Hadoop 파일기반 자료구조(SequenceFile, MapFile)
이번 글에서는 Hadoop에서 지원하는 파일저장시 지원하는 자료구조 2가지를 알아본다.
파일에 데이터를 저장시 그냥 blob 전체를 한개의 파일에 그대로 몽땅 저장하는 방식을 생각해보자. 그러면 파일의 내용은 block 크기로 잘라져 논리적으로 연속된 block으로 보일 것이다. 다만 이런 방식이면 경우에 따라 확장성에 좋지 않을 수 있다.
따라서 다양한 상황을 위해 Hadoop은 여러 파일 기반의 자료구조를 지원한다. 즉 스토리지에 저장시에 고려하는 자료구조이다.
여기서 볼 자료구조는 SequenceFile과 MapFile이다.
SequenceFile
SequenceFile은 로그파일과 잘맞는다. 로그파일은 record 한개당 하나의 행이다. 이런 로그파일을 그냥 binary로 저장하는것은 이후에 이 로그파일을 기반으로 무언가 작업을 할 예정이라면 확장성이 없는 방식이다.
Hadoop에서 제공하는 SequenceFile은 이런 형식의 데이터를 저장하기에 적절하다. SequenceFile은 binary key-value 쌍에 대한 storage-level의 자료구조를 제공한다.
예를들어 로그의 포맷이라면 key를 Hadoop의 LongWritable로 표현되는 timestamp로, value를 로그의 내용으로 저장할 수 있겠다.
SequenceFile format
SequenceFile의 포맷을 조금 더 자세히 보자. SequenceFile의 대략적인 내부구조는 다음과 같다.
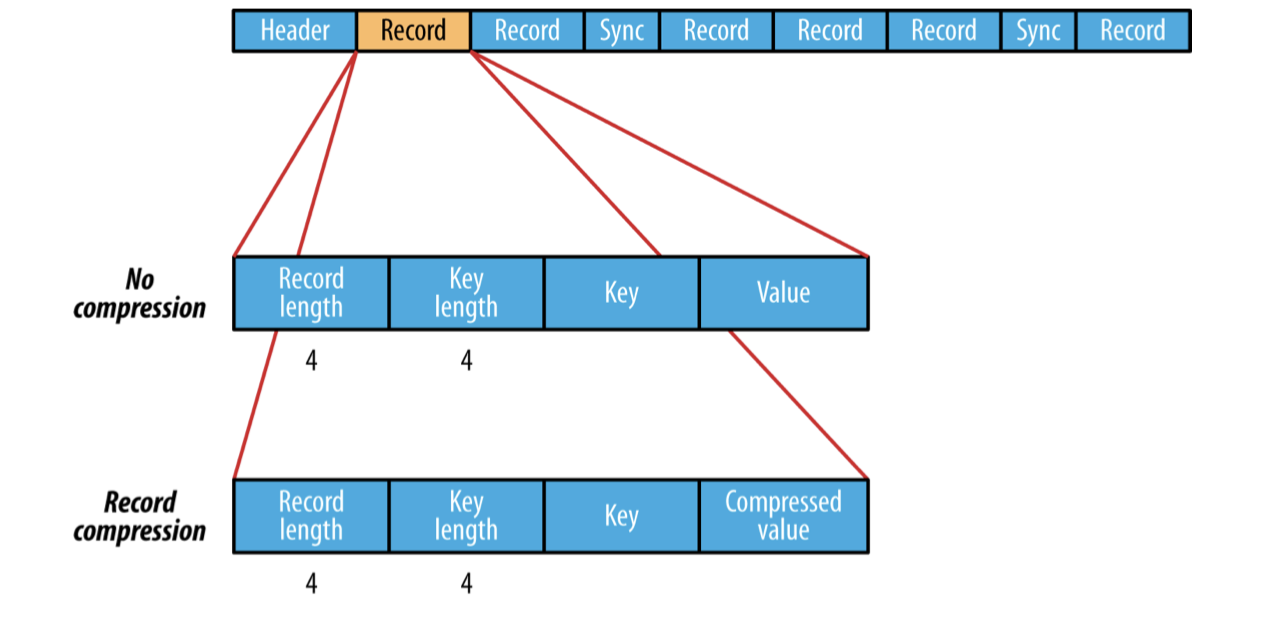
맨앞에는 header가 오고 그 뒤에는 하나이상의 record들이 위치한다. header에는 key, value 클래스의 이름, 압축이 되어있다면 압축관련정보 그리고 sync marker등이 존재한다.
