Hadoop HDFS란?
현 회사에서 Hadoop을 적극적으로 사용하고 있고 저장소로 HBase를 사용하며 MR(MapReduce)을 다루는 경우가 많기 때문에 Hadoop 관련 내용을 정리하면 좋겠다고 생각했다.
이 글을 읽기 전에 파일시스템 1편 - 하드디스크 를 먼저 읽으면 도움이 될 수 있습니다.
먼저 Hadoop distributed file system을 알아보자.

HDFS
HDFS는 Hadoop Distributed File System 의 약어다.
HDFS는 하둡의 대표적인 분산파일시스템이다. 그렇다고 하둡에서 꼭 HDFS를 사용해야하는 것은 아니다. 하둡은 범용 파일시스템을 추구한다. 하둡은 파일시스템의 추상화개념을 가지고있고 HDFS는 그 구현체 중 하나일 뿐이다.
데이터가 단일 디스크의 저장용량을 초과하면 이 데이터들을 쪼개서 여러개의 머신에 저장해야한다. 이렇게 여러개의 머신으로 파일을 저장하고 서로 네트워크로 묶으면 여러머신의 스토리지를 관리할 수 있는데 이를 분산파일시스템이라고 한다.
HDFS는 여러개의 머신으로 구성된 클러스터에서 실행되고 대용량 파일을 다룰 수 있도록 설계된 파일시스템이다.
HDFS는 petabyte단위의 파일을 다룰 수 있고 하드웨어는 항상 장애가 날 수 있는데 노드장애가 발생하더라도 대형 클러스터에서 문제없이 실행되도록 설계되었다.
HDFS는 기본적으로 빠른 응답시간을 요구하는 애플리케이션에는 맞지않다. 설계자체가 높은 데이터 처리량을 제공을 목표로 하기 때문이다. 빠른 응답시간을 원하면 HBase가 선택지가 될 수 있겠다.
그리고 HDFS는 파일을 생성하거나 파일 끝에 append하는 것은 가능하지만 파일 중간에 내용을 update하는 것은 불가능하다. 한번의 쓰기작업 그리고 여러번 읽는 방식이 가장 효율적인 방식이도록 설계되었기 때문에 데이터를 수정하려면 현재 데이터를 삭제후 수정한 데이터를 새로 생성해야 한다.
HDFS Block
여기서 말하는 block은 흔히 파일시스템에서 말하는 block을 말한다.
보통 우리가 아는 단일디스크에서의 파일시스템에서 사용하는 block는 4KB이고, 디스크 자체는 기본적으로 512KB의 sector size를 가진다.
이와같이 HDFS도 block 개념이 있는데 HDFS block은 size가 굉장히 크다.
HDFS block size는 기본적으로 128MB이며 보통은 이것보다는 큰 block size를 사용한다.
HDFS block이 큰 이유는 기본적으로 탐색비용(disk에서의 seek time + rotational delay)을 줄이기 위함이다. (SSD에서도 sequential read가 random read 보다 빠르다)
Disk seek 비용은 상당히 비싸다. Hadoop은 전체 dataset을 탐색하도록 설계되었기 때문에 큰 block size로 sequential read를 통해 성능을 크게 개선할 수 있다.
예를들어 position time(seek time + rotational delay)가 10ms 이고, disk 전송률이 100MB/s 일때 position time을 전송시간의 1%로 만들고 싶다면 block size를 100MB로 잡으면된다.(position time 10ms + 100MB 전송에 1초가 걸리므로)
또 만약에 block size가 작으면 파일에 대한 block의 개수자체도 많아질텐데 뒤에 보면 알겠지만 HDFS는 파일시스템 metadata를 메모리에서 관리한다. 그러면 모든 block에 대해 metadata를 들고 있어야 하는데 block 개수자체가 많아지므로 metadata가 너무 커지는 문제가 있다. 결국 block이 너무 많으면 오버헤드가 발생하고 네트워크 트래픽이 증가하는 문제가 발생할 수 있다.
HDFS에서의 파일은 우리가 단일디스크 파일시스템에서 파일을 저장할 때처럼 block size별로 chunk되어 저장된다.
