운영체제 7편 - 동기화(Synchronization)
이 글은 학부 운영체제 수업을 듣고 정리한 글입니다.
맥락없이 운영체제에 대한 내용들이 불쑥 등장하니 양해부탁드립니다.
이번 편은 동기화(synchronization)에 대한 내용입니다.
동기화(Synchronization)
공유하고 있는 데이터에 동시에 접근할 때 동기화를 적절하게 해주지 않으면 데이터에 대한 일관성(consistency)를 보장할 수 없다. 공유데이터에 대해 여러 프로세스가 동시에 접근하여 read, write를 함으로써 데이터의 일관성이 보장되지 않는 상황을 race condition이라고 한다.
데이터의 일관성을 유지하기 위해 수행하는 프로세스들이 순차적으로 데이터를 접근하게 하면 일관성을 보장해줄 수 있는데 이를 동기화라고 한다. 한번에 하나의 프로세스만 그 값을 write할 수 있게 하는 것이다.
Race condition 예시
흔한 잔고 출금에 대한 예시를 들어보자.
process A는 balance 변수를 읽고 balance = balance - 500을 하고 process B는 balance 변수를 읽고 balance = balance + 500을 하면 process A와 process B가 concurrent하게 수행이 될때 언제 context switching이 일어날지 모르기때문에 이들을 적절하게 동기화를 해주지않으면 결과를 정확이 보장할 수 없다.
이 말고도 우리가 평소에도 흔하게 사용하는 Thread 들에서도 data section을 서로 공유하기 때문에 race condition이 발생할 수 있고, Kernel 내부에서도 PCB(Process Control Block)이 공유되고 이 외에도 page table 같은 Kernel data structure 들에서도 race condition이 발생한다.
Critical Section
여러 프로세스들이 공유하는 데이터에 접근을 하는 코드의 영역을 critical section이라고 한다. 데이터 일관성을 해결하기 위해서는 오직 하나의 process만이 critical section에 접근할 수 있도록 해야한다.
동기화 문제를 critical section을 사용하여 모델링하면 다음과 같다.
1 | |
Critical section에 작성한 코드들이 제대로 동작되기 위해서는 오직 하나의 프로세스만 접근을 허용해야한다. 이를 해결하기 위한 알고리즘은 다음 3가지 조건을 만족해야 한다.
- Mutual Exclusion
process A가 critical section에 진입해있다면, 다른 프로세스는 진입할 수 없어야 한다. - Progress
critical section에 진입하려는 프로세스가 있다면, 그중 한개의 프로세스는 진입할 수 있어야 한다. 그리고 진입을 시도하는 다른 프로세스는 critical section에 진입하기 위해 영원히 대기할 수 없다. (즉, critical section 안에서 deadlock이 발생하면 안된다) - Bounded Waiting
어떤 프로세스가 critical section에 들어가기 위해서는 특정 시도횟수 안에 critical section에 진입할 수 있어야 한다. 즉 starve 상태인 프로세스가 없어야 한다. 현재 critical section에 진입해있는 프로세스를 제외하고 critical section에 진입을 원하는 다른 프로세스도 critical section에 진입할 수 있는 기회가 보장되어야 한다는 것이다.
동기화 알고리즘
동기화를 해결하기 위한 알고리즘 몇가지를 살펴보자.
1 | |
위의 방식은 알고리즘 조건의 Progress와 Bounded waiting을 만족하지 못한다.
Process B를 시작하지 않으면 Process A는 아예 critical section을 진입하지 못하므로 Progress 조건을 만족하지 못하고, 무한정 busy waiting을 하기때문에 Bounded waiting 조건도 만족하지 못한다.
이를 개선하기 위하여 두개의 flag 변수를 활용하는 방법이 있다.
1 | |
이 방법도 mutual exclusion 조건은 만족하지만 그전에 보았던 방식과 동일하게 다른 2개의 조건은 만족하지 못한다. 경우에 따라 flag[0]과 flag[1]이 모두 true가 될 수 있기 때문이다.
이를 해결하기 위해 Peterson Solution이라고 불리는 방법이 있다.
위와 동일한 방식에 turn이라는 변수를 한가지 추가한다.
1 | |
이 알고리즘은 flag 변수도 쓰고 turn 변수도 사용한다.
알고리즘을 보면 flag[0]과 flag[1]이 둘다 true인 경우가 있을 수 있지만 turn 변수는 반드시 0 혹은 1 이여야 하므로 두개의 프로세스 모두 critical section에 들어가는 경우는 존재하지 않는다. 또한 두개의 프로세스 모두 critical section에 들어가지 못하므로 flag[0], flag[1] 모두 false인 경우도 발생하지 않는다.
