파일시스템 5편 - 파일시스템 디자인-2
이 글은 지난번 파일시스템 디자인-1 에 이은 글입니다.
파일시스템 계층화
파일시스템은 계층화가 잘되어있다. 일반적으로 파일시스템은 여러 개의 layer로 나뉘어져 구성된다.
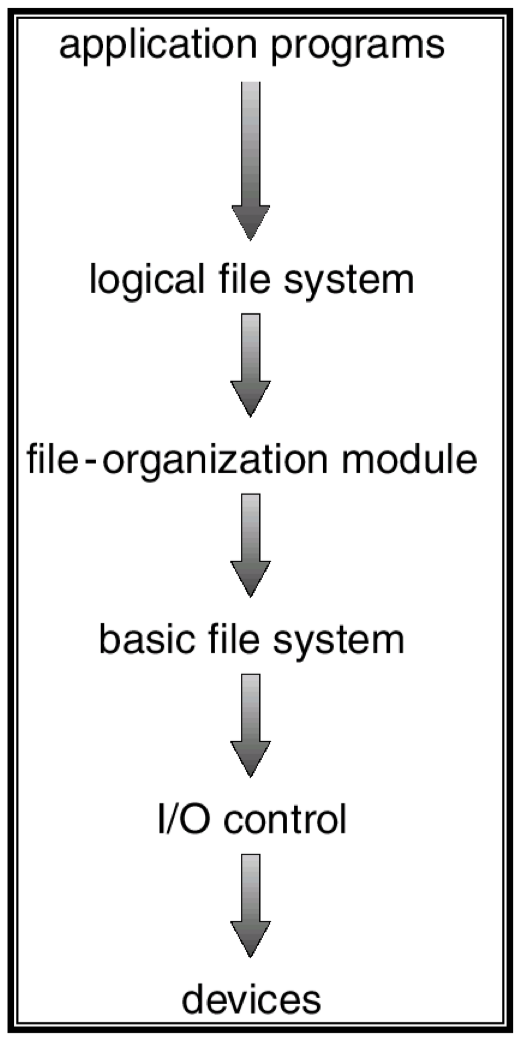
위의 그림에서 각 layer를 간단하게 살펴보자.
Logical file system
여기서는 파일시스템의 메타데이터를 관리한다.
File-organization module
이 layer에서는 파일의 logical block 주소를 physical block 주소로 변환해준다. 예를들어 하드디스크를 매체로 사용하게되면 sector 주소로 접근해야 하는데 이를 위한 변환을 진행한다.
Basic file system
여기서는 위에서 변환된 physical block 주소를 가지고 읽고 쓰도록 command를 날린다. 여기서 DMA를 사용한다.
I/O control
이는 device driver다. device driver가 하드웨어에 맞게 명령을 전달한다.
Virtual File System
파일시스템은 어쩔 수 없이 사용하는 매체에 의존성이 있다. 그래서 파일시스템은 종류가 여러가지가 있을 수 있다. 예를들어 요즘은 잘 안쓰지만 CD-ROM이 있을 수 있고 USB, SSD, Disk 그리고 파일이 현재 호스트가 아닌 다른 네트워크의 호스트에 있을 수도 있다. Linux kernel 에서는 여러가지 파일시스템을 지원한다.
VFS는 다양한 logical file system 들을 추상화한다. 따라서 VFS를 통해 실제로 시스템에는 여러개의 다른 파일시스템이 사용되더라도 마치 1개의 파일시스템만 사용하는 것처럼 프로프래밍 할 수 있다. 이는 OOP의 개념과 같은데 특정 파일에 대해 read/write syscall 이 호출되면 해당 파일이 속한 파일시스템 구현체의 read/write 가 호출되는 방식이다.