SequenceFile에서는 sync point라는 것이 존재한다. SequenceFile에 write 할때 몇개의 record 단위마다 sync point를 marking 해놓는다. 이 sync point는 반드시 record 경계에 맞추어진다.
이 sync point는 reader가 record 경계를 잃어버렸을때 record 경계를 다시 동기화 하는데에 사용할 수 있다. 예를들어 파일의 위치가 record 경계에 있지 않으면 reader의 읽기 메서드가 예외를 반환한다. 이런 경우에 SequenceFile.Reader의 sync(long position) 메서드를 호출하면 position 이후의 바로 다음 sync point로 read point를 이동시켜준다. 그러므로 그 다음부터는 읽기를 다시 정상적으로 수행할 수 있다.
위 그림에서도 몇개의 record 단위마다 sync point가 저장되어있는 것을 확인할 수 있다.
각 SequenceFile은 랜덤하게 생성된 sync marker가 있고 이 값이 header에 존재한다. 그리고 이 sync marker가 위에서 본 sync point 마다 값이 저장되어 있는것이다.
이제 record는 내부구조가 어떤지 살펴보자.
만약 record가 압축되어있지 않다면 각 record 들은 위의 그림과 같이 byte 단위의 record length, key length, key, value로 구성된다.
record가 압축이 되어있는 경우는 압축하지 않은 경우와 거의 동일하지만 value가 header에 명시된 codec으로 압축된 binary 인 점만 다르다.
여러개의 record을 모아 block을 구성하고 이 block을 압축하는 방식도 있다. 여러개의 record로 구성된 block 자체를 압축하므로 record 단위 압축보다 압축도가 높고 가까이 있는 record 간에 유사성이 높으므로 효율도 더 좋을 수 있어 record 단위의 압축보다는 block 단위 압축방식이 더 선호된다.
record들은 io.seqfile.compress.blocksize 설정값에 정의된 크기에 이를때까지 하나의 block에 계속 추가된다. 이 설정의 기본값은 1MB이다.
Block compression 방식의 내부구조는 다음과 같다.
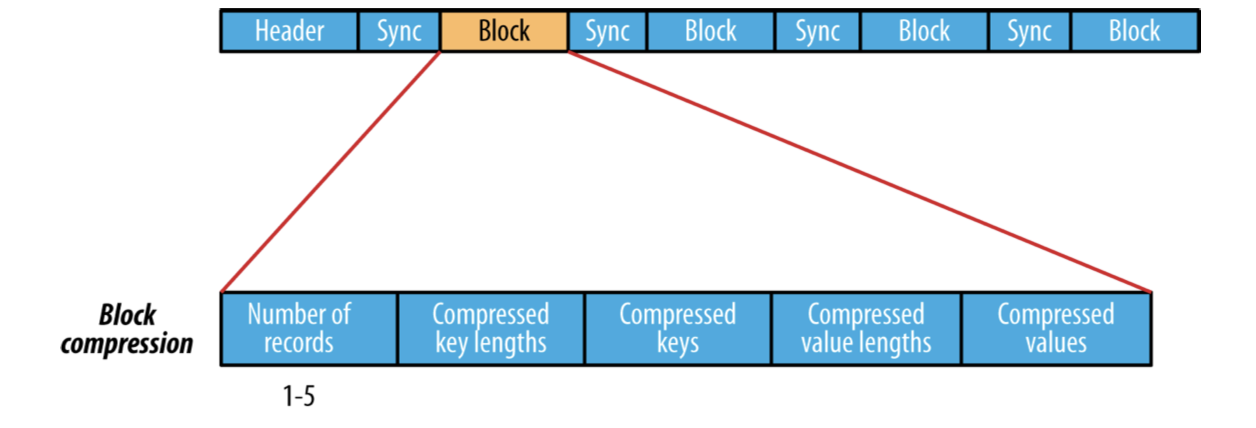
이 SequenceFile은 대용량 dataset에 적합하다. 효율적으로 대용량 dataset을 처리하는데 효율적으로 설계되었으며, 각 SequenceFile 의 부분들을 병렬로 처리하도록 설계할 수도 있다. 또 파일의 순차접근에 강하며 파일을 저장할때 그냥 binary format으로 저장하기 때문에 매우 심플하고 다른언어에서도 이를 쉽게 다룰 수 있다.
다만, Parquet 이나 ORC 같은 포맷에 비해서는 공간효율적이지는 못하다. 그리고 random access 를 위해 설게된 것은 아니기에, random access 가 자주 사용되는 애플리케이션에서는 SequenceFile이 비효율적 일 수 있다. 그리고 schema 변화를 제한적으로만 지원하기 때문에 데이터 구조를 변경하는 것이 힘들다.
