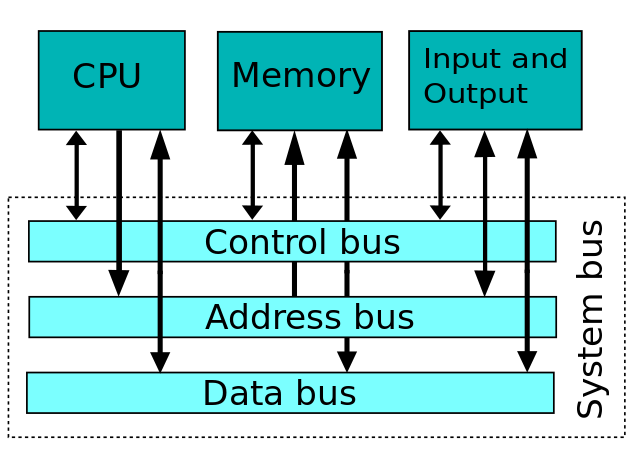
Bus에는 3가지 종류가 있다. Control Bus, Address Bus, Data Bus 이다. 이 3가지가 System Bus를 구성한다.
시스템버스는 internal bus로서 프로세서와 내부 internal 하드웨어 장치들과 연결하도록 고안된 버스이다. 시스템버스는 메인보드에 존재한다.
Bus의 종류를 하나씩 보자.
Control Bus
Control Bus는 CPU가 다른 internal device들과 통신하는데 사용된다. Control Bus는 이름부터 알 수 있듯이 CPU의 command를 전달하고 device의 status signal을 반환한다. Control Bus 안에는 line 이라는 것이 있는데, control bus마다 line의 개수와 종류가 각각 다르지만 공통으로 가지고 있는 line이 있다.
READ line: device가 CPU에게 읽히면 active된다.
WRITE line: device가 CPU에게 쓰여지고 있으면 active된다.
메모리에 읽고 쓸때에는 Control Bus의 Read, Write line이 활성화된다. Control Bus는 양방향으로 작동한다.
Address Bus
Address Bus는 memory에 읽고 쓸때 memory의 physical address를 전달하는데 사용한다. Memory에 read, write를 할때 address bus에는 memory location이 담긴다. read, write 할 메모리 값 그 자체는 밑에서 볼 data bus에 실린다. Address Bus는 Memory Address Register와 연결되어 있으며, 단방향이다. Address bus는 중요한게 bus width(폭)가 시스템이 다룰 수 있는 address를 결정한다. 예를들어, 32bit address bus라면 시스템은 최대 232가지의 주소공간을 다룰 수 있겠다. Byte-addressable이면 가능한 memory space는 4GB가 되겠다. 다만 모든 경우에 address bus의 width가 꼭 시스템이 사용하는 address와 동일하게 매칭되는 것은 아니다. CPU 칩에서 pin수는 엄청난 비용이다. 따라서 예전 시스템들에서는 16 bit address bus를 사용하지만 32 bit address space를 사용할 수 있다. 다만 이 경우 16bit로 주소를 나누어 두번에 걸쳐 전송해야한다.
Data Bus
Data Bus는 데이터를 전송하는데 사용하는 버스이다. Data Bus는 당연히 읽고 쓸수 있어야 하므로 양방향이다.
32bit, 64bit CPU
32bit 운영체제, 64bit 운영체제를 결정하는 것은 무엇일까? 이는 data bus가 결정하지 않는다. 이를 결정하는것은 프로세서의 정수 register 크기이다. Data bus의 폭은 정수 register와 다를수도 있다. 예전 컴퓨터 머신들의 초기설계에는 data bus의 폭과 정수 register의 크기는 같았으나 꼭 그럴 필요는 없다.
실제로 8080 IBM PC는 16bit CPU이나 data bus는 8bit width이다. 그러므로 프로세서의 register에서 RAM으로 전송하려면 8bit씩 두번을 전송해야 했다.
그리고 프로세서의 정수 register와 address bus의 폭도 다를 수 있다. address bus의 폭은 이보다 더 클수도 작을 수도 있다.