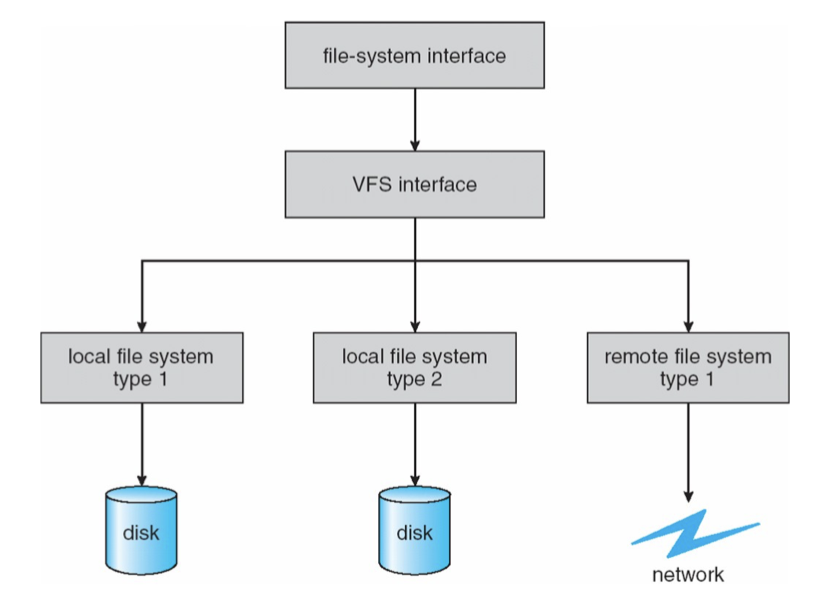
File System data structure
파일시스템에서 사용하는 자료구조를 알아보면서 파일시스템에 대한 이해를 높여보자.
On-disk 그리고 In-memory 에서 사용하는 자료구조들을 볼 것이다.
On-disk data structure
On-disk 자료구조들은 이미 이전 포스트인 파일시스템 디자인-1 에서 vsfs(very simple file system)에서 살펴봤던 내용들이 많다.
- Boot block
첫번째 block으로 운영체제가 booting 하기위해 필요한 정보를 담아놓는 block이다. 하지만 이를 안만드는 경우도 많다. - Super block
파일시스템 관련 정보들이 어디에 저장되어있는지에 대한 metadata를 저장한다. 예를들어 inode table은 어디서 시작인지, data block은 어디 block부터 시작하는지, root directory에 대한 inode 번호 등을 저장한다. Super block은 보통은 각 disk partition의 첫번째 block 에 할당하고 이 super block 이 손상되면 파일시스템의 복구가 힘들기때문에 보통 중복해서 super block을 저장한다. 그리고 이 super block은 in-memory data structure로 메모리에 올려 캐싱한다. - File control block
FCB(file control block)은 결국 inode와 같다. inode 자체도 disk에 저장이 필요하다.
다음의 disk structure layout를 살펴보자.
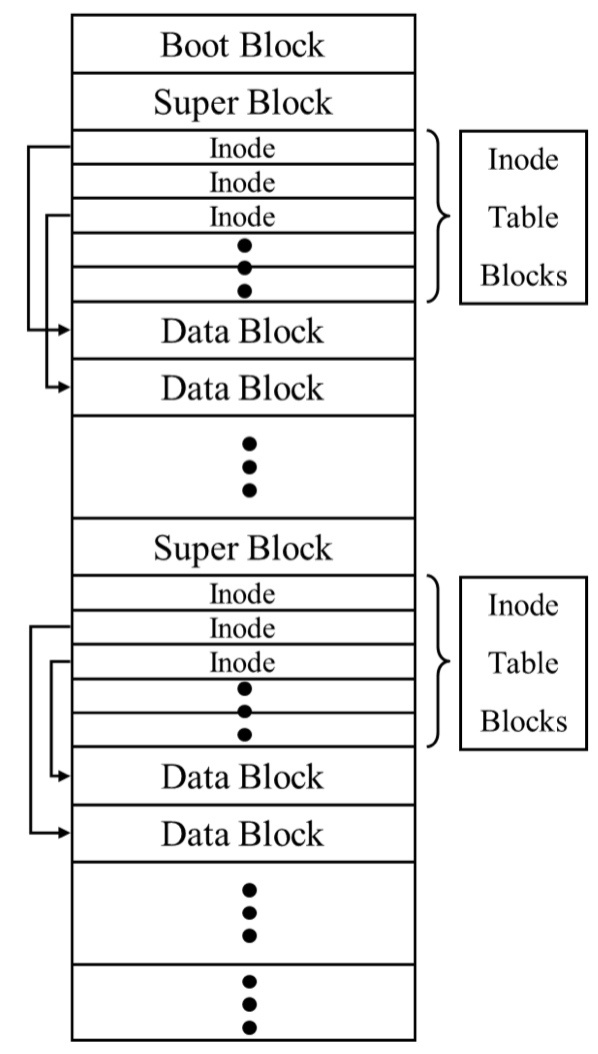
여기서 각 inode table을 여러개로 나누어 저장한 이유는 data block과 inode가 가까우면 성능을 높일 수 있기때문에 조금씩 inode 들을 나누어 설계했다. 다만 이런 내용들은 전적으로 파일시스템 구현에 달라진다.
