HBase 기초
HBase Data Model
HBase의 데이터 모델부터 보도록 하자.
Table
HBase는 데이터들을 table안에 구성한다. table 이름은 String으로 파일시스템 path로 사용하는데 문제없도록 구성한다.
Row
Table 안에서 데이터는 table의 row에 따라 저장된다. Row는 rowkey에 의해 유일하게 식별되고 rowkey는 다른 data type을 가지지 않고 byte[]로 구성된다. 한개의 Row는 한개 혹은 여러개의 record로 구성된다.
Column Family
HBase에서의 column들은 Column Family 라고 부르는 일종의 그룹에 속한다.
HBase의 테이블은 최소한 한 개 이상의 column family를 가져야 한다.
Row의 record들은 column family로 그룹화된다. Column Family는 중요한데 HBase에서 데이터 저장에 있어 물리적인 특성과 관련이 깊다. 각 column family 마다 storage 관련 속성(caching 여부, 압축여부 등)을 지정할 수 있다.
Column Qualifier
column family 안의 데이터들은 column qualifier를 통해 표현된다. 만약 column family가 info 라면 column qualifier는 info:name 나 info:email 등이 될 수 있겠다. column qualifier는 미리 정의되어있을 필요가 없으며 각 row들마다 일관성없이 다른 column qualifier들을 가질 수 있다.
Column Qualifier은 그냥 column 이라고도 불리고 qual 이라고도 불린다.
Cell
Cell은 rowkey, column family, column qualifier의 조합이다. 이 조합이 cell을 식별한다. 이 cell에는 value로 데이터가 저장되어있고 version을 의미하는 timestamp도 포함한다.
Version
Cell 내부의 value들은 version 별로 저장이 된다. version은 long 타입의 timestamp이며 이 값을 따로 지정하지 않으면 현재 timestamp 값으로 설정된다. HBase에서 각 column family 마다 cell 마다 유지되는 version 개수를 설정할 수 있으며 기본값은 3이다.
위의 6가지 개념에 대해 이해한다면 앞으로 HBase를 이해하는데 크게 도움이 된다. 다음 그림을 보자.
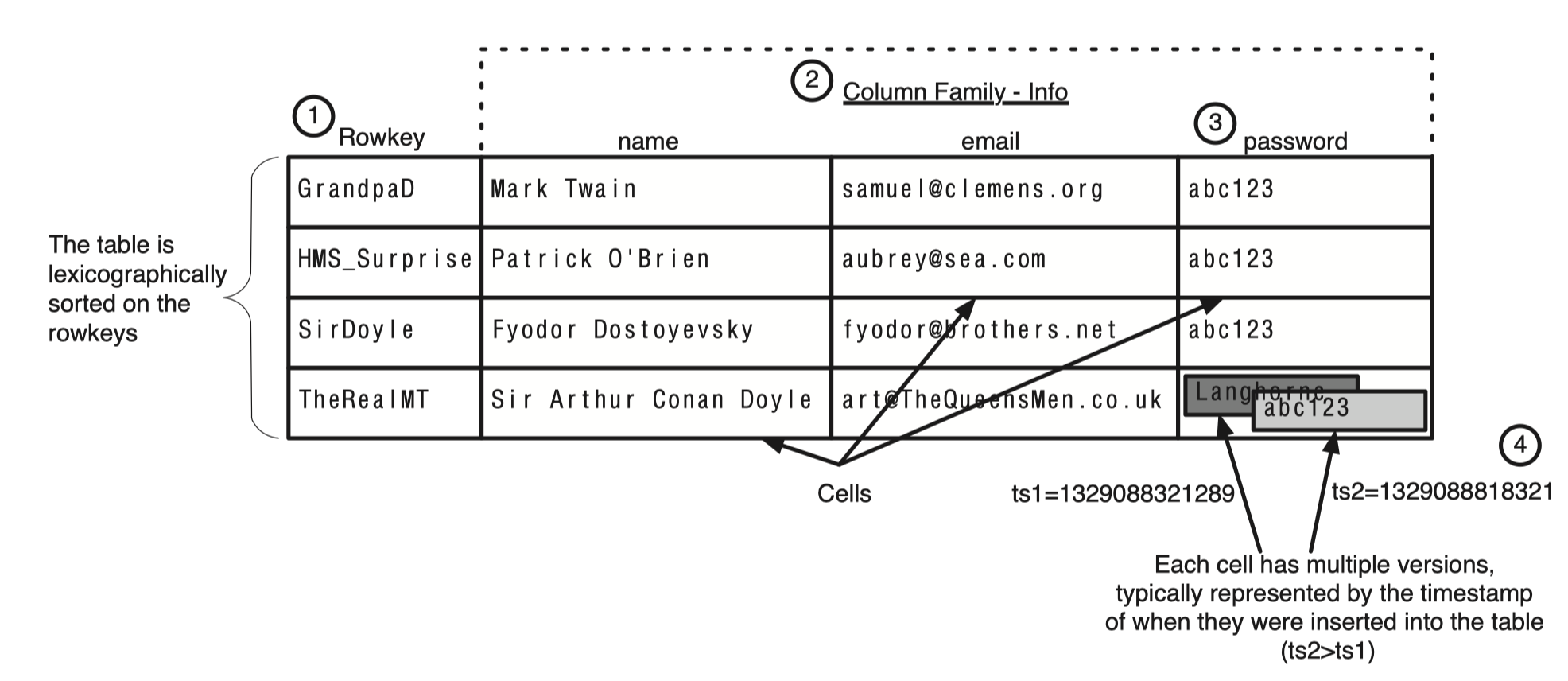
각 row는 한개 이상의 cell들로 구성되어있고 각 row는 rowkey를 기준으로 정렬되어있다.
각 cell에는 여러개의 version이 저장되어 있는 것도 확인할 수 있다.
Cell Coordinate
HBase에서 cell 값은 coordinate에 의해 접근된다. 말 그대로 좌표라는 의미이다. coordinate는 rowkey, column family, column qualifier 순서의 조합이다.
논리적인 그림으로 생각했을때에 결국 HBase는 coordinate를 key로 각 coordinate의 데이터를 value로 가진 key-value 저장소로 생각할 수 있다.
