수 있다.
이 상황에서 CPU는 데이터 전송에 너무 많은 시간을 할애하는 문제가 있다. 이를 해결하기 위해 CPU를 Device 데이터 이동에 사용하지 않고 I/O를 위한 별도의 장치를 사용할 수 있는데 그것이 DMA(Direct Memory Access)이다.
DMA는 특수목적 프로세서이다. CPU가 DMA에게 I/O를 요청하면 DMA는 CPU를 대신하여 I/O장치와 메인 메모리 사이 데이터전송을 수행한다.
CPU가 DMA에게 I/O를 위임한다. DMA가 대신 I/O를 수행해준다. CPU가 DMA에게 I/O를 요청하면, DMA는 CPU를 대신하여 I/O 장치와 메인 메모리 사이에 데이터 전송을 수행한다. CPU는 이 기간동안 다른 작업을 수행할 수 있다.
CPU는 Device에 직접 memory로 부터 data를 copy할 필요없이 DMA에게 copy할 메모리의 주소와 얼마나 전송할지를 알려준다. DMA는 I/O를 대신 수행하고 완료되면 Interrupt를 발생시킨다.
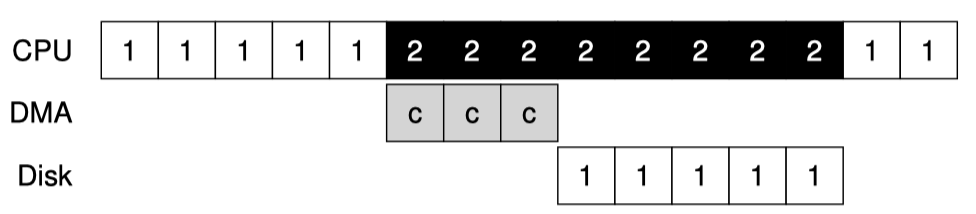
위 그림에서 Data copy에 걸리는 작업은 DMA가 수행하는 것을 볼 수 있다. CPU는 I/O를 DMA에 요청하고 바로 다른 프로세스를 스케줄링하여 수행할 수 있다.
DMA는 Memory Bus를 공유한다. CPU도 메모리에 접근하고 DMA도 메모리에 접근이 필요한데 메모리에 둘다 접근하려면 Bus를 통해 접근을 해야한다. 이 과정에서 둘이 충돌을 할 수 있는데 DMA는 CPU가 Bus 사용을 하지 않을 때 살짝살짝 사용한다. 이를 Bus stealing이라고 한다.
예제로 Disk에 Read하는 과정을 보자.
Disk Read 과정
- CPU는 DMA Controller를 초기화하고 전송모드를
DMA_MODE_READ로 설정한다. - CPU는 DMA Controller에게 buffer(memory)의 주소(X)와 크기(C)를 알려준다.
- DMA Controller는 Disk controller에게 데이터를 전송한다.
- Disk controller는 매번 byte단위로 읽어오는 데이터를 DMA로 전송한다.
- DMA Controller는 받은 데이터를 주소 X의 buffer에 기록한다. 매 전송마다 C값을 감소시키고 C=0일때까지 전송받는다.
- C가 0이되면 전송이 완료된 것이므로 DMA Controller는 전송이 완료되었음을 interrupt를 통해 CPU에 알린다.
위 과정의 1번, 2번까지 하면 그 프로세스는 sleep 한다.
I/O가 끝나야 이를 호출한 process는 다음 step으로 넘어가는데 이를 synchronous I/O model이라고 한다.
다른 I/O model들도 있는데 이는 여기서는 범위가 넘어가므로 다루지 않을 예정이다.
보통은 DMA가 CPU와 병렬적으로 같이 작동할 수 있기때문에 high performance가 필요할 때에는 더 좋다고 할 수 있다. 다만 DMA라는 장치가 필요하므로 조금 더 cost가 있다고 할 수 있겠다.
I/O 접근방법
I/O device에 접근하는 방법은 크게 2가지가 있다.
I/O instruction을 사용한다.
CPU가 제공하는 instruction을 통해서 장치의 register를 읽고 씀으로서 device 장치와 통신한다.