실제로 original AMD Operaton은 64bit 시스템이지만 address bus는 memory subsystem을 단순화하기위해 40bit로 설계되었다. 64bit가 주소로 전부 활용되기는 현실적으로 힘들기 때문이다. 지금 현재의 대부분의 64bit AMD CPU도 48bit의 address bus를 가지고있다.
Modern designs
현재의 디자인들은 우리가 잘 알고있는 bit 기반의 paradigm과는 맞지않는 더 복잡한 bus들을 사용한다. Modern CPU들은 매우 복잡하게 설계되어 있으며 이들은 memory 및 다른 CPU들과의 통신을 위해 특수한 bus들을 사용하기도 한다. 더이상의 단일로 존재하는 address bus나 data bus는 없으며 우리가 알고있는 bit-width 기반으로 처리하는 방식이 아닌 다른 signaling 방식으로 작동할 수도 있다.
Memory False Sharing이란 무엇일까? 말 그대로 직역하면 메모리 거짓 공유이다. 이게 무엇을 뜻하는지 알아보자.
Cache Coherence
먼저 Cache Coherence를 알아야 한다. 멀티코어 환경에서 코어마다 cache가 각각 존재한다. 흔히 말하는 캐시의 개념으로 자주 사용하는 데이터들을 메모리보다 더 빠른 캐시에 저장함으로서 메모리에서 읽지 않고 바로 캐시에서 가져옴으로 성능적으로 큰 이득을 볼 수 있다. 이런 멀티코어 환경에서 각 코어들에 있는 cache들의 일관성을 유지하는 것을 Cache Coherence라고 말한다. 만약에 Core 1에서 메모리 주소 X에 있는 값을 읽기 위해 먼저 메모리에서 읽고 이를 Core 1 캐시에 저장하였다. 다음으로 Core 2에서 메모리 주소 X에 있는 값을 읽기 위해 메모리에서 이를 읽고 이를 Core 2의 캐시에 저장하였다. 만약 Core 1에서 add 연산으로 해당 변수를 원래 값인 1에서 5로 증가시켰다고 해보자. 그러면 Core 1의 캐시는 5로 업데이트 된다. 여기서 Core 2가 이 변수를 읽으면 무슨 값이 반환되어야 할까? 1일까 5일까? Cache Coherence는 캐시에서 공유하고 있는 데이터의 값의 변경사항이 적시에 시스템 전체에 전파될 수 있도록 하는 원칙이다. Cache Coherence는 다음 2가지가 필요하다.
Write Propagation(쓰기 전파) 어떠한 캐시에 데이터가 변경이 되면 이 cache line을 공유하고 있는 다른 캐시에도 이 변경사항이 전파되어야 한다.
Transaction Serialization 특정 메모리 주소로의 read/write은 모든 프로세서에게 같은 순서로 보여야 한다.
두번째의 Transaction Serialization은 다음 예를 보면 이해하기 쉽다. Core 1,2,3,4 가 있을때 이들 모두 초기값이 0인 변수 S의 캐시된 복사본을 각 캐시에 가지고있다. 프로세서 P1은 이 S의 값을 10으로 변경한다. 그리고 프로세서 P2가 이어서 이 S의 값을 20으로 변경한다. 위의 Write Propagation를 보장한다면 P3와 P4가 이 변경사항을 볼 수 있다. 다만 프로세서 P3는 P2의 변경사항을 본 후, P1의 변경사항을 봐서 변수 S의 값으로 10을 반환받는다. 그리고 프로세서 P4는 원래의 순서에 따라 P1의 변경사항을 보고, P2의 변경사항을 그 다음으로 봐서 20을 반환받는다. 결국 프로세서 P3, P4는 캐시의 일관성을 보장할 수 없는 상태가 되었는데 이처럼 Write Propagation 하나만으로는 Cache Coherence가 보장이 안된다. 이를 위해 변수 S에 대한 Write는 반드시 순서가 지정이 되어야한다. Transaction Serialization이 보장이 된다면 S는 위의 예제에서 10으로 write하고 그리고 20으로 write 했기 때문에, 절대 변수 S에 대해 값 20으로 읽고 그다음 값 10으로 읽을 수가 없다. 반드시 값 10으로 읽고 그 다음 20으로 읽는다.