HBase에서 데이터를 얻기위해 Get 요청을 할때 coordinate 정보 전체를 제공하지 않아도 된다. 만약 rowkey, column family, column qualifier로 요청한다면 version 별 map을 결과로 얻을 수 있다.
Cell Key
HBase에서 cell key는 rowkey, column family, column qualifier, version 의 조합이다. 밑에서 보게되겠지만 HBase는 HFile 이라는 형식으로 데이터를 저장하는데 HBase의 cell key는 이 HFile의 key 이고 이 cell key로 정렬이 되어있다.
HBase는 엄격한 데이터 규칙이 없는 semi-structured 데이터들을 위해 설계되었다. 이런 semi-structured 논리 모델로 데이터들은 각 데이터 컴포넌트들 간의 느슨한 연결을 가지도록 하고 이런 구조로 물리적으로 scale을 쉽게 해준다.
애초에 HBase는 scale을 염두에 두고 설계되었고 이런 결정이 물리모델에 영향을 끼치고 있다. 다만 이런 물리적 모델 특성으로 RDBMS에서 제공하는 multirow transaction을 지원하지 못한다. 밑에서 HBase의 논리적 모델과 물리적 모델을 살펴보자.
Logical Model
HBase가 논리적으로는 어떤 모델을 가지고 있는지 이해하면 HBase를 쉽게 이해할 수 있다.
HBase는 맵들의 정렬된 맵(sorted map of maps)이라고 바라볼 수 있다. 먼저 다음 그림을 보며 이해해보자.
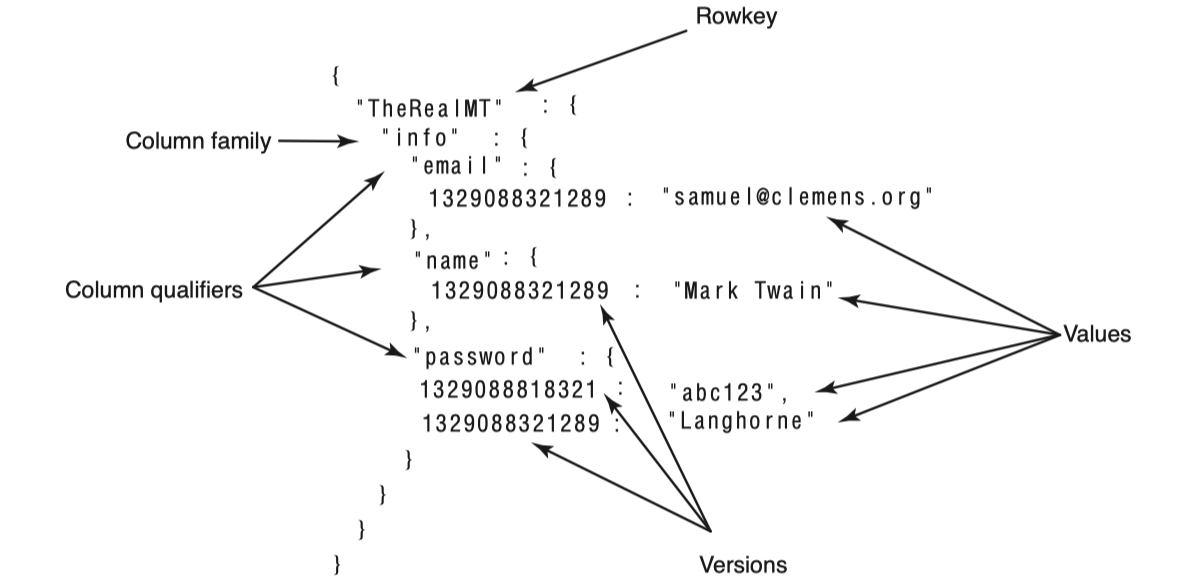
이처럼 논리적으로 데이터를 map 구조로 표현할 수 있다. 이는 “TheRealMT” 라는 rowkey의 데이터를 가지고 온 내용이다.
Map을 자세히 보면 map의 가장 안쪽에서는 cell의 version이 key이고 저장된 데이터가 value이다. 그 한단계 위에서는 column qualifier가 key이고 cell이 value이다. 결국 이를 자바로 표현하면 이와 같을 것이다.Map<RowKey, Map<ColumnFamily, Map<ColumnQualifier, Map<Version, Data>>>>
또하나 주목할 점은 sorted map이라는 것은 key로 정렬되어있다는 것이다. 위 예제에 password는 2가지 version이 존재하는데 항상 새로운 version이 더 앞에오도록 정렬되어있다. HBase는 내림차순으로 version timestamp을 정렬한다. 그러므로 최근 version에 대한 빠른 접근을 가능하게 한다. version이 아닌 다른 key들은 모두 오름차순으로 정렬되어있는 것을 확인할 수 있다. 이런 특징은 schema 설계시 매우 중요하다.
Physical Model
HBase는 HFile에 key-value 형식으로 저장이 된다. 위에서 보았던 “TheRealMT” 라는 rowkey를 가진 데이터는 다음과 같이 HFile에 저장된다.

이처럼 row 1개는 HFile 안에서 여러개의 record로 이루어져 있다. 또한 사용되지 않거나 null인 record가 없다. HBase는 데이터가 없을시에는 아예 아무것도 저장하지 않는다.
또 한가지 주목할 점은 HFile은 column family 별로 따로 생성된다. 하지만 같은 column family를 가진 single row도 동일한 HFile에 같이 존재하지 않을 수 있다. 이미 존재하는 rowkey에 새로운 column qualifier로 데이터를 넣는과정을 예시로 들 수 있겠다. 그러므로 single row 전체를 다 읽으려면 모든 HFile을 다 확인해야한다.
각 column family 별로 별도의 HFile을 사용하므로 HBase는 read 수행시 요청된 column family에 해당하는 HFile들만 읽으면 된다. 이런 물리적인 특성들은 storage를 더 효율적으로 사용하고 빠른 읽기를 가능하게 한다.