예로는 intel의 I/O instruction인in,out,ins,outs등이 있다.두번째로는 Memory Mapped I/O를 사용하는 것이다. 위에서도 살짝 언급했지만 Device 장치 register들을 memory 공간으로 mapping시키는 것이다.
그냥 load, store 명령어를 통해 장치의 register를 읽고 쓸 수 있다. 다만 instruction 관점에서 I/O instruction과 다른 점이 있는데, Memory Mapped I/O 에서는 control register에 값을 쓰는게 1개의 instruction이 된다. I/O instruction은 control register에READ를 넣고 in register에 주소를 넣어주는 이런 일련의 동작들을 하나의 instruction으로 처리한다.
Memory Mapped I/O는 Memory space와 I/O space를 구별하지 않는다. 최근의 Device들은 거의다 Memory Mapped I/O를 지원한다.
단, Memory Mapped I/O를 위해서는 IO MMU(Input Output Memory Management Unit)라는 걸 사용해서 MMU가 CPU에서 보는 virtual memory address를 physical memory address로 바꾸어주듯 Device 입장에서 보는 virtual memory address를 physical memory address로 변환해주는 장치가 필요하다.
Device Driver
각 device들은 서로다른 interface를 가지고있는데 어떻게 이들의 interface에 맞게 접근할 수 있을까?
파일시스템을 예로들면 파일시스템은 SSD, USB, SCSI disk 등의 위에서 작동할 수 있다. 하지만 우리는 이 각각의 매체에 의존하지 않고 block read, write을 하고싶은데 어떻게 이를 가능하게 할까?
이들위에 Abstraction layer을 둠으로써 가능하다. 위에 General한 Interface를 두고 이 Interface를 통해 접근하도록 한다.
하지만 결국에는 OS row level 어딘가에 각 device에 specific한 interface에 접근하는 코드가 존재를 해야한다. 이것이 바로 Device Driver이다.
밑의 그림은 간단히 표현한 Linux Software 구조이다.
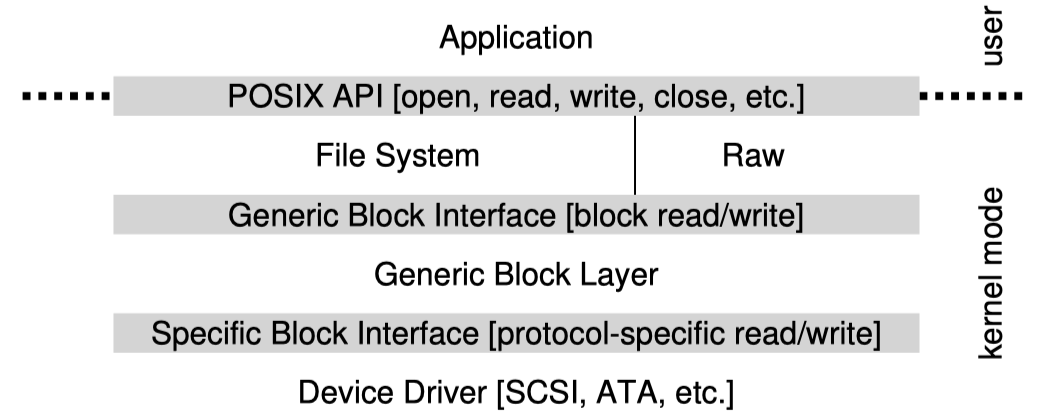
파일시스템은 단지 generic block layer를 바라보면서 block read, write 에 대한 요청만 수행하고 실제 disk 매체에 의존하지 않는다.
Block layer가 요청을 보고 적절한 device driver에 라우팅을 해준다.
그림에서는 raw interface도 볼 수 있는데 이는 File Abstraction을 사용하지 않고 direct block read, write을 허용하게 해준다. 예를들어 파일조각모음 tool이나 file system checker 같은 소프트웨어들이 이 raw interface를 사용하여 구현한다.
다만 Generic 한 Interface에만 의존하기 때문에 단점도 존재하는데, 예를들어 SCSI는 detail한 error log을 볼 수 있도록 해준다. 하지만 generic interface에는 generic IO Error만 받을 수 있기때문에 SCSI의 이런 이점을 가져갈 수 없다.