결국 여기서의 그림을 보면 파일 접근을 위해서 super block, inode, data block 에 대한 접근으로 파일 하나의 접근에 대해 3번의 disk access가 필요하다.
In-memory data structure
보통 파일시스템에서의 in-memory data structure 들은 거의 caching을 통한 성능향상 그리고 파일시스템 관리가 목표이다.
- Dentry
이는 directory cache 이다. directory 접근을 위해 on-disk 의 super block 그리고 root directory 의 inode 부터 접근해서 dentry 라는 directory cache를 만든다. dentry로 파일접근시 해당 파일의 inode를 알기위해 여러번 disk 에 접근할 필요가 없이 memory 에서 처리할 수 있다. - open file table
이는 예전에 살펴본 내용으로 system-wide open file table 그리고 per process open file table 이 있는데 각각 open 한 file을 관리한다. per-process open file table 에서 각 index 번호가 file descriptor 가 된다. - Buffer cache
최근에 사용한 data block 을 memory 에 캐싱한다.
Buffer Cache
Buffer cache는 조금 더 자세히 살펴보겠다.
Buffer cache는 파일의 메타데이터가 아닌 data block 자체를 메모리에 올려둔다. 보통 같은 data block을 다시 접근해야 하는 경우가 많기때문에 이를 캐싱해두면 다시 disk를 조회하지 않아도된다.
다만 buffer cache는 완전한 software로 구현된다. 이 말은 virtual memory의 주소변환을 위해 TLB 같은 하드웨어를 도입하는게 아닌 순수한 software 레벨에서 구현한 캐시라는 의미이다.
Buffer cache는 보통 물리메모리의 1 ~ 10% 정도로 할당하고 이는 kernel parameter로 수정이 가능하다. Buffer cache 도 공간이 한정되므로 교체알고리즘을 사용한다. 보통 disk access 에는 locality가 나타나기 때문에 LRU 방식을 사용한다.
다만 DBMS 나 multimedia application은 LRU 로 이득을 볼 수 없는 경우가 대부분이기 때문에 이들은 buffer cache를 거치지 않고 바로 disk 에 접근할 수 있는 flag를 사용해서 buffer cache를 거치지 않도록 프로그래밍 한다.
Read syscall 과 Write syscall 각각의 동작방식을 buffer cache 의 관점에서 살펴보자.