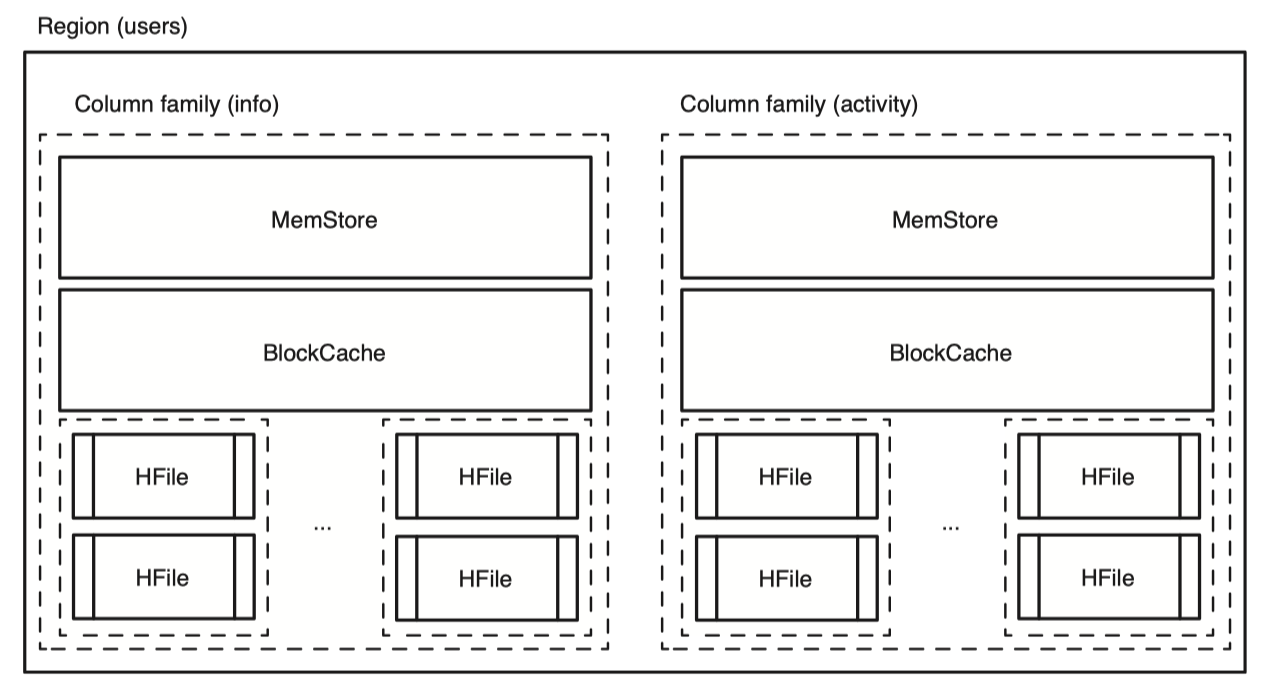
위 그림처럼 새로운 column family인 “activity”를 추가했다고 해보자. 이는 더 많은 HFile을 만들어내고 기존의 “info” column family와는 격리되어있고 전혀 다른 HFile을 만들어 내고있다. activity column family 내의 데이터가 커져도 info column family 성능에는 영향을 주지 않는다.
Data in HBase
HBase 테이블의 모든 row는 rowkey라는 유일한 식별자를 가지고 있다. 이는 테이블 내에서 유일한 값이다.
HBase에 저장된 모든 데이터들은 byte array 형태의 raw data로 저장된다. 자바 클라이언트 라이브러리에서는 이를 위해 Bytes 클래스를 제공해 다양한 형태의 데이터를 byte array로 바꿀 수 있다.
위에서 보았듯이 cell은 [rowkey, column family, column qualifier] 좌표로 결정된다. 밑의 예제를 한번 보자.
1 | |
여기서 Put 객체를 만들었는데 이는 새로운 data를 저장할때나 기존에 존재하는 row를 수정할때 사용한다.
여기서는 info라는 column family에 속한 name, email, password라는 column에 값을 설정했다. 이름을 저장하고 있는 cell의 coordinates는 [TK-one, info, name] 이다.
HBase write
새로운 row를 만들때나 기존 row를 수정할때나 내부 프로세스는 동일하다.
HBase는 command를 받으면 변경사항을 저장하고 만약 저장에 실패했으면 예외를 발생시킨다. 변경사항을 저장할때 기본적으로 두곳에 변경사항을 저장한다.
첫번째는 WAL(Write Ahead Log)에 저장한다. 이는 HLog라고도 불린다. 두번째는 MemStore에 저장한다.
HBase는 기본적으로 data의 내구성을 위해 두곳에 모두 저장한다. 두곳에 모두 저장해야 write가 완료된다.
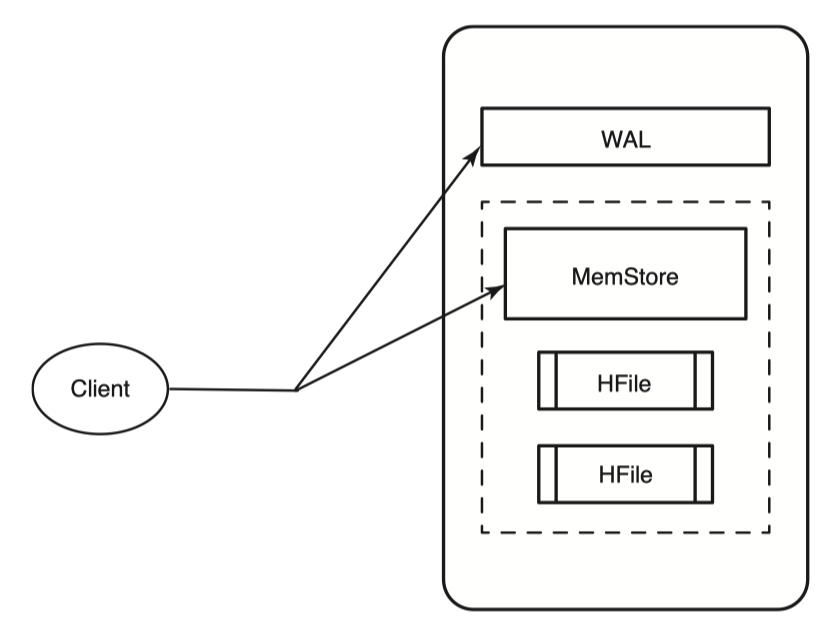
Memstore는 HBase에서 disk에 write하기 전에 HBase 메모리에 데이터를 모아놓은 buffer이다. 나중에 Memstore가 가득차게되면 HFile이라는 형태로 disk에 flush된다. 이미 존재하는 HFile에 append하는게 아니라 매 flush 마다 새로운 파일을 만든다. 여기서의 HFile은 HBase에서 사용하는 storage용 format이라고 생각하면 좋다.