다만 HDFS는 데이터가 block size보다 작을경우, 해당 block(128MB)을 모두 차지하지는 않는다(기본적인 단일디스크 파일시스템에서는 데이터가 4KB 보다 작아도 4KB block을 모두 차지한다). 그러므로 파일크기가 block size보다 작다고 공간이 버려지지는 않는다.
HDFS에도 block 개념이 있기때문에 여러가지 이점이 있는데 먼저 단일디스크에 있는 파일시스템에 다 담지 못하는 크기의 파일도 여러 block으로 나누어 여러 디스크에 저장할 수 있다. 그리고 block 단위의 추상화가 들어가면 스토리지의 subsystem을 단순화할 수 있고 metadata 관리가 편하다. 또 block은 fault tolerance와 availability를 제공하기 위한 replication을 구현하는데에 적합하다. block 마다 replicaion factor 개수만큼 여러머신에 중복저장하고 특정 노드에서 block을 읽을 수 없다면 다른 노드를 사용하게 할 수있다.
Namenode And Datanode
HDFS cluster는 master인 네임노드와 worker인 데이터노드로 구성되어 있다.
네임노드는 파일시스템 트리, 그리고 그 트리에 포함된 모든 파일, 디렉터리에 대한 metadata를 유지한다. 파일시스템에서 inode를 네임노드에서 관리하고 있다고 이해하면 좋겠다. 그리고 이 내용은 namespace image와 edit log라는 두 종류의 파일로 local disk에 영구히 저장된다.
네임노드는 모든 HDFS block이 어느 데이터노드에 있는지 모두 알고있다. 하지만 이 정보는 local disk에 영속 저장하지는 않고 시스템 시작시 데이터노드로 부터 받아서 재구성한다. 따라서 네임노드를 다른 것으로 교체할 때 전체 데이터노드에서 충분한 block report를 받아 안전모드를 벗어날때까지 요청을 처리할 수 없는데 이 시간이 30분이상 걸리기도 한다.
사용자가 직접 네임노드, 데이터노드와 통신해야 하는것은 아니고 이 모든 것을 HDFS client가 대신해서 이들에게 접근한다.
데이터노드는 HDFS client나 네임노드의 요청이 있을때 block을 저장하고 탐색하며, 주기적으로 저장하고 있는 block list들을 네임노드에 보고한다.
또 네임노드는 모든 파일과 각 block의 참조정보를 다 메모리에 들고있다. 그래서 대형 cluster에서는 메모리가 걸림돌이 되는데 이부분은 HBase Federation을 적용하여 해결할 수 있다. 이는 네임노드를 여러개두고 각 네임노드가 특정 namespace를 담당하도록 하는 것이다. 예를들어 어떤 네임노드는 /user을 관리하고 어떤 네임노드는 /bar를 관리할 수 있다. 그러면 특정 네임노드가 장애가 나도 다른 namespace의 가용성에는 영향을 주지 않는 장점도 있다.
HDFS는 네임노드가 정말 중요한데 네임노드가 장애면 시스템의 어떤 파일도 찾을 수 없다. 모든 block 정보를 이용해 네임노드가 파일을 재구성하기 때문이다. 그래서 네임노드의 장애극복은 필수적이며, Hadoop은 이를위해 2.x 부터 HDFS HA를 지원한다.
HA는 보조 네임노드를 운영한다. 네임노드를 Active-StandBy 구조로 한 쌍으로 구성하여 Active 네임노드에 장애가 발생할 경우 StandBy 네임노드가 이를 이어받는 방식이다.
File read
클라이언트가 HDFS의 파일을 읽을때 내부적으로 어떤 일이 일어나는지 살펴보자.
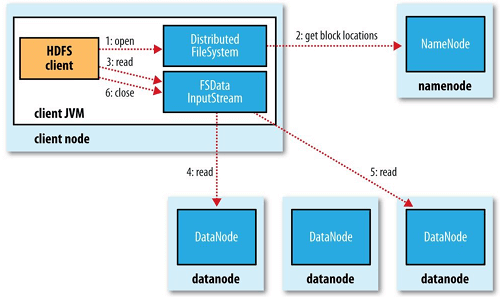
먼저 클라이언트는 hadoop에서 제공하는 FileSystem 객체의 open()을 호출하여 원하는 파일을 열어야한다. 그러면 해당 파일의 첫번째 block이 어디있는지 파악하기 위해 RPC로 네임노드를 호출한다. 그러면 네임노드는 block 별로 해당 block의 복제본을 가진 데이터노드의 주소를 반환한다. 이때 데이터노드의 순서는 cluster의 network topology에 따라 클라이언트에 가장 가까운순으로 정렬되어 반환된다. 예를들어 클라이언트 자체가 데이터노드고 해당 block의 복제본을 본인이 가지고 있으면 첫번째 데이터노드는 로컬이 될 것이다.
