파일시스템 4편 - 파일시스템 디자인-1
이 글은 학부 System Programming 수업을 듣고 파일시스템 관련내용을 정리한 글입니다.
이번 편에서는 크게 다음 2가지를 볼 것이다.
- File System의 디자인
- Directory의 디자인
unix 시스템에서 파일과 디렉토리는 비슷하면서도 다르게 구현이된다.
파일의 디자인부터 살펴보자.
File Implementation
File 구현의 핵심은 file의 내용을 담고있는 data block이 저장되는 디스크상의 위치정보를 결정하는 것과 이에 대한 관리방법이다.
data block의 디스크에서의 위치정보를 결정하기 위해서는 여러가지 할당방법들이 존재하는데 실제로 사용되고 있는 몇가지 방법들을 알아보자.
Contiguous Allocation
Contiguous는 말그대로 연속적인, 연결되어있는 이런 의미이다.
Contiguous Allocation 방식은 파일을 물리적으로 연속된 disk block에 저장한다. 우리가 프로그래밍 할때 고정 길이의 배열을 할당하고 사용하는 것과 유사하다.
이 방식은 구현이 간단하며, 물리적으로 연속된 공간에 block이 위치하기 때문에 전체 파일을 한번에 읽어들일경우 성능상 매우 큰 이득을 볼 수 있다. 이처럼 파일의 맨 처음부터 끝까지 읽는 방식을 sequential read라고 한다. 이의 반대는 random read이다.
Contiguous Allocation은 random read도 빠르다. 파일에서 특정 block의 위치를 바로 알 수 있다. 연속된 block이므로 index로 block 주소를 바로 계산할 수 있기 때문이다.
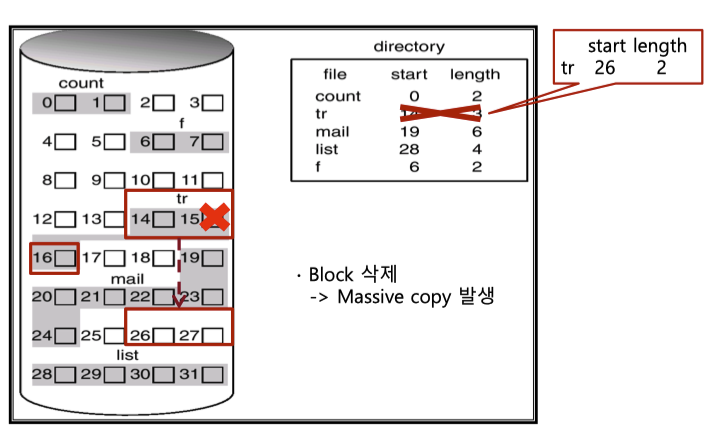
위 그림에서 block 14, 15, 16을 을 차지하고 있는 파일을 수정할때는 어떻게 해야할까?
Contiguous Allocation에서는 파일 수정시 수정한 block들을 어디에 위치할지 빈공간을 계속해서 찾아야 한다. 새로운 빈 연속된 block들을 찾으면 이에 복사하면서 massive copy가 발생한다.
위의 예시에서는 파일크기가 더 작도록 수정하기 때문에 반드시 다른 비어있는 다른 block들을 찾아야하는 것은 아니지만, 파일의 크기가 늘어나면서 수정을 하게되면 copy가 불가피하다.
이런 비용을 최소화 하기위해 파일끝에 예비용 block을 남기는 경우도 있지만 이는 disk 공간을 낭비한다.
이런 방식은 많이 사용할 것 같지 않아보이지만 예상외로 많이 사용된다. 실제로 데이터베이스는 이런 방식으로 구현하는 경우가 많다. Disk block을 연속해서 여러개 할당하고 그 안에서 내부적으로 읽고 쓰고를 반복한다.
static한 파일들을 담고있는 서버에서도 파일에 대한 sequential read 성능이 매우 중요하기 때문에 사용하는 경우가 있고, 나중에 보게되겠지만 log structured file system에서 flash 같은 메모리는 이런 방식을 사용한다.