HFile은 1개의 column family에 속해있다. 즉 하나의 HFile은 여러개의 column family로 이루어진 데이터를 가질 수 없다. Column family 당 1 개의 Memstore를 가지고 각 Memstore들은 가득차면 HFile로 flush 된다. 이 HFile도 HDFS에 저장된다.
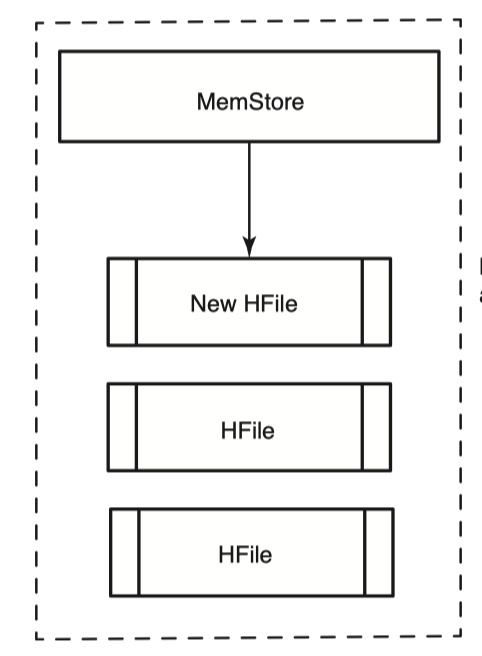
HBase에도 장애가 발생할 수 있다. 만약 서버가 다운되어 in-memory data를 모두 잃었을때는 아직 flush되지 않은 Memstore의 내용은 모두 유실될 것이다. HBase는 write 시에 WAL(Write Ahead Log)에 data를 write 하기때문에 이 WAL를 다시 replay 함으로서 MemStore 내용을 복구할 수 있다. HBase는 모든 변경사항을 WAL에 쓴다. 그리고 HBase는 이 WAL을 HDFS에 쓴다.
HBase의 Region 서버가 다운되어도 WAL을 HDFS에 썼다면 replica 3개중 아무곳에서 데이터를 제공받아 recover 할수있다. 만약 WAL이 Region 서버의 local disk에만 제공된다면 data loss가 발생할 수 있으므로 HDFS에 write 한다.
이 말고도 HDFS는 HBase Region 서버들에게 단일 namespace 파일시스템으로서 역할을 하기때문에 모든 Region 서버들은 다른 Region 서버들이 쓴 데이터들을 모두 볼 수 있다. 그러므로 Region 서버 장애시 다른 Region 서버에서 손쉽게 해당 WAL을 읽어 복구가 가능하다. 그러므로 Region 서버의 설계자체를 조금 더 간단하게 할 수 있는 장점이 있다.
WAL에 recording이 성공해야 write operation 이 성공했다고 간주한다.
WAL은 HBase 서버당 한개씩 존재하고 그 서버의 모든 table들이 이를 공유한다.
HFile
HBase는 random access를 지원한다. HDFS 위에서 어떻게 이를 가능하게 할까? 이를 위해서는 HFile를 이해해야한다.
먼저 HFile을 알아보기 전에 Hadoop의 파일기반 자료구조인 SequenceFile과 MapFile에 대한 개념이 있어야한다. 해당 내용은 Hadoop 파일기반 자료구조(SequenceFile, MapFile)에 정리해놓았다.
HBase 버전 0.20 이전까지는 데이터를 저장하는데 Hadoop의 MapFile을 사용했다. MapFile은 SequenceFile의 확장판으로 data 파일과 index 파일을 포함하고 있는 디렉토리이다. MapFile의 데이터는 key를 기준으로 정렬된 key-value 데이터이고 매 구간의 key를 index에 offset과 함께 저장해놓음으로서 index scan만 함으로서 fast lookup을 가능하게 한다.
HBase with MapFile
초기버전의 HBase는 MapFile을 사용했는데 key로는 rowkey, column family, column qualifier, timestamp, type으로 구성했다. value로는 row 내용이 들어갈 것이다.

여기서의 type은 해당 row가 삭제되었는지를 나타내는 flag인데 이는 밑에서 자세히 알아볼 것이다.
위와같이 MapFile을 구성하면 만약 row를 수정하면 어떻게 다음 조회에 수정된 내용을 반환할 수 있을까? 같은 row중 더 큰 timestamp를 가진 row를 반환할 수 있겠다.
MapFile에서의 data 파일은 반드시 key로 정렬이 되어있어야 한다. 하지만 HBase에 write하는 데이터는 정렬된 순서로 도착하지 않는다. 이를 해결하기 위해 위에서 보았듯이 HBase는 write command시 MemStore에 데이터를 저장하고 있다가 가득차면 flush 한다. MemStore는 ConcurrentSkipListMap과 동일하므로 이미 key로 정렬되어있다. 이를 MapFile로 flush하고 해당 MapFile은 더이상 수정하지 않는다. 그러므로 데이터를 찾을때에는 모든 MapFile을 대상으로 검색해야한다. 이는 성능에 좋지않으므로 성능을 개선하는 방법을 밑에서 자세히 알아볼 것이다.
HFile version 1
HBase 0.20 버전부터 HBase는 MapFile을 사용하지 않고 직접 구현한 MapFile과 비슷한 HFile 이라는 파일기반 자료구조를 사용한다.
HFile은 MapFile과 유사하지만 index를 다른 파일로 분리하지않고 같은파일에서 관리하도록 하며 여러 metadata를 담을 수 있다.
HFile 내부에는 data block이 여러개가 존재한다. 여러개의 연속된 data block들이 존재하고 index도 같이 존재한다. 이 data block에는 실제 key-value 데이터를 담고있다. 각 data block의 첫번째 key가 index에 기록된다. data block은 기본설정으로 64KB의 크기를 가진다.
각 HFile의 data block에는 HBase cell 들이 KeyValue 형태로 연속해서 저장되어 있다.
아래는 HFile version 1의 구조이다.