Read syscall
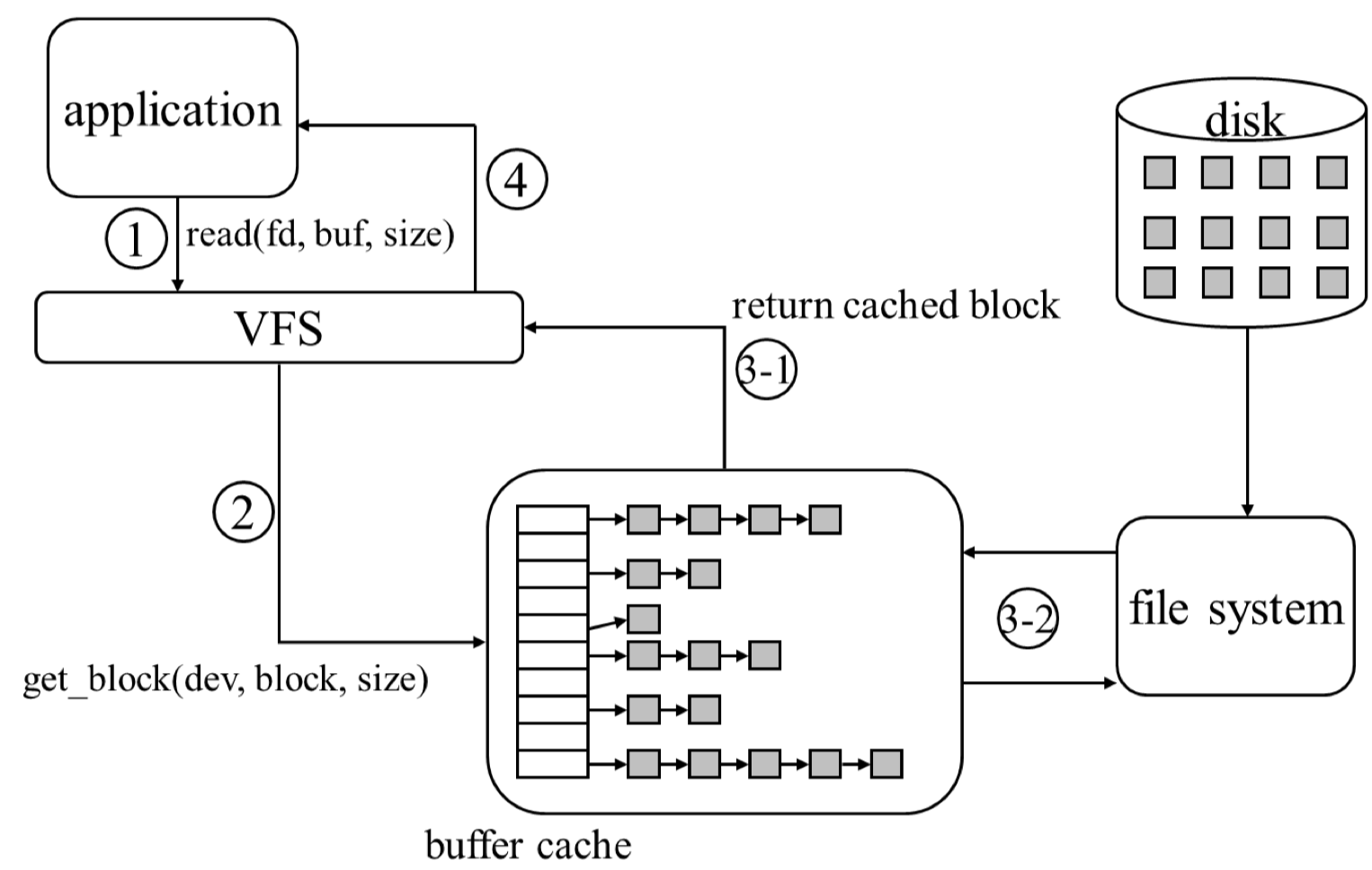
먼저 read(fd, buf, size) syscall 을 호출한다. read syscall 의 두번째 인자인 buf 는 사용자의 buffer를 의미한다.
그다음 VFS에서는 file descriptor를 보고 file이 있는 device를 알아낸 후 logical block number 를 physical block number 로 변환한다. buffer cache 쪽에 해당 block이 있는지 확인을 하고 block 이 없다면 파일시스템에서 가져와야한다. 만약 buffer cache에 이미 cache된 block이 있으면 VFS에 반환한다.
cache된 block이 없다면 파일시스템에 block을 요청하고 이 read 를 요청한 프로세스는 sleep 한다. 즉, context switching 이 일어난다. I/O가 필요하기 때문이다. 나중에 disk에서 block을 읽어오면 interrupt 가 발생하고 그 block 을 다시 caching 해주고 block 을 반환한다.
VFS에 반환할때는 application의 buf에 block들을 copy해주고 읽어온 byte 수를 반환한다.
만약 read 를 하더라도 buffer cache 에 대상 block 이 존재하여 cache hit 이 된다면, 해당 프로세스는 sleep 하지 않는다.