MapFile
MapFile은 key를 기준으로 정렬이 되어있는 SequenceFile이다. 앞에서 본 SequenceFile은 record들이 정렬되어있을 필요는 없었다. 다만 MapFile은 반드시 record 들이 key 기준으로 정렬되어있어야 한다. 그리고 MapFile은 index를 통해 key로 record를 빠르게 검색할 수 있다.
MapFile을 생성하게 되면 directory가 생성되고 이 내부에 data 파일과 index 파일이 각각 존재한다. 여기서의 data 파일과 index 파일 모두 SequenceFile이다. data 파일은 key로 정렬된 record들로 구성되어 있으며 index 파일도 내부에 key들의 fragment들을 포함하고 있는 SequenceFile이다.
index는 기본적으로 data record의 128번째마다 key를 저장해둔다.
MapFile에서 key 검색을 위해서는 index를 메모리에 올려 index를 기준으로 data record의 위치를 찾는다.
MapFile은 SequenceFile과 조금 다르게 파일에 쓸때에는 반드시 key로 정렬된 순서로 write해야한다. 그렇지 않으면 예외가 발생한다.
Other File format
Hadoop은 SequenceFile과 MapFile 말고도 다른 새로운 파일포맷도 많이 제공한다. SequenceFile, MapFile은 모두 row 기반의 파일포맷이지만 이 방식 말고도 column 기반의 파일포맷도 존재한다.
column 기반의 파일포맷에서는 각 row를 컬럼기준으로 나누어 저장한다. 예를들어 다음 그림처럼 첫번째 column이 먼저 저장되고, 그 다음 column이 저장되는 방식이다.
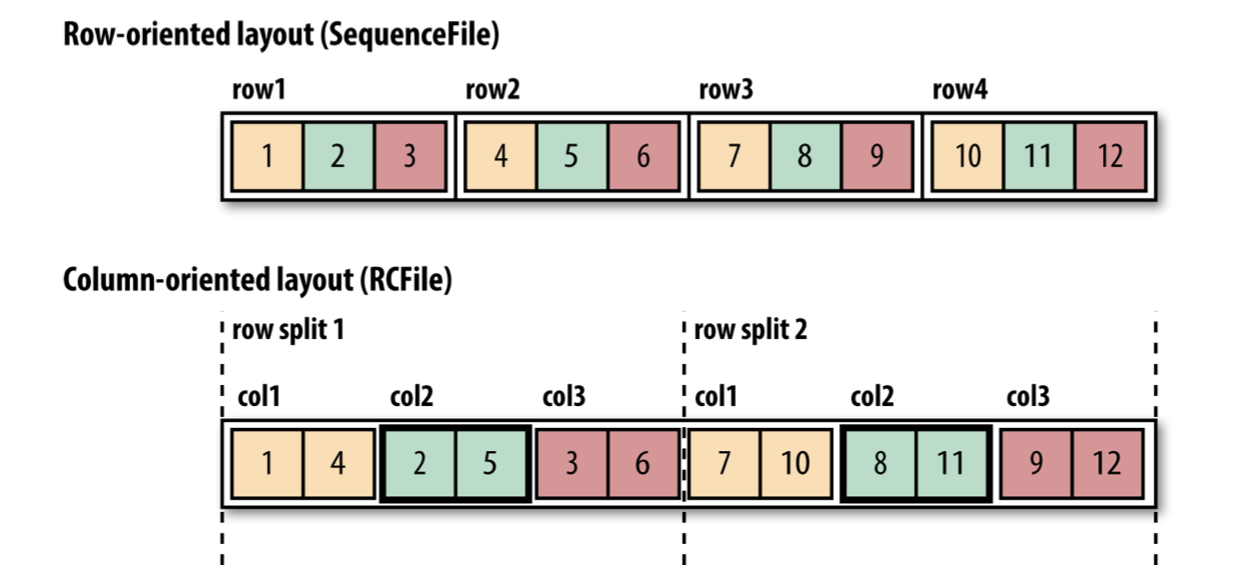
만약 이 data들이 table의 데이터고 table에서 특정 column만 쿼리하는 과정을 생각해보자. 기존의 row 기반의 파일포맷은 관련있는 row를 모두 읽어 메모리로 읽어들인 후에 이들을 역직렬화하여 column을 뽑아내야한다.
하지만 column based 파일포맷은 직접 필요한 소수의 column만 읽어들일 수 있는 장점이 있다.