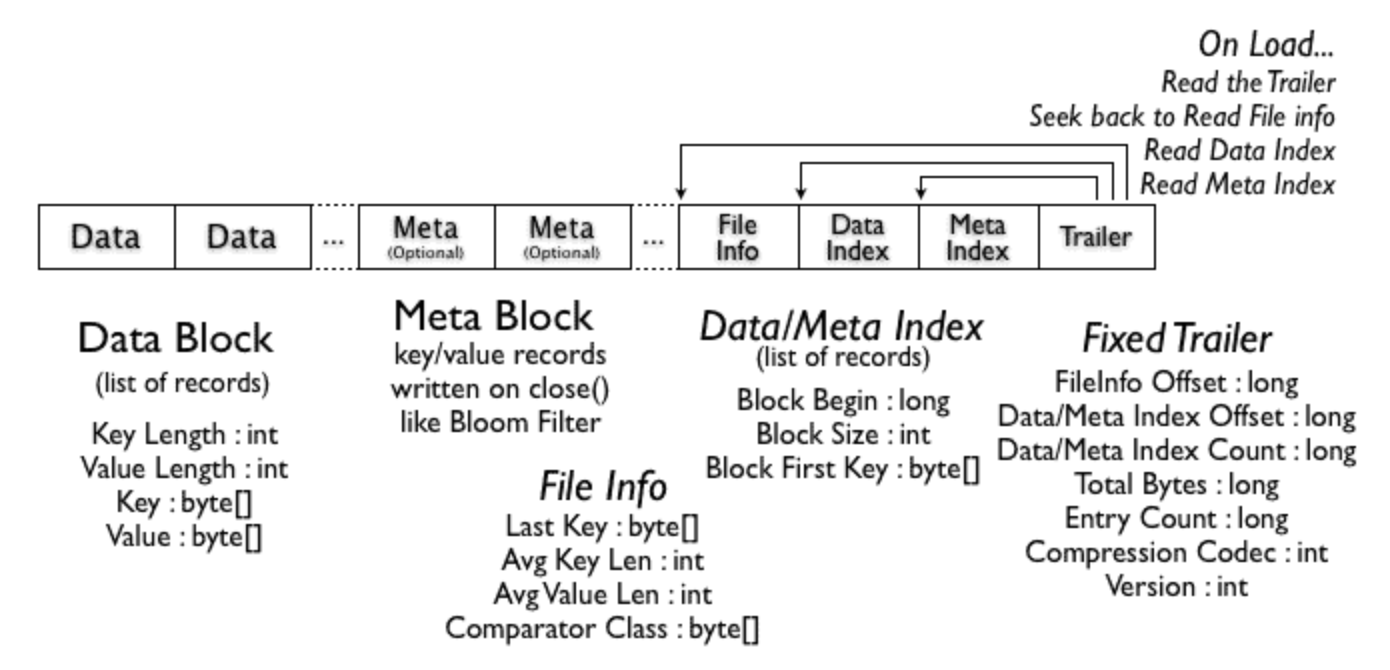
Block index에는 각 entry마다 block의 size, key 정보 등이 들어있다. HFile에는 위와같이 metadata를 담는 block인 Meta Block과 File Info 가 존재한다. version 1에서는 이 Meta Block을 Bloom Filter 정보를 담는데에 활용하였다. data scan시 해당 data가 이 HFile에 있는지 bloom filter를 활용하면 빠르게 판단할 수 있는데 bloom filter는 false positive가 발생한다. 그래서 HFile이 너무 오래되었는지 확인하기위한 Max SequenceId, Timerage 등을 File Info에 저장해 false positive를 한번 더 필터링한다.
HFile version 2
HBase 0.92 버전에서는 많은 데이터가 저장될 때 성능개선을 위해 HFile 형식이 조금 변경되었다.
위의 HFile version 1에서는 데이터를 읽기 위해서는 해당 HFile의 전체 데이터 정보를 담고있는 단일 index와 bloom filter를 메모리에 모두 올려놓아야 했다. 이를 개선하기 위해 HFile version 2 에서는 bloom filter를 block 별로 두고, multi-level index를 사용하도록 개선했다.

HFile version 2 에서는 bloom filter block과 index block을 data block과 나란히 배치한다.
bloom filter block과 index block 모두 random read을 최적화하기위한 용도로 사용된다. index block은 index data로 빠르게 검색할 수 있도록 하며, bloom filter block은 해당 data가 있는지 없는지를 빠르게 필터링하는데에 사용된다.
Index block 에는 3가지가 있다. Root Index block, Intermediate Index block, Leaf Index block 이다.
Root Index block은 HFile을 읽을때 바로 memory로 올린다. Root Index는 각 entry가 Intermediate Index block을 가리킨다. 그리고 Intermediate Index의 각 entry는 Leaf index block을 가리킨다. 마지막으로 Leaf index block은 실제 data block 을 가리킨다. 이는 b+tree와 매우 유사한 구조이다.
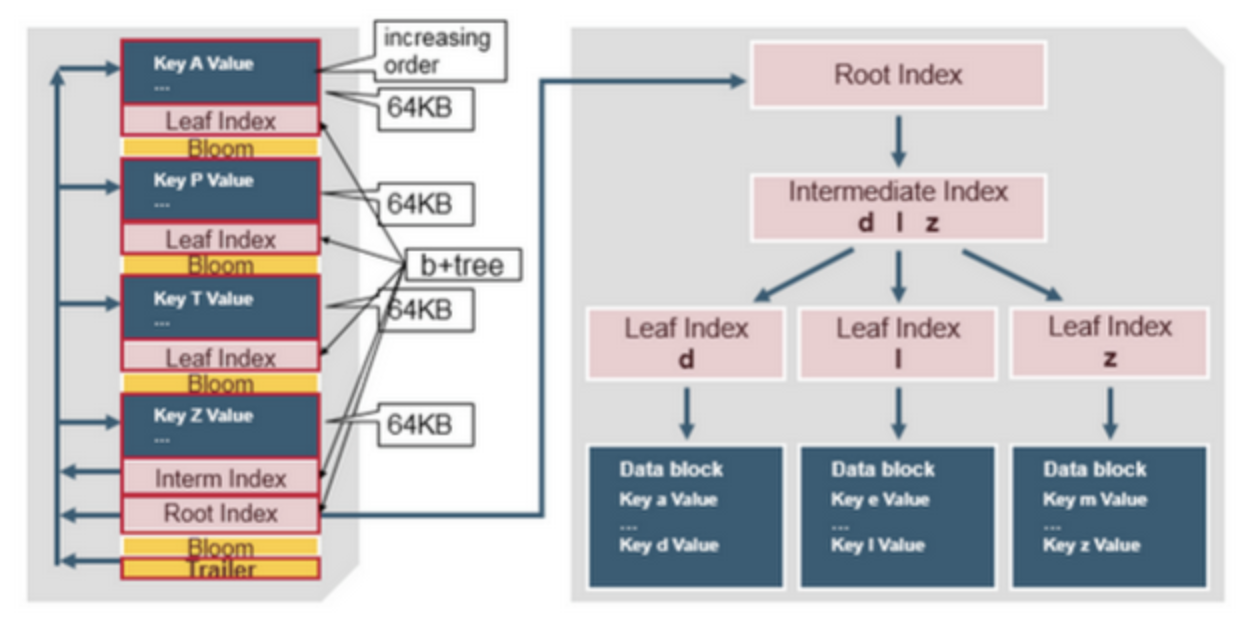
각 index entry에서의 key를 구성하는 것은 크게 두가지 방식이 있다. Rowkey-based index 와 Column-based index 이다.