Device driver들의 구현코드들이 존재해야 이런 device들에 접근할 수 있기때문에 Kernel은 많은 Device driver 코드들을 가지고있다. 실제로 Linux kernel의 70% 정도가 device driver 코드들로 이루어져 있다.
IDE Disk Driver 예제
실제 IDE Disk Driver의 예제를 가볍게 보자. 이를 보고나면 대략적으로 Device driver가 어떤 방식으로 이루어져 있는지 알 수 있을 것이다.
먼저 IDE Interface는 다음과 같다.
1 | |
IDE Disk은 4개의 register를 제공하는데 control, command, status, error register 들이다.
이 register들은 x86의 in, out instruction을 사용해 I/O address를 명시함으로서 읽거나 쓸 수 있다.
예를들어 Disk가 ready 상태인지 알기위해 위에 명시된 Status Register의 주소인 0x1F7을 읽어 READY 상태이면서 BUSY 가 아닌지 확인한다.
Command Register에 Write parameter를 쓰기 위해서는 sector count, sector의 LBA(Logical Block Address), drive number 등을 register에 각각 작성한다. 그리고 I/O를 시작하려면 Command Register인 Address 0x1F7에 WRITE command를 쓴다.
실제 데이터 전송을 위해서는 데이터를 전송해야하는데 데이터를 Data Port에 써준다.
Interrupt는 각 sector가 전송되면 발생하게 할수도 있고, 전체 전송이 완료되면 발생하게 할수도 있다.
위에서 본 것은 IDE Disk의 Interface이고 이를 이용하는 Disk Driver를 작성해야한다.
이는 실제 구현된 IDE Disk Driver를 보면 이해가 쉽다.
IDE Disk Driver는 크게 4가지 주요한 함수가 있는데 각각 가볍게만 알아보도록 하자.
ide_rw()
맨처음 read, write을 하기 위해 호출하는 함수이다.
다른 작업들이 있으면 요청을 queueing 하고 없으면 바로 다음함수인 ide_start_request()를 호출한다. 이를 요청한 프로세스는 여기서 sleep하도록 설정한다.
ide_start_request()
이는 read, write 요청을 disk에 전달하는 역할을 가진다. 여기서 device register에 in, out x86 instruction을 호출한다. 이 함수는 밑의 ide_wait_ready() 함수를 사용한다. 이는 요청을 device에 보내기 전에 ready 상태일때까지 기다린다.
ide_wait_ready()
ready 상태일때까지 busy waiting 한다.
ide_intr()
Interrupt가 발생했을때 수행되는 함수이다. 만약 read 에 대한 interrupt였다면 device로부터 data를 읽어들이고 해당 read 요청을 한 프로세스를 깨운다. 그리고 다른 작업들이 queueing 되어있으면 다시 ide_start_request()를 호출한다.
코드는 다음과 같다.
1 | |
번외
위의 I/O instruction과 개념은 비슷하게 최근에 나온 neural processor는 metric 연산을 하나의 instruction을 제공한다.
기존의 metric 연산은 여러개의 instruction이 필요했는데 neural processor는 1개의 instruction으로 수행이 가능하다.Interrupt는 CPU clock 마다 작동할 수 있다. 다만 instruction이 수행중에는 interrupt가 발생할 수가 없다.
Instruction은 hardware와 software의 경계라고 볼 수 있다. 만약 instruction이 8 cycle이 걸린다고 하면, 그 8 cycle이 끝나는 시점에 interrupt가 발생한다. 이 instruction 중간에는 interrupt가 발생할 수 없다.
정리
- Interrupt는 비동기적인 이벤트를 처리하기 위한 기법이다.
- Trap은 잘못된 메모리주소 접근, system call 호출 등과 같은 동기적인 이벤트를 처리한다.
- I/O는 결국 Device register에 읽고 쓰는 것이다. DMA라는 하드웨어가 CPU대신 I/O 작업들을 처리해줄 수 있다.
- Memory Mapped I/O를 사용하면 Device 장치 register들을 메모리 접근 instruction으로 읽고 쓸 수 있다.
Reference
- https://www.amazon.com/Operating-Systems-Three-Easy-Pieces-ebook/dp/B00TPZ17O4
- http://www.cs.unc.edu/~dewan/242/f96/notes/notes1/node13.html