또한 구현이 간단하기에 임베디드에서 이를 채택하는 경우가 많다.
Linked List Allocation
위에서 본 Contiguous Allocation 방식은 파일을 쓸때 능동적으로할 수 없다. block이 연속적이여야 하기 때문이다. 그래서 disk의 block을 linked list로 구현해서 file의 data를 저장하도록 하는 방식이 Linked List Allocation 방식이다.
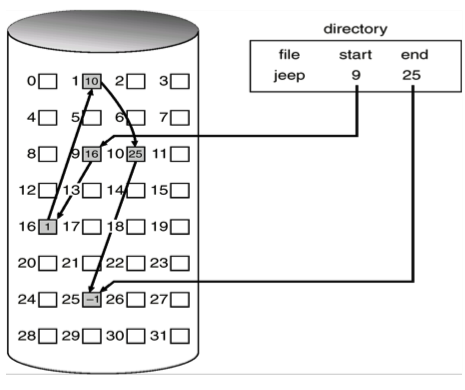
위 그림을 보게되면 파일을 읽을때 파일의 시작 block에서 출발해서 그 다음 block을 찾아가는 방식이다. data block에 다음 block의 주소를 같이 저장한다.
이 방식은 file의 data block이 disk의 어디든지 위치할 수 있기때문에 유연하다. 또한 Contiguous allocation의 방법과 다르게 공간의 낭비가 없다.
단점도 존재하는데 Random access를 하는데 성능이 좋지 못하다. File의 특정위치를 찾아가기 위해서는 해당 file의 시작 block부터 찾아가야 하기 때문이다. 이를 해결하기 위해 file의 metadata를 in-memory에 캐싱을 하기도 한다.
Data block에 다음 block 주소를 저장해야 하는 공간낭비 문제도 존재한다.
실제로 MS-DOS의 FAT(File Allocation Table) File System은 Linked List Allocation 방식을 사용한다.
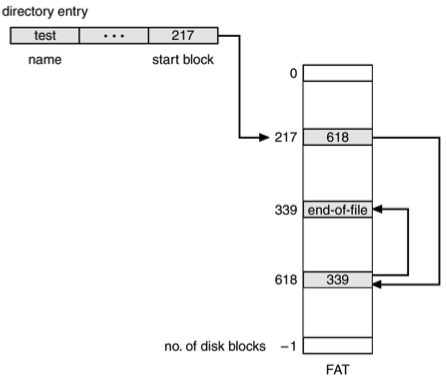
Random access가 느리기 때문에 더 나은 방법으로 File의 data block의 위치를 별도의 block에 모아둘 수 있다.
이렇게 File의 data block을 모아놓은 block을 index block이라고 하며 이 block을 읽어 파일의 모든 data block의 위치를 알 수 있다.
이 방식이 Linked List Allocation 보다 개선된 점은 random access 시 index block만 읽으면 찾아가고자 하는 data block의 위치를 알 수 있으므로 빠르게 random access가 가능하다.
index block이 몇개의 block 주소를 가질 수 있느냐가 이 파일시스템이 지원하는 최대 파일크기를 결정한다.
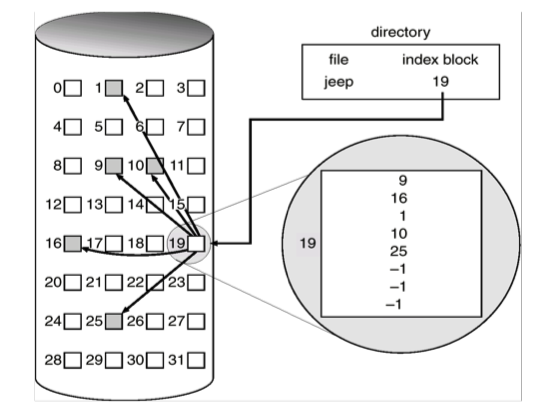
위 그림을 보면 19번 block에 index block을 위치하고 이 block에 data block을 순서대로 위치한다.