Rowkey-based index 는 HBase 의 built-in 인덱스 방식으로 rowkey 를 기반으로 특정 row를 빠르게 찾도록 도와준다. rowkey-based index 는 key로 rowkey를 포함한다.
Column-based index 는 HBase 의 secondary index 구현에 사용된다. 이는 특정 column qualifier 값의 질의를 빠르게 매칭하는데 사용한다. column-based index 는 index table 이라고 불리는 HBase 의 또다른 테이블에 저장된다. index table 구조는 HBase 의 테이블과 유사하며 동일한 rowkey 와 column 을 사용한다. 하지만 value 는 기존의 테이블의 부분만 가지고있다.
따라서 특정 쿼리에서 column-based index 를 사용해야한다고 판단할때는 index table 을 보고 일치하는 row를 먼저 골라낸다. 그 다음 해당 row를 실제 main table 에서 찾는다.
따라서 특정 column qualifier value를 조회할때에는 column-based index 가 조회가 필요한 row 만 필터링해줄 수 있으므로 성능향상을 가져올 수 있다.
HFile block
HBase 에서 조회를 할때 조회해야하는 row가 포함되어있는 HFile block을 찾는다. 이는 index 에서 rowkey로 검색하여 찾을 수 있다.
그리고 그 HFile block을 rowkey를 활용해 찾으면 이 block 전체를 메모리에 올린다. 이들은 정렬되어있는 key-value 쌍이므로 binary search 로 원하는 row 조회 및 특정 column qualifier 조회를 수행할 수 있다.
Data block에도 header를 포함한다.

header에는 Block Type을 포함하여 해당 block이 data block인지 Index 인지 다른 내용인지를 구별하도록 한다. 또한 이전 block의 offset도 저장하여 빠른 backward seek을 가능하도록 한다.
HBase는 이처럼 데이터를 HFile이라는 큰 파일에 저장한다. 보통 HFile은 몇백 MB 부터 시작해 GB 단위로 커져간다.
HBase read
HBase의 read는 쉽다. 먼저 Get command instance를 통해 읽고싶은 cell을 지정하고 table에 보내면 된다.
1 | |
table은 Result 객체를 반환하는데 이 객체는 해당 row의 모든 column family의 모든 column 들을 포함한다. 다만 이는 우리가 필요한 데이터보다 더 많을수 있으므로 구체적으로 얻고싶은 column만 명시를 할수도 있다.
1 | |
위에서는 addColumn() 메서드를 통해 원하는 column을 명시했지만 addFamily() 메서드를 활용하면 해당 column family의 전체 column을 가져올 수도 있다.
HBase는 대부분의 읽기를 millisecond 단위로 제공한다. 보통의 일반적인 방법과 같이 HBase도 빠른 data access를 위해 data를 정렬된 상태로 유지하고 memory에 많이 올려놓는다. 그리고 위에서 설명하였듯이 write는 MemStore에 저장되지만 MemStore는 HFile로 flush되므로 read command를 처리하기 위해서는 HFile과 MemStore에서 적절하게 데이터를 잘 찾아야한다.
HBase는 BlockCache라는 LRU Cache를 내부적으로 사용한다. 이 BlockCache는 JVM heap에 MemStore옆에 위치한다. BlockCache는 HFile에서 자주 접근되는 data들을 캐싱해서 in-memory hit를 하고 disk read를 줄이기 위한 목적이다. 각 column family마다 BlockCache를 가지고있다.
HBase를 최적의 성능을 내도록 하기위해서는 BlockCache를 이해하는게 중요하다.
BlockCache
BlockCache의 Block은 HBase에서 disk에서 한번에 읽는 데이터 단위이다. 위의 HFile 에서의 data block이 이것이다.
HBase가 데이터를 읽기위해 HFile을 뒤져야할때는 HFile의 index 를 보고 binary search를 통해 key를 포함하고 있는 block의 위치를 알아낸 뒤 그 block(64KB)를 HDFS로 부터 읽어낸다. block size는 column family 별로 다르게 설정될 수 있으며 기본값은 64KB이다.
만약 Application이 HBase에서 random lookup이 많다면 block size를 작게하는게 도움이 될 수 있다. 반면 block size가 작아지면 block의 개수가 많아지므로 index는 조금 더 커질 것이다. sequential lookup이 많다면 block size를 반대로 크게 하는게 도움이 된다.
BlockCache는 기본적으로 enable 된다. 즉 모든 read operation은 그에 연관된 block을 BlockCache에 올릴것이다. BlockCache는 내부적으로 block들의 종류에 따라 evict 정책을 다르게 가져간다.
예를들어 hbase:meta table 내용은 최대한 BlockCache에서 evict 되지 않도록한다.
HFile의 index 들도 BlockCache에 올라가는데 자주 사용되지 않는 index들은 evict된다. HFile index들은 multi-layered index로 HBase에서 data를 찾을때 빠르게 찾을 수 있도록 도와준다. 이 말고도 BloomFilter도 활성화되어있다면 BlockCache에 올린다.
기본적인 key-value data 들도 당연히 BlockCache에 올라간다.
같은 데이터를 여러번 접근하는 패턴은 BlockCache의 이득을 최대로 볼 수 있다.