그러므로 알고리즘의 조건인 Mutual Exclusion, Progress, Bounded Waiting을 모두 만족한다.
다만 Peterson Solution은 확장성에 한계가 존재한다.
만약 2개의 프로세스가 아닌 3개 이상의 프로세스에 대해 지원하려면 매우 복잡해지고 구현하기가 쉽지 않다.
해결책
초기 해결책
kernel에서도 critical section에 대한 동기화가 필요했다. 초기에는 kernel mode로 들어갈때 kernel code 자체를 critical section으로 만들어 kernel mode 일때에는 아예 interrupt 자체를 막아버리는 방식으로 구현을 했었다. (현재는 이렇게 구현되어 있지 않다.) 그래서 kernel mode에서 빠져나와 user mode가 되는 순간 interrupt가 발생하는 방식이였다. interrupt가 disable 되어있으니 context switching은 발생하지 않는다. kernel 전체가 커다란 critical section으로 동작하는 것이다. 다만 kernel 전체가 프로세스가 많아질때 오직 한개의 프로세스만 kernel에 진입할 수 있었으므로 대기시간이 길었고, Kernel 레벨에서 multi-threading 을 지원하기 힘들었다.
하드웨어 해결책
interrupt로 동기화를 해결하려다 보니 쉽지않아 hardware instruction으로 해결하자는 이야기가 등장했다. instruction으로 처리하면 알고리즘이 매우 간단하기 때문이다. 흐름은 다음과 같다.
1 | |
critical section에 진입하기 전에 lock을 잡고 lock 획득에 실패한 프로세스들은 모두 lock을 대기한다. 오직 한개의 프로세스만 lock을 잡고 critical section에 들어갈 수 있다. 이런 방식을 Mutex Lock 이라고도 부른다.
lock은 동기화 instruction(Synchronization instruction)을 사용하여 구현할 수 있다.
Synchronization instruction
동기화 instruction은 hardware에서 제공해주는 instruction으로 CPU에서 원자적으로(atomically) 수행되는 것을 보장한다. instruction 사이에는 당연히 interrupt가 발생할 수 없다.
동기화 instruction의 예시들을 몇가지 살펴보자.
testAndSet
testAndSet의 semantics는 다음과 같다.
1 | |
여기의 testAndSet의 semantics가 그대로 instruction으로 구현이 되어 있는 것이다. boolean 변수를 받아 true로 설정하고 그 전에 설정되어 있던 값을 반환한다. 다만 testAndSet은 느린 instruction이다. 보통 memory access에 대한 instruction은 8cycle 정도 걸리는데 testAndSet instruction은 최소 16 cycle은 걸린다. 다만 이 instruction이 수행되는 동안은 interrupt를 받지않는다. 이를 활용한 방식은 process가 여러개여도 동작한다. 이를 사용하여 동기화를 구현하면 다음과 같다.
1 | |
testAndSet 수행결과가 false인 경우만 critical section에 진입할 수 있다. 그리고 instruction이 atomic 하므로 mutual exclusion을 만족한다.
다만 위 예제처럼 실제로는 while loop을 통한 busy waiting으로는 잘 구현하지 않는다. testAndSet instruction을 수행할 때마다 memory access가 일어나는데 이를 busy waiting을 하니 Bus가 엄청난 트래픽을 받게되어 성능이 많이 떨어지게 된다. 뒤에 보겠지만 이를 극복하는 방법이 있다.
Swap
Swap이라는 동기화 instruction도 존재하는데 이 또한 testAndSet의 일종이라고 생각해도 된다. 다음과 같은 swap을 atomic하게 수행되도록 해주는 hardware instruction이다.
1 | |
ARM의 swap instruction 설명을 보자.
SWP (Swap) and SWPB (Swap Byte) provide a method for software synchronization that does not require disabling interrupts. This is achieved by performing a special type of memory access, reading a value into a processor register and writing a value to a memory location as an atomic operation.
즉 interrupt disable을 따로 할 필요없이 instruction level에서 atomic 수행을 보장해준다.
이런 testAndSet 이나 swap 같은 동기화 instruction을 사용할 수 있도록 OS나 각 언어별 API에서 제공을 해준다.