inode
inode는 unix 파일시스템에서 사용하는 방식이고, windows 에서도 이와 비슷한 방식을 사용한다.
inode는 index node의 줄임말로 file의 metadata를 가지고있는 구조체이다. inode는 파일시스템 디자인에서 매우 중요한 역할을 맡는다.
inode는 파일에 대한 data block index를 계층 형태로 관리하도록 한다. 메모리에서의 multi-level paging 방식과 비슷하다. 이러한 방식으로 inode의 data block 관리방식으로 구현을 하면 많은 flexibility를 얻을 수 있다. .
PCB에는 프로세스 관련한 정보가 다 들어가있듯이, inode에는 파일에 대한 대부분의 데이터가 전부 다 들어가있다.
inode의 구성요소는 대략적으로 다음과 같다.
- File에 대한 속성을 나타내는 field들이 존재한다. file owner, timestamp, hard link counter, last access time, acl 정보 등이 있다.
- 작은 크기의 파일을 위한 direct index가 존재한다.
- 파일의 크기가 커짐에 따라서 요구되는 data block의 index들을 저장하기 위한 index table들이 존재한다. 이 index table을 가리키는 single indirect, double indirect, triple indirect 이 있다.
inode의 대략적인 도식을 그림으로 보자.
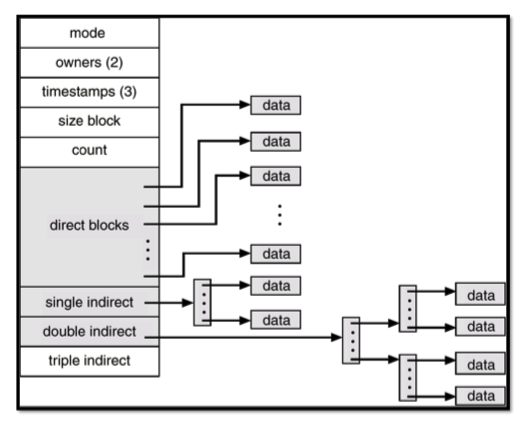
Multi-Level Index in inode
direct block은 그 자체의 값들이 data block을 가리키는 포인터이다.
direct block이 8개가 있고 block size가 4KB라면 파일크기가 최대 32KB까지는 indirect block을 사용하지 않는다.
파일이 그 크기가 넘어가면, 즉 direct block에서 처리가능한 block 개수가 넘어가게되면 indirect block을 사용하기 시작한다.
single direct를 사용하기 시작한다. single indirect는 data block의 주소를 담고있는 index block을 가리킨다. index block은 data block을 가리킨다. single direct에서 처리가능한 크기가 넘어가게 되면 double indirect를 사용한다.
double indirect는 index block을 가리키는데 이 index block은 또다시 index block을 가리킨다. 즉 2-level page table과 동일하다.
triple indirect는 이 단계가 3단계로 이루어져 있다.
inode에서 direct block, single indirect, double indirect, triple indirect가 각각 지원할 수 있는 최대 크기를 계산해보자.
Block size는 4KB, direct block 개수는 12개, block 주소는 4byte 라고 가정하자.
- Direct blocks : 4KB * 12 = 48KB
- Single Indirect : 1024 * 4KB = 4MB
- Double Indirect : 1024 * 1024 * 4KB = 4GB
- Triple Indirect : 1024 * 1024 * 1024 * 4KB = 4TB
이는 block 주소 크기 등을 가정한 후의 계산값으로 실제 파일시스템이 지원하는 파일 최대크기와는 다름을 참고하자.