그리고 buffer cache 쪽을 보게되면 hash table 구조로 구현되어 있고 value로는 linked list 로 각 cache 되어있는 data block 들이 있는 것을 확인할 수 있다. hash 의 key로는 보통은 block number 를 사용한다고 한다.
Write syscall
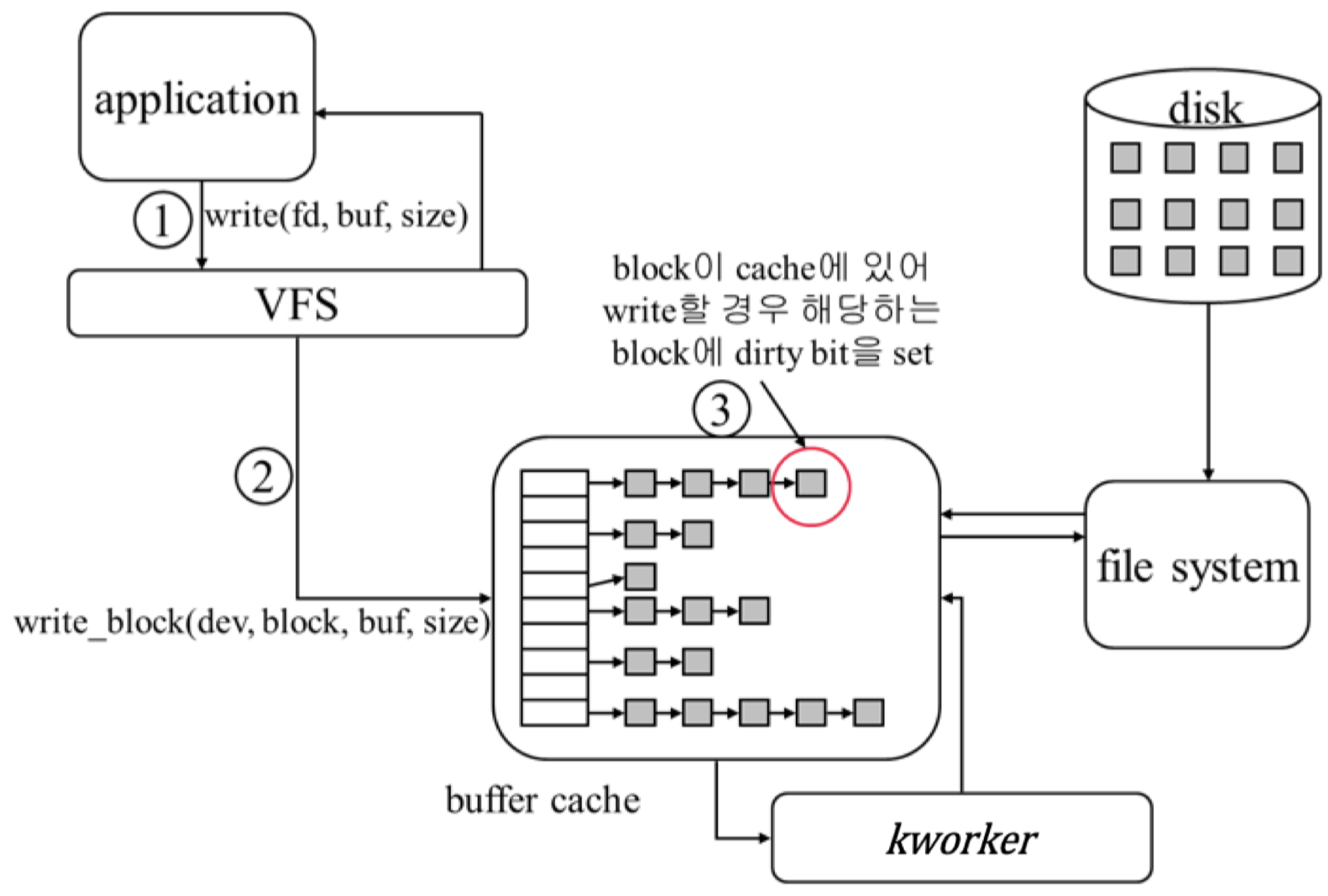
먼저 write(fd, buf, size) syscall 을 호출한다.