HBase에서 row를 읽을때에는 먼저 MemStore를 확인한다. 그 다음 BlockCache를 확인하고 해당 row가 BlockCache에 올라와있는지 확인한다. 최근에 row가 접근된 적이 있다면 BlockCache에 존재할 확률이 높다. 만약 BlockCache에도 찾지못한다면 그때 관련된 HFile들을 확인한다. 이때에는 disk read가 발생한다. 완전한 row를 찾기위해서는 모든 HFile을 뒤져야한다.
HBase delete
Delete는 HBase의 데이터를 저장하는 방식과 비슷하게 작동한다. 먼저 Delete를 하려면 Delete command의 인스턴스를 생성해야한다.
다음은 rowkey를 명시하여 해당 row를 삭제하는 코드이다.
1 | |
row 자체를 전부 삭제하는게 아닌 특정 coordinate를 명시해서 해당 cell만 삭제할 수도 있다.
1 | |
실제 삭제는 어떻게 진행될까?
실제로 Delete command는 해당 값을 바로 삭제하지 않는다. 대신에 해당 record가 삭제되었다는 마킹만 한다. 이는 HFile을 생각해보면 당연한 설계이다. HFile은 immutable하다. 그러므로 애초에 record를 수정하거나 삭제할 수가 없다. 그러므로 해당 record가 삭제되었다는 새로운 record를 write한다. 이를 tombstone 이라고 한다. 그래서 보통 HBase 에서 삭제한다고 하면 tombstone marking을 했다고 표현한다.
이 tombstone mark는 Get이나 Scan을 할때 해당 record가 결과에 포함되지 않도록 보장한다. 실제 삭제가 되었어야 하는 original 데이터는 계속해서 HFile에 남아있을 수 밖에 없는데, 이런 데이터들은 밑에서 볼 major compaction 단계에서 제거된다.
HBase Compaction
Memstore가 어느정도 크기에 도달하거나 Region 서버가 Memstore에 너무 많은 메모리를 쓰고있다고 판단되면 Memstore는 flush를 하여 새로운 HFile을 만들어낸다고 했다.
매 flush마다 새로운 HFile이 생성되므로, 우리는 Get과 Scan을 수행할때 key를 찾기위해 해당 요청과 관련있는 모든 HFile을 다 뒤져봐야하므로 이는 성능이 좋지않다. 즉 HFile의 개수를 제한하는 것이 성능에 매우 중요한 부분을 차지한다. 이를 극복하기위해 HBase는 HFile의 개수가 특정개수를 넘어갈때 Compaction을 진행하여 여러개의 HFile을 하나의 큰 HFile로 병합한다.
HBase의 compaction에는 2가지 종류가 있다. Minor Compaction과 Major Compaction이다.
Minor Compaction
minor compaction은 간단하다. 작은 HFile 여러개를 하나의 큰 HFile로 합친다. minor compaction 과정은 HBase에 성능저하를 최소한으로 있도록 설계되었기 때문에 minor compaction 대상이되는 HFile 개수는 상한선이 있다. 이 값은 설정값으로 조정이 가능하다.
minor compaction은 작은 HFile 들로부터 record를 읽어 이들을 정렬하고 큰 HFile에 새로 write한다. 과정은 다음 그림과 같다.
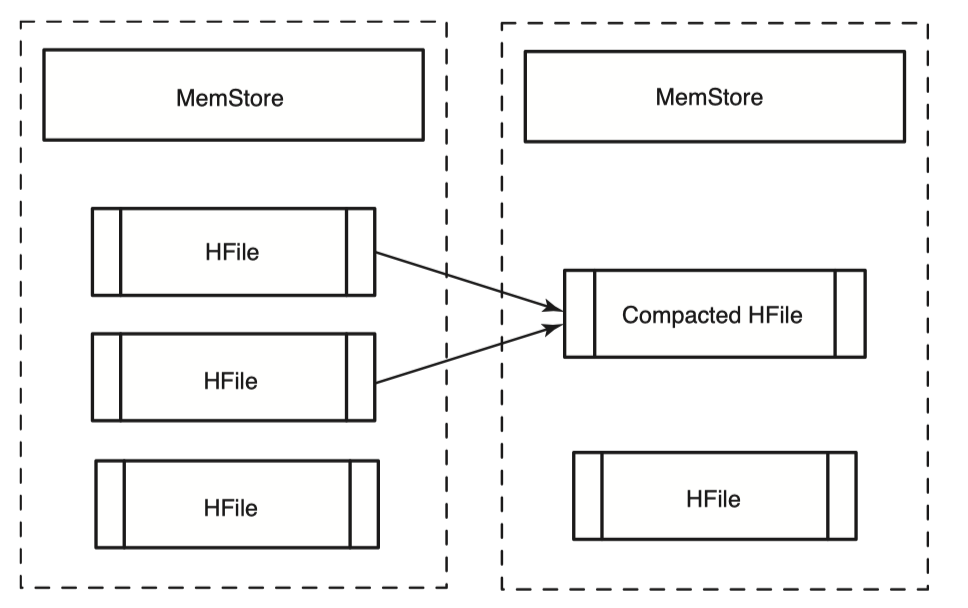
Major Compaction
major compaction은 column family의 모든 HFile를 대상으로 수행되는 compaction이다. major compaction이 완료되면 해당 column family의 모든 HFile들은 하나의 HFile로 병합된다. 이 major compaction은 비용이 비싸므로 자주 일어나지 않는다. 다만 minor compaction은 빈번하게 일어난다.
major compaction 단계에서는 tombstone marker로 표시해둔 record를 완전히 삭제한다. 또한 tombstone marker record 자체도 같이 삭제한다.
왜 minor compaction은 이와같은 deleted mark record를 삭제하지 못할까?
실제로 삭제대상의 record가 있는 HFile과 tombstone marker record가 있는 HFile은 다를 수 있고 삭제대상의 record가 어느 HFile에 있는지 모르기 때문이다. minor compaction은 작은 몇개의 HFile을 대상으로만 진행된다. 그러므로 major compaction에서 이를 담당한다.
HBase data locality
HBase는 HDFS로부터 HFile을 읽을때 어느 node에서 읽을까?
이를 위해서는 먼저 HBase와 HDFS가 같은 cluster에 있는지 확인해야한다. 만약 같은 cluster에 없다면 HFile은 항상 HBase의 Region server와 다른 노드에 있으므로 network 비용이 발생한다.