왜 이런 방식을 사용할까?
inode 같은 방식을 사용하면 inode의 크기가 고정이 된다. inode는 파일당 1개씩 존재하며 시스템에서 파일의 개수만큼 존재한다. inode는 파일의 metadata 그 자체인데 이에 대한 크기가 파일의 크기와 관계없이 모두 동일하므로, 파일의 크기가 늘어나도 충분히 유연성을 확보할 수 있어 관리하기 편하다.
Extent
Linux의 ext2, ext3 파일시스템은 위와같이 Multi-Level index 방식을 사용하여 block mapping 체계를 제공한다. 다만 이 방식은 크기가 작은 파일에 대해서는 효율적이나 큰 파일에 대해서는 높은 오버헤드를 가진다. 구조상 파일의 크기가 조금 커지면 disk 에 반드시 fragment가 일어나게 되고 파일을 처음부터 연속적으로 읽어도 random access 가 많이 발생할 수 밖에 없다.
그리고 위의 block pointer 지정방식은 공간낭비도 심하다. 예를들어 single direct 방식에서 각 block 이 4, 5, 6, 7, 8 를 가리킨다면 각 주소가 4byte 일때 4 * 5 = 20 byte 를 차지한다. 하지만 이는 연속된 block 일때 (4, 5) 라고 표현할 수 있다. (5개의 block 이 연속되어 있다는 의미)
물론 연속된 block 이 아니라면 매 block 마다 (4, 1), (5, 1) 처럼 될 것이다.
이처럼 매 block 마다 pointer를 적용하는 방식대신 포인터와 length를 명시함으로서 연속된 block을 명시하는 방식을 적용한 것이 extent 이다.
ext4 파일시스템은 이 extent 를 사용한다. 위의 inode 구조체에서 앞부분은 ext3의 inode와 동일하고 single indirect block 의 필드부터 indirect block 대신 extent 들을 가짐으로서 최대한 하위호환성을 유지했다.
이런 extent 기반의 방식은 disk 에 충분히 여유있는 공간이 있고 파일의 block 이 연속적으로 할당될 수 있을때 가장 높은 효율을 낼 수 있다.
Directory Implementation
Directory는 파일들의 묶음을 나타내는데, 이는 굉장히 독특한 자료구조를 가진다.
Directory entry라는 Directory를 표현하기 위한 자료구조가 존재한다. 파일시스템에 따라서 directory entry를 구성하는 필드도 달라진다. MS-DOS에서의 Directory entry와 Linux에서의 Directory entry를 살펴보자.
Directory in MS-DOS
MS-DOS는 파일구현에 Linked List Allocation 방식을 사용한다. 여기서 사용하는 Directory entry 구조는 다음과 같다.
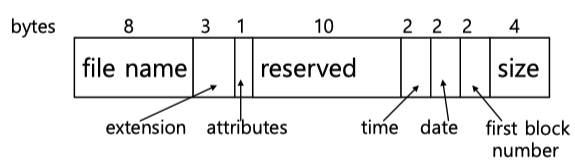
그림을 보면 첫 8byte는 file name을 가지고 다음 3byte는 extension을 가진다. extension은 따라서 3글자까지만 지원을 한다. 그리고 뒤에 first block number 부분이 있는데 이 값이 linked list의 첫번째 block을 가리킨다.
Linked List Allocation 방식을 사용하므로 맨 처음의 data block만 알면 전체 파일의 data을 알 수 있다.
Directory in Linux
Linux에서는 directory를 특별한 타입의 file로 간주한다.
그래서 디렉토리도 inode가 존재한다.
Linux에서의 directory entry는 file name과 inode로 이루어진다.
MS-DOS와는 다르게 directory의 metadata 정보는 inode 자료구조에 담겨있다.
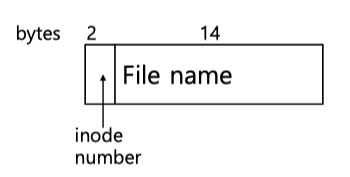
디렉토리의 inode는 type에 regular file이 아닌 directory라는 타입으로 명시되어있고 inode의 data block에는 그 directory의 내용이 저장되어있다. 그렇기에 우리의 directory 구조는 영구히 저장될 수 있다.