VFS에서 device 및 block number로 변환하여 buffer cache에 해당 block이 이미 있는지 확인한다. 만약 write 하려는 block 이 buffer cache에 없다면 먼저 파일시스템에서 읽어오도록 요청한다. 이 과정에서도 write를 요청한 프로세스는 sleep 한다.
파일시스템에서 읽어왔으면 다시 write를 시도하면 해당 block이 buffer cache 에 존재하므로 이 경우에는 해당 buffer cache의 data block에 직접 write를 수행하고(in-memory) 해당 block이 disk에 있는 block과 일치하지 않는다는 표시를 하기위해 dirty bit를 체크한다.
만약 처음부터 buffer cache에 write 시도시 해당 block 이 buffer cache에 있었다면 바로 그 block에 write 하고 반환한다.
이런 방식이면 buffer cache와 disk 의 sync가 깨지게 되는데 이는 다른 worker 스레드가 주기적으로 dirty bit가 체크된 data block 들을 disk에 sync 시켜준다.
kworker
이 kworker 라는 kernel thread가 buffer cache와 disk block 간의 동기화를 수행한다.
예를들어 data block은 30초, metadata는 5초마다 동기화를 시킬수도 있다. 다만 이런 구현은 실제 OS 구현마다 다르며 파일시스템 구현마다도 다르다.
다만 이런 방식이면 순간적으로 머신이 꺼지거나 할때 동기화가 되지 않은 부분은 유실될 수 있다. 즉 write를 하더라도 그 내용이 disk에 반영된다는 보장이 없다. 이를 위해 저널링 파일시스템 같은 대안을 사용한다.
Application 에서 fsync system call을 사용하면 강제적으로 buffer cache의 내용을 disk에 반영한다.
DBMS도 구현마다 다르지만 매번의 update 마다 fsync 를 수행하지는 않는다. DBMS에서는 이를 write ahead log 과 transaction을 이용해 해결한다.
Memory-Mapped File(mmap)
mmap은 파일을 프로세스의 address space 한 부분으로 mapping 한다. 파일을 프로세스의 memory space 에 그냥 가져다가 붙힌다고 생각하면 쉽다.
이렇게 되면 단순히 memory access instruction 을 통해 파일에 대한 read, write을 할 수 있다. kernel은 이런 memory access instruction 을 적절하게 read, write로 변환하여 수행해준다.
mmap 함수는 다음과 같다.
void* mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset)
start는 단지 이 주소를 사용했으면 좋겠다는 의미로 0을 보통 넣는다. 그리고 offset 부터의 length 만큼의 바이트를 start 주소로 매핑하기를 원한다는 의미이다.fd는 파일에 대한 file descriptor 로 이미 존재하는 파일에 대한 file descriptor 를 넘겨 이를 읽거나 수정할 수도 있고, 새로운 파일을 O_CREAT flag 와 함께 open 하여 이 file descriptor 를 넘겨 새로운 파일을 쓸 수도 있다.
유저는 파일에 대한 I/O 를 단지 memset, memcpy 같은 memory access 로 단순화 할 수 있다.
그리고 여러개의 프로세스에서 동일한 파일을 open 하여 사용할 경우 kernel 은 동일한 파일에 대한 내용을 memory에 1개만 들고있으면 된다.
mmap 파일의 동작을 그림으로 보자.