이처럼 Cache Coherence를 유지하기 위해서는 다른 프로세서에서 갱신한 캐시 값을 곧바로 반영을 하든 지연을 하든 해서 다른 프로세서에서 사용할 수 있도록 해주어야 한다. 캐시 일관성을 유지하기 위한 다양한 프로토콜들이 존재하며 대표적으로 MESI 프로토콜이 있다.
Cache Coherence에 대한 내용은 여기까지만 보도록 하고 cache line 이라는 것을 알아보자.
Cache Line
메인 메모리의 내용을 읽고 캐시에 이를 저장하는 과정에서 메모리를 읽을때에 이를 읽어들이는 최소 단위를 Cache Line이라고 한다. 메모리 I/O의 효율성을 위해서이며 spatial locality(공간 지역성)을 위해서이다. 보통의 cache line은 64byte 혹은 128byte로 이루어져 있으며 위에서 설명한 Cache Coherence도 cache line의 단위로 작동한다. 이렇게 cache line으로 읽어들인 데이터들로 캐시의 data block을 구성하게 된다. 또 cache line은 고정된 주소단위(보통은 64byte)로 접근하고 가져온다. 예를들면 다음과 같다.
1 2 3 4 5 6 7 8 9 10 11
+---------+-------+-------+ | address | x1000 | int a | +---------+-------+-------+ | address | x1004 | int b | +---------+-------+-------+ | address | x1008 | int c | +---------+-------+-------+ | address | x100B | int d | +---------+-------+-------+ | ....... | ..... | ..... | +---------+-------+-------+
위와 같은 메모리 구조가 있다고 할때 변수 a를 읽을때는 주소 x1000부터 cache line의 크기인 64byte만큼 가져오고, 변수 c를 읽을때에는 주소 x1008부터 64byte를 읽는게 아니다. 고정된 주소단위로 변수 c를 읽을때에도, write를 할때에도 주소 x1000으로 읽는다는 의미이다.
이제 cache line을 알았으니 다시 Memory False Sharing으로 돌아가자.
Memory False Sharing
Memory False Sharing은 동일한 cache line을 공유할때 Cache Coherence로 인해 성능이 느려지는 안티패턴을 의미한다. 위에서 본 예제로 다시 이해해 보자.
1 2 3 4 5 6 7 8 9 10 11
+---------+-------+-------+ | address | x1000 | int a | +---------+-------+-------+ | address | x1004 | int b | +---------+-------+-------+ | address | x1008 | int c | +---------+-------+-------+ | address | x100B | int d | +---------+-------+-------+ | ....... | ..... | ..... | +---------+-------+-------+
메모리 구조가 위와 같을때 스레드 2개가 있고 스레드 1은 int 변수 a를 1씩 계속 더하는 일을 하고, 스레드 2는 int 변수 c를 1씩 계속 더하는 일을 한다고 해보자.
Thread 1: while (true) { a++ }
Thread 2: while (true) { c++ }
더하기를 시작하기 전 이미 해당 cache line이 캐시에 올라와있다면 CPU 캐시의 상태는 다음과 같을 것이다.
Core 1 Cache +-------------+---------+----------------------+ | mem address | invalid | data block (64 byte) | +-------------+---------+----------------------+ | ..... | ..... | .................... | +-------------+---------+----------------------+ | x1000 | false | a | b | c | d | .... | +-------------+---------+----------------------+ | ..... | ..... | .................... | +-------------+---------+----------------------+
Core 2 Cache +-------------+---------+----------------------+ | mem address | invalid | data block (64 byte) | +-------------+---------+----------------------+ | ..... | ..... | .................... | +-------------+---------+----------------------+ | x1000 | false | a | b | c | d | .... | +-------------+---------+----------------------+ | ..... | ..... | .................... | +-------------+---------+----------------------+
상황을 쉽게 이해하기 위해 두 스레드는 서로 다른 프로세서에서 실행되지만 시간상으로 볼 때 서로 사이좋게 번갈아 가며 add를 한다고 해보자.