Synchronization instruction 한계
이처럼 동기화 instruction을 사용하면 mutual exclusion은 해결할 수 있으나, bounded waiting 같은 조건은 software 프로그램에서 제공을 해야한다. 사용자 software에서 이런 부담을 지우기 위해 동기화 primitive를 따로 지원하는데 이렇게 해서 나온 것이 세마포어(semaphore)이다.
Semaphore
Semaphore는 두개의 원자적 연산을 가지는 변수이다.
여기서 말하는 원자적인 연산은 다음과 같다.
- wait() or P()
- signal() or V()
Semaphore는 그냥 변수이다. critical section에 들어가기 전에 P를 수행하고 critical section에 나오면 V를 수행한다. Semaphore는 P를 통과하면 decrement하고 V를 통과하면 increment 한다.
P와 V 연산은 서로 독립적이고, 원자적으로 수행된다. P, V 연산 모두 원자적으로 수행되는 것은 맞지만 P, V 모두 반드시 같은 프로세스에서 진행될 필요는 없다.
Semaphore는 2가지로 보통 나누게 된다. Counting Semaphore와 Binary Semaphore이다.
- Counting Semaphore
Semaphore의 값은 한계가 따로 없으며, 초기 값은 가능한 자원의 수로 정해진다. - Binary Semaphore
Semaphore가 가질 수 있는 값은 오직 0과 1이다.
Original Semaphore
Original Semaphore는 busy waiting을 사용한다.
Busy waiting을 이용한 방법은 다음과 같다.
1 | |
위처럼 Busy waiting은 critical section에 진입할 조건이 될 때까지 loop을 돌며 기다린다. 그러므로 CPU cycle을 낭비할 수 있고, 대기중인 프로세스에서 어떤 프로세스가 critical section에 진입할지 알 수 없다.
어떻게 busy waiting을 하지 않을 수 있을까? 기다리고 있는 프로세스들은 sleep을 하도록 만들 수 있겠다.
Semaphore with sleep queue
Busy waiting 방식의 CPU cycle을 낭비하는 문제를 해결하기 위해 Semaphore의 자료구조에 sleep queue를 추가하여 대기중인 프로세스를 관리할 수 있겠다.
다른 프로세스가 이미 critical section에 진입해있으면 진입을 시도하려는 프로세스를 sleep을 하고 sleep queue에 넣는다. 그리고 Semaphore의 값이 양수가 되어 critical section에 진입이 가능하게 된다면 sleep queue에서 대기중인 프로세스를 깨워 실행시킨다.
Sleep을 한다는 것에 대해 조금 생각해 볼 필요가 있다. 예전에는 프로세스가 sleep을 하기 위해서는 I/O를 요청하는 경우였다. Time quantum을 전부 다 소진한 프로세스는 다시 ready queue로 들어가게 된다. 이제는 이런 경우가 아닌 새롭게 voluntary(자발적인) sleep의 개념이 생긴 것이다.
스케줄링과 조금 엮어서 생각을 해보면, P를 통해 critical section에 진입을 하지 못한 프로세스들은 sleep을 하게되는데 V 호출이 일어나게 되면 sleep 하고 있는 프로세스들에게 critical section에 다시 진입하도록 깨워주어야한다. 실제 구현체에서는 V 호출이 일어나면 현재 semaphore로 인해 sleep 하고있는 모든 프로세스들을 다 깨운다. 그리고 다음 critical section에 대한 진입은 scheduler에게 맡긴다.
Mutex vs Semaphore
Semaphore는 서로 다른 프로세스들에서 P와 V를 각각 호출할 수 있다. 즉 process A에서는 P를 호출하고 process B에서는 V를 호출할 수 있다.
이러한 이유로 Semaphore에는 여러가지 발생할 수 있는 문제들이 존재하는데 예를들어 P를 호출하지 않았는데 V를 호출한다던가(Accidental Release), P를 호출한 프로세스가 다시 P를 호출하는 재귀적 deadlock(Recursive Deadlock) 등이 있다.
다만 Mutex의 경우는 lock을 획득한 주체만이 unlock할 수 있다. 만약 lock을 획득한 프로세스가 아니라 다른 프로세스에서 unlock을 시도하게되면 unlock이 불가능하다. 이것이 Semaphore와의 가장 큰 차이인데 이를 The principle of ownership이라고 한다. Mutex에서는 본인이 lock을 들고있어야 하므로 위에서 설명한 Accidental Release가 발생할 수 없고 Recursive Deadlock도 쉽게 해결할 수 있다.