block 위치정보를 반환받으면 이 정보를 기반으로 데이터를 읽을 수 있도록 FSDataInputStream을 반환한다. 이는 스트림으로 클라이언트는 read 메서드를 호출하면된다. 그때 내부적으로 첫번째 데이터노드와 연결해 데이터를 전송받는다. 만약 block의 끝에 도달했으면 다음 block의 데이터노드와 연결해 데이터를 전송받는다. 이 과정은 내부적으로 일어나며 클라이언트는 스트림을 읽는것처럼 보인다.
만약 데이터노드와의 통신에 문제가 생기면 해당 block을 저장하고 있는 다음 데이터노드와 연결을 시도하고, 문제가 생긴 데이터노드는 네임노드에 report한다.
전반적인 읽기는 클라이언트가 데이터노드에 직접 접근하여 데이터를 읽어오고, 네임노드가 각 block의 데이터노드를 적절하게 알려준다. 이런 과정을 통해 File 읽기에 대한 트래픽은 모든 데이터노드에 고르게 분산된다. 네임노드는 모든 클라이언트의 요청을 처리해야하지만 메타데이터를 메모리에 저장하여 memory read로 끝나기때문에 많은 클라이언트의 요청을 동시에 처리할 수 있다.
File write
클라이언트가 HDFS의 파일을 쓰게될때 어떤 일이 일어나는지 살펴보자.
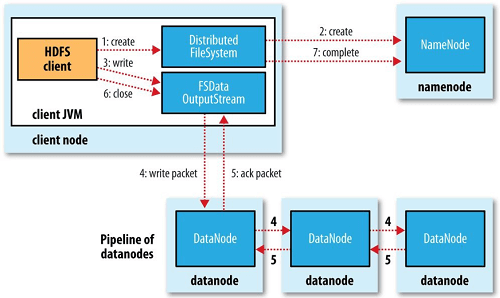
클라이언트는 DistributedFileSystem의 create() 메서드를 호출하여 파일을 생성한다. 그러면 네임노드에 RPC를 보내는데 이때는 파일생성권한이 적절하게 있는지 동일파일이 존재하는지 등 검사를 진행한다. 검사가 통과되면 새로운 파일의 레코드를 만들어 저장하고 반환한다. 이때 block 정보는 반환하지 않는다.
클라이언트는 file read와 마찬가지로 FSDataOutputStream을 반환받고 이를 스트림으로 write할 수 있다. 다만 쓸때는 read 과정과 조금 다르다.
클라이언트가 파일에 데이터를 쓸때에는 각 데이터를 패킷으로 나누어 분리하고 클라이언트의 내부 queue인 data queue라고 불리는 queue에 해당 패킷들을 쌓는다. 그러면 DataStreamer가 이 패킷들을 처리한다. 먼저 block을 어느 데이터노드에 써야하는지 모르므로, 네임노드로부터 복제본을 저장할 데이터노드 목록을 요청하고 반환받는다.
다만 이 데이터노드들은 pipeline을 형성하는데 replication factor가 3이라면 세개의 노드가 pipeline에 속한다.DataStreamer는 첫번째 데이터노드에 먼저 패킷들을 전송한다. 첫번째 데이터노드는 이를 저장하고 나서 이를 다음 pipeline의 데이터노드로 보낸다. 이어서 두번째 데이터노드는 다시 패킷을 저장하고 다음 pipeline의 데이터노드로 저장한다. 그림을 보면 이와같은 내용을 설명하고 있다.
클라이언트는 내부 패킷을 저장하는 ack queue를 들고있어 각 데이터노드로 부터 ack 응답을 전부 받으면 해당 패킷이 queue에서 삭제된다.