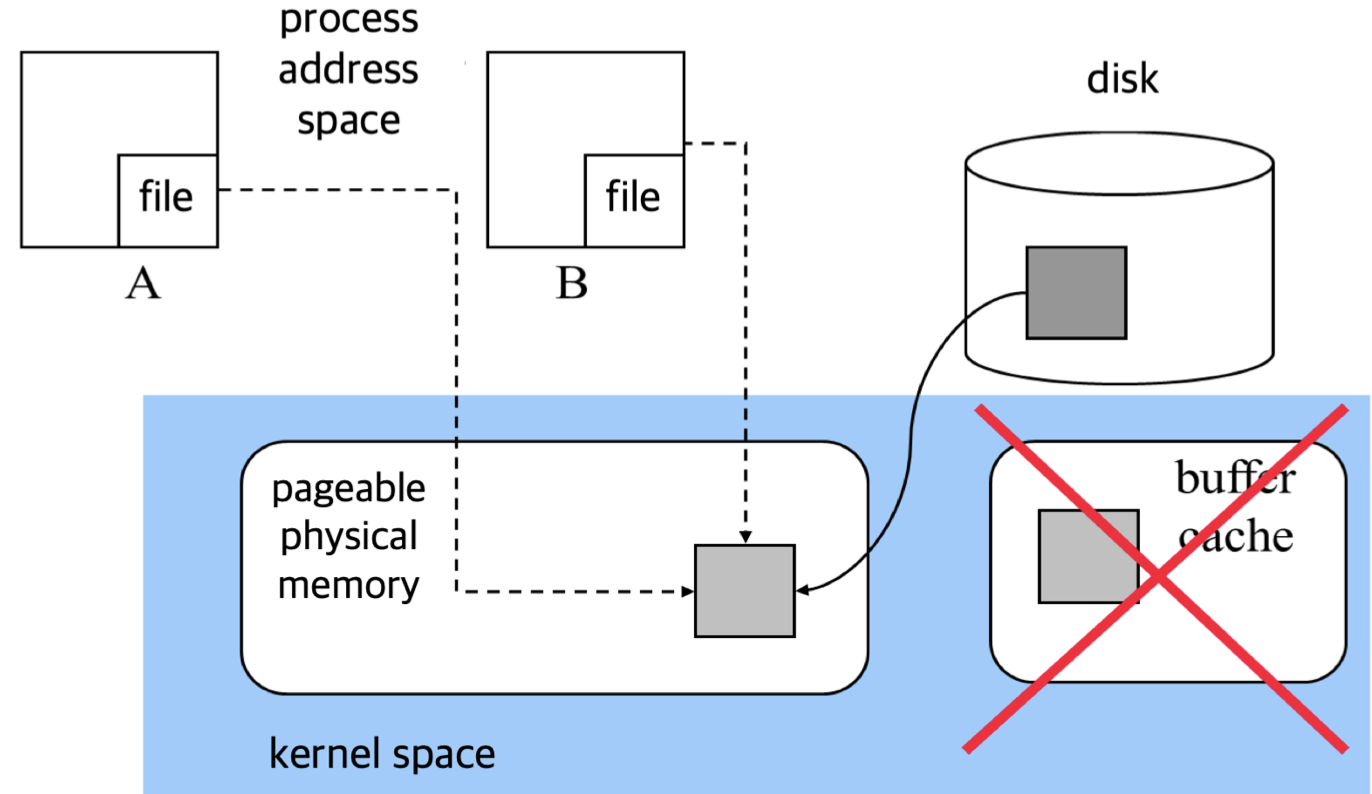
먼저 mmap 을 사용하지 않는 경우를 생각해보면, disk 에서 DMA로 data block을 가져오면 이를 buffer cache에 올리고 그다음 사용자 buffer 로 copy를 해야한다.
buffer cache 로는 DMA 가 copy 해주지만, buffer cache 에서 user buffer 로는 CPU가 직접 copy 해야한다. 따라서 file IO 가 빨라지려면 CPU도 중요하다.
mmap은 조금 다르다. mmap은 buffer cache를 사용하지 않는다. mmap은 buffer cache에 data block을 쓰지 않고 바로 kernel space로 DMA가 쓴다. 그리고 이를 프로세스의 address space 에 page table을 통해 매핑한다.
따라서 user buffer 로의 copy가 존재하지 않는다.
위의 그림에서는 process A 와 process B 가 각각 mmap 되어있는 physical fragment 를 공유하고 있다. mmap 에서는 flag에 MAP_SHARED flag 를 통해 다른 프로세스와 mmap 된 파일을 공유할 수 있다. 하지만 다른 동기화 같은 장치는 제공하지 않는다.
process A 에서 먼저 특정 파일을 mmap 하였을때 그 다음 process B 에서 같은 파일에 대해 mmap을 하게되면 서로 반환받는 virtual address 주소는 다르지만, 결국 page table 에 매핑된 physical address 주소는 같아 같은 파일을 바라보게 된다.