만약 같은 cluster에 존재한다면 Region Server가 HDFS에 HFile을 쓸 때 HDFS는 가능하면 그 파일을 쓰는 datanode에 replica가 저장될 수 있도록 해준다. 따라서 Region Server에서 HFile 접근시 local disk에 접근하므로 data locality를 보장할 수 있다.
만약 Region Server가 문제가 생겨 새로 서버가 시작되었다고 하더라도 처음에는 다른 HFile을 읽기위해 다른 HDFS datanode로 부터 파일을 읽어오겠지만, 충분한 시간이 지난다면 major compaction이 발생하고 결국 HFile을 새로 다시 쓰기때문에 이 부분에서 다시한번 data locality를 보장할 수 있다.
HBase 분산모드
HBase의 테이블은 row와 column으로 구성되어 있고 수십억개의 row와 수백만 개의 column으로 확장이 가능하다. 각 테이블은 petabyte 단위까지도 증가할 수 있다. 다만 단일머신에서는 이를 서비스하기 힘들다. 어떻게 이를 가능하게 할까?
HBase는 table을 작은 단위로 분할시키고 이를 여러 서버에 나누어 서비스한다. 이 작은 단위를 Region 이라고 부른다. 이 Region을 서비스하는 서버를 RegionServer 라고 한다.
일반적으로는 RegionServer 들은 HDFS datanode와 같은 물리적인 서버에 위치해 있다. 꼭 같은 물리서버에 위치해야할 필요는 없지만 locality를 얻기위해 그리고 성능최적화를 위해서는 같은 물리적 서버에 위치하도록 하는게 좋다. RegionServer 들은 HDFS의 입장에서는 HDFS를 사용하는 클라이언트중 하나이다.
HMaster라 불리는 process가 region을 할당하고 분배하는 역할을 수행하고 각 RegionServer는 일반적으로는 여러개의 Region을 서비스한다.
Region은 table을 rowkey를 기준으로 적절하게 범위를 나누어 할당된다. 다음 그림으로 Region의 분리를 볼 수 있다.
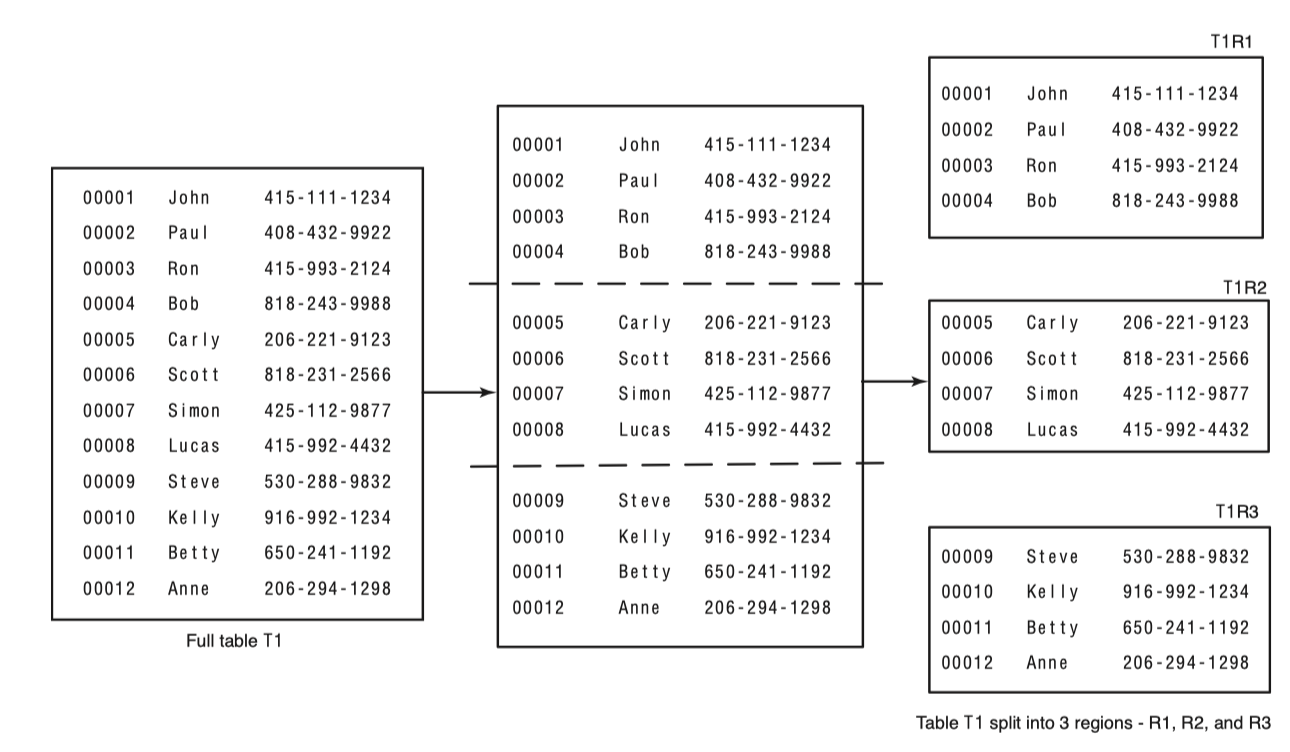
Region이 너무 커지거나 Region이 나누어져야 하는 특정조건을 만족하면 RegionServer는 Region을 다시 작은 크기로 쪼갠다.
client 가 특정 row에 접근하고자 할때는 어느 Region에 있고 이를 어떤 RegionServer가 호스팅하고 있는지 어떻게 알 수 있을까?
이 정보는 .META. 라는 HBase 내의 table이 도움을 준다. 실제 table 이름은 hbase:meta 이며 HBase의 모든 region 정보를 가지고 있다. 그리고 zookeeper가 hbase:meta table의 위치를 저장한다. .META. 테이블은 1개의 region으로만 사용하고 있다.
따라서 client는 특정 row에 접근할때 zookeeper로부터 hbase:meta region을 서비스하는 RegionServer를 알아내고, 이 .META. table 정보를 들고있는 RegionServer에 해당 rowkey를 어떤 region과 RegionServer 에서 제공하고 있는지 질의한다.
그에 대한 RegionServer 정보를 받으면 그 RegionServer로 해당 row의 읽기나 쓰기작업을 진행한다.