만약 데이터노드의 쓰기에 문제가 있다면 ack를 받지못한다. 그러면 장애복구작업이 시작되는데 ack queue에 있는 패킷들이 다시 data queue에 들어가서 재시도된다.
즉 file write는 비동기적으로 pipeline을 통해 데이터노드에 써주게되는데 dfs.namenode.replication.min에 설정된 개수의 데이터노드에만 block 저장이 성공하면 write은 성공한 것으로 반환된다. 기본값은 1 이다. 그리고 dfs.replication 값인 replication factor에 도달할때까지 클러스터에 걸쳐 복제가 비동기적으로 수행된다. replication factor의 기본값은 3이다.
클라이언트가 file write을 다했을때는 close() 메서드를 호출한다. 그러면 클라이언트는 데이터노드 pipeline으로 남아있는 모든 패킷을 flush하고 ack를 기다린다. 그 이후에는 네임노드에 file write이 완료되었음을 알린다. dfs.namenode.replication.min 만큼의 block이 복제가 완료되었으면 성공을 반환한다.
복제본 배치
네임노드는 복제본을 저장할 데이터노드를 어떻게 선택할까?
노드간의 쓰기 대역폭을 줄이기위해 단일노드에 모두 복제본을 배치하면 복제의 의미가 없다. 해당 노드가 장애시 data loss가 일어난다.
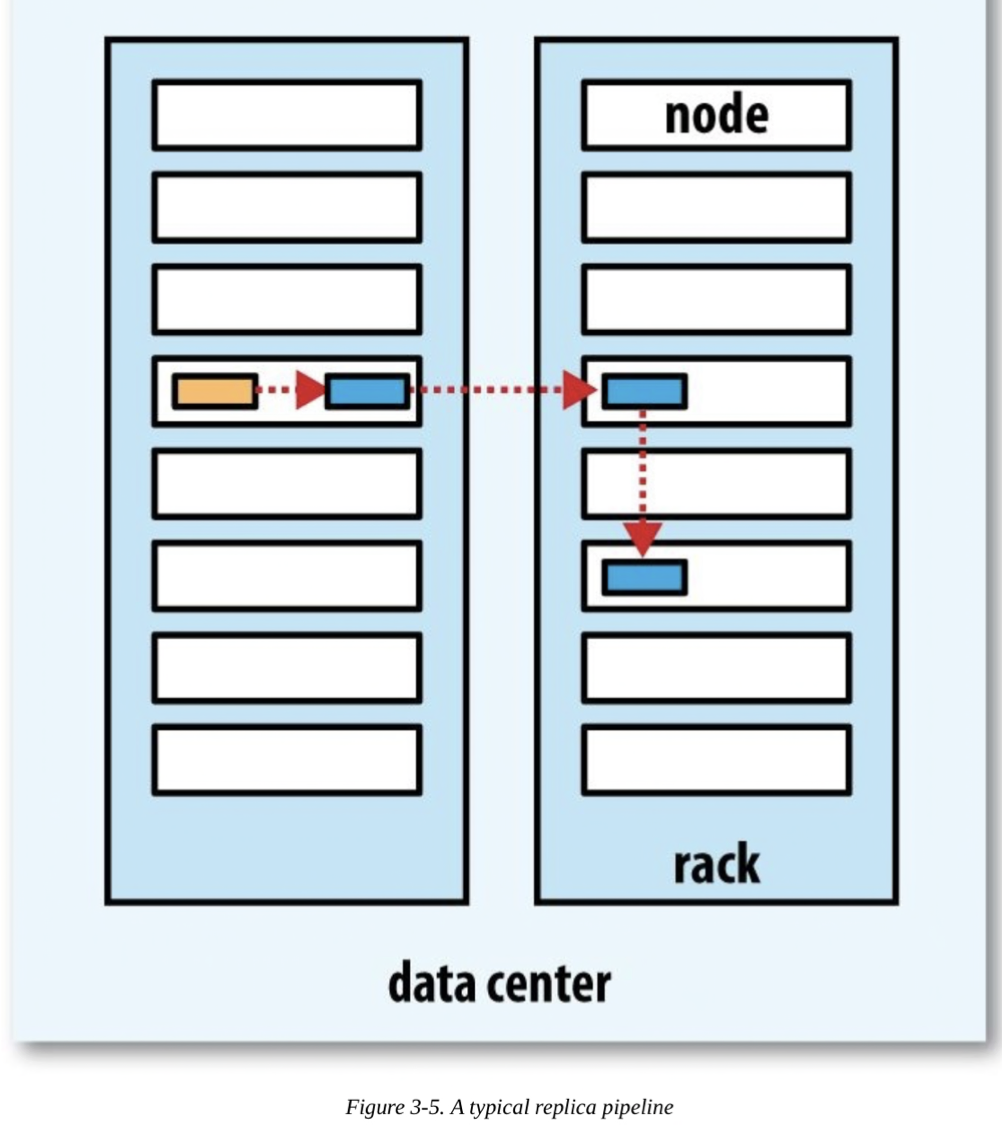
하둡에서는 첫번째 복제본은 클라이언트와 같은 노드에 배치한다. 그런데 클라이언트가 cluster 내부의 노드가 아니라면 무작위로 노드를 선택한다. 이 과정에서 노드들의 파일개수나 해당 노드의 자원상황을 고려한다.