Mutex는 concurrent하게 실행되는 code에 대한 protecting에 초점을 맞춘다면, Semaphore는 한개의 스레드가 다른 스레드에게 signal을 보내는 의미가 강하다고 생각할 수 있다.
Deadlock in Semaphore
Semaphore에 Deadlock을 해결하기 위한 간단한 방법이 있다.
Semaphore간의 partial order를 정해놓고 그 order에 맞춰서 semaphore를 잡으면 deadlock을 막을 수 있다. 여러개의 프로세스들에서 Semaphore의 P를 잡고 들어가고 V를 호출하는 순서들을 정확히 맞추는 방법이다.
애초에 이런 문제를 해결하기 위해 맨처음 진입시 전체적인 global state를 관리할 수 있는 큰 semaphore 1개를 잡고 할 수 있지않느냐 라고 질문을 할 수 있다. 이러면 deadlock은 발생하지 않는다. 다만 concurrency를 높게 살리기 힘들다.
Monitor
위에서 살펴보았듯이 Semaphore에는 발생할 수 있는 여러가지 문제점이 있다.(Accidental Release, Recursive Deadlock)
그래서 이를 조금 더 high level에서 해결하려는 요구를 하게되었다. High-level 언어에서 procedure를 호출하는 것만으로도 동기화를 해결할 수 있도록 하는 것이다.
그래서 Application level에서는 P, V 연산을 호출할 필요없이 지원하는 procedure만 호출하도록 한다. 이를 Monitor라고 한다.
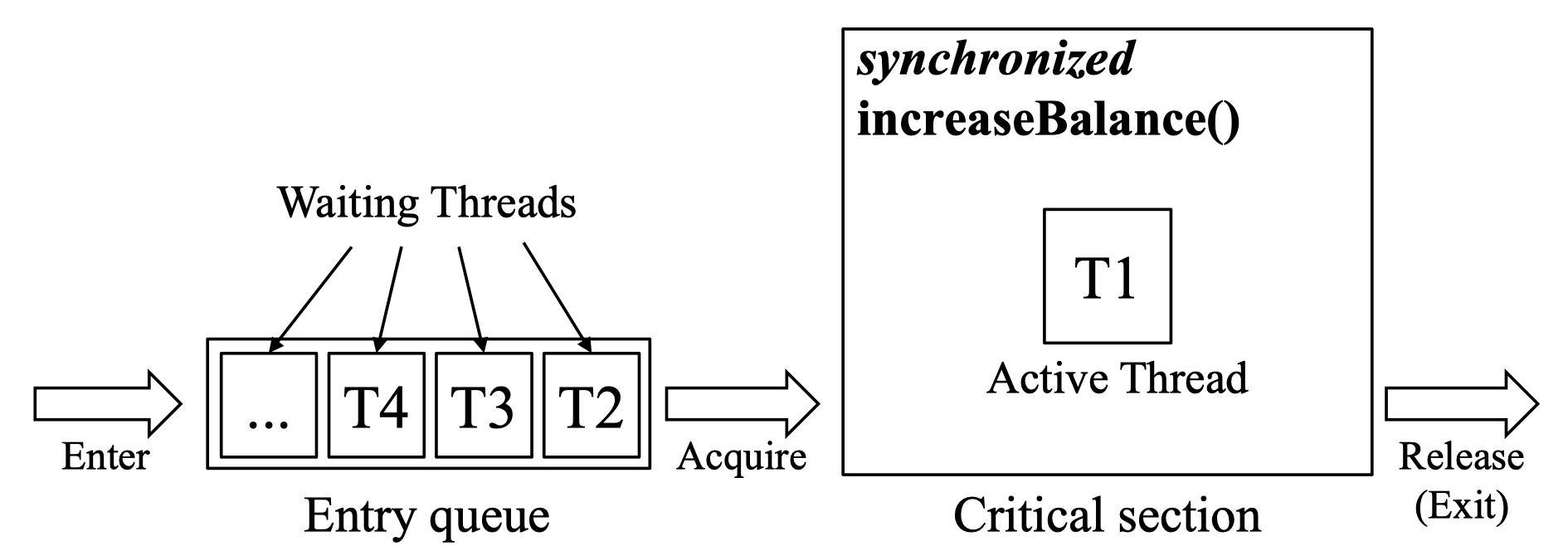
예시로는 자바에는 synchronized keyword를 지원한다. synchronized block을 지정하여 동기화되는 영역을 지정할 수 있다.
Monitor in Java
내부적으로 Entry queue를 만들고 synchronized block에는 한번에 한개의 스레드만 진입할 수 있도록 한다.