Thread 1: a++
Thread 2: c++
Thread 1: a++
Thread 2: c++
이런 순서대로 실행이 된다고 하자. 먼저 1번의 a++가 발생했을때는 Core 1의 cache에서 a에 해당하는 부분이 1을 증가시킨 값으로 write가 일어나게 된다. 하지만 여기서 문제가 발생한다. 바로 다음 2번이 실행되기를 원하지만 그 사이에는 많은 일이 발생한다. 1번을 실행하였을때 Core 1 Cache의 data block 값이 변하였고, Cache Coherence protocol에 의하여 2가 실행되기 전에 하드웨어 병목이 생긴다. MESI protocol에 의해 Core 2의 해당 cache line의 상태가 invalid 상태로 바뀌고 Core 2가 다시 데이터를 읽으려면
해당 cache line이 invalid 이기 때문에 Core 1에서 읽거나 해야한다. 즉 cache line단위로 관리되기 때문에 Thread 2는 변수 a와는 전혀 상관이 없는 작업임에도 불구하고 변수 a에 대한 변경때문에 성능저하가 급격하게 나타나게 된다. 두 변수 a와 c가 서로는 전혀 상관이 없는 데이터임에도 불구하고 같은 cache line에 있기때문에 CPU는 특정 변수가 변경될때마다 캐시 일관성을 맞추기 위해 작업을 하게된다. 이는 성능하락으로 이어진다.
어떻게 해결할 수 있을까?
어떻게하면 이를 해결할 수 있을까? 일종의 cache line size에 맞추어 padding을 넣어 서로 다른 cache line에 속하게할 수 있다. 예는 다음과 같다.
이처럼 변수뒤에 padding을 붙여줌으로서 서로 다른 cache line에 속하게 하면 위 같은 False Sharing 문제를 해결할 수 있다. C++에서는 alignas 함수를 사용하여 padding을 넣어줄 수 있다.
1 2
alignas(64) int a = 0; alignas(64) int c = 0;
자바도 이와 비슷한 방법으로 자바 8부터 @jdk.internal.vm.annotation.Contended 라는 어노테이션을 지원한다. 먼저 클래스 내부필드에 어노테이션을 적용하는 방법을 알아보자. 클래스 내부 필드에 이를 적용하게 되면 해당 필드는 앞뒤로 empty bytes로 패딩을 추가함으로서 object 안의 다른 필드들과 다른 cache line을 사용하도록 해준다.
위의 예처럼 group tag를 지정해주면, count1 변수와 count2 변수는 같은 그룹으로 지정이 되어있고 count3는 다른 그룹으로 지정되어있다. 이런 경우 count1과 count2는 count3과는 다른 cache line을 가지게 되며 count1과 count2는 그룹이 같으므로 같은 cache line으로 될 수 있다.
Contended 어노테이션은 클래스에도 적용할 수 있는데, 클래스에 적용하게되면 모든 field들이 같은 group tag를 가지는 것과 동일하다. 하지만 JVM 구현체에 따라서 다른 isolation 방법을 사용할 수 있다. 전체 object를 isolate 기준으로 할수도 있고 각 field 들을 isolate 기준으로 할수도 있다. (HotSpot JVM 기준으로는 class에 Contended 어노테이션이 적용되어있다면 모든 field 앞에 padding을 적용하는 것 같다. implementation in HotSpot
JVM)
Contended 어노테이션은 이 용도에 맞게 각 object들이 서로 다른 스레드에서 접근하는 상황일때 사용하면 성능향상을 가져올 수 있을것이다. 실제 Contended 어노테이션은 ConcurrentHashMap 구현이나 ForkJoinPool.WorkQueue 등에서 사용하고 있다.