두번째 복제본은 첫번째 복제본을 저장한 노드와 다른 랙에서 노드를 무작위로 선택한다. 세번째 복제본은 두번째 복제본이 저장되는 랙과 동일한 랙에서 다른 노드를 선택한다. 그 이상의 replication factor를 가졌다면 다음 노드들은 무작위로 선택한다.
하둡은 block을 두개의 랙에 저장함으로서 신뢰성을 가지고, 쓰기 대역폭은 하나 혹은 두개의 네트워크 스위치만 통하도록 설계되었다. 읽기 성능을 위해서도 두개의 랙중 가까운 것을 선택하도록 한다. 그리고 전반적인 cluster의 block 분산의 균형을 적절하게 맞춘다.
일관성 모델
일관성 모델은 coherence model 로 부른다. 이는 파일에 대한 read, write에 대해 visibility 가 어떻게 되는지 설명한다.
HDFS에서 파일을 생성하면 HDFS namespace에서 파일의 존재를 확인할 수 있다.
1 | |
하지만 파일을 write 할 때, 스트림을 flush 했다고 해서 해당 파일의 내용일 읽을 수 있음을 보장하지는 않는다.
다음 예제처럼 stream을 flush하고 읽었을때 파일의 내용이 비어있을 수 있다.
1 | |
일단 file의 데이터가 한 개의 block 넘게 기록이 되면, 그 file의 첫번째 block은 reader들이 볼 수 있다.
다만, 현재 쓰여지고 있는 block은 다른 reader 들에게 보이지 않을 수 있다.
HDFS는 모든 buffer들이 데이터노드들에 강제로 flush 할 수 있는 hflush() 라는 메서드를 제공한다.hflush()가 성공하면, HDFS는 write pipeline에 속한 모든 데이터노드들에 file write에 대한 요청이 도달했음을 보장해준다. 그러므로 모든 다른 reader들이 이를 읽을 수 있다.
1 | |
한가지 주의해야 할 점은 hflush()는 데이터노드가 해당 파일을 disk에 썼음을 보장하지 않는다. 오직 데이터노드의 메모리에 썼음을 보장한다. 따라서 hflush()를 호출했음에도 data center 장애가 일어나면 데이터 유실이 일어날 수 있다.
데이터노드에서의 disk write도 보장하고 싶다면 hsync()를 호출해야 한다.
hsync()는 POSIX의 fsync()와 같다. 파일시스템 편에서의 buffer cache를 flush 하기 위한 fsync()를 기억하라.
1 | |
HDFS에서의 close() 메서드는 내부적으로 hflush()를 호출한다.
이런 HDFS의 일관성 모델을 보고 애플리케이션의 디자인을 어떻게 해야할지 결정해야한다.hflush()나 hsync() 없이는 block의 저장을 보장할 수 없다. 하지만 이에도 tradeoff가 있다. hflush()는 비싼작업은 아니지만 그래도 오버헤드가 존재하고 hsync()는 비용이 더 비싸다. 애플리케이션에서 적절하게 일관성 모델을 정하고 그에 맞게 HDFS의 hflush와 hsync를 활용하여 성능과 데이터 신뢰성을 잘 결정해야 한다.