Directory lookup in Linux
리눅스에서 directory를 lookup 하는 과정을 살펴보자./usr/ast/mbox path에 있는 mbox라는 파일에 접근한다고 가정하자. 이 과정을 그림을 표현하면 다음과 같다.
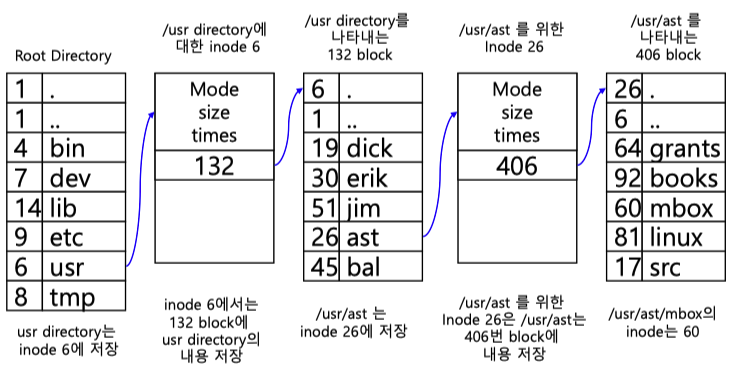
처음의 시작은 Root Directory에서 시작한다. 그림의 맨 왼쪽은 root directory의 inode의 data block의 내용을 그림으로 표현한 것이다. 물리 disk에 있는 block들은 파일의 내용도 가질 수 있으며 directory의 내용도 가질 수 있다. 여기서 usr directory를 찾고 그에 대한 inode로 가서 data block을 읽는다.usr는 directory 이므로 이에 대한 data block은 다시 directory entry들을 담고있다. 여기서 ast directory의 inode를 찾고 이에 대한 data block을 다시 읽는다. ast도 directory 이므로 data block은 또다시 directory entry를 담고있다.
최종적으로 mbox파일을 찾고 이 inode의 data block을 읽음으로서 파일을 읽게된다.
이를 정리해보면 disk 접근횟수가 상당히 많다. 이를 개선하기위해 directory cache를 사용하며 directory cache는 hit rate가 99% 정도로 매우 높은 hit rate를 가진다. directory entry가 inode number + file name 이므로 크기가 크지않다.
directory cache는 시스템이 부팅할때 root directory부터 읽어 캐싱을 한다.
Free space management
파일시스템이 inode가 할당되어 있는지, data block이 할당되어 있는지 tracking을 해야한다. 그래야 새로운 파일을 생성할 때 적절한 space를 할당해줄 수 있다.
예를들면 파일을 만들면 inode를 할당한다. 이때 inode table을 보고 비어있는 위치에 inode를 할당한다. 예를들어 inode table이 bitmap으로 구현되어있다면 해당 순서의 bit를 1로 설정한다.
또 새로운 파일에 대한 data block 또한 할당을 해야한다. 이 data block 을 할당할때에도 여러가지 기법을 사용한다.
ext2나 ext3 파일시스템의 경우에는 사용하지 않으면서 연속된 약 8개의 block들의 묶음을 찾고 이를 할당함으로서 파일시스템이 파일의 부분이 contiguous하도록 보장해주어 성능향상을 꾀한다.
이러한 방법을 pre-allocation이라고 하며 자주 쓰이는 방법이다.
Very Simple File System
파일시스템이 정확히 어떻게 구성되어있고 작동하는지를 알아보기 위해 예시로 아주 간단한 파일시스템을 보자.
이를 Very Simple File System 이라고 부르고 이하 vsfs 라고 부르겠다.
우리는 disk partition 이 있고 이 disk를 block 단위로 나눌 수 있다. block은 일반적인 크기인 4KB로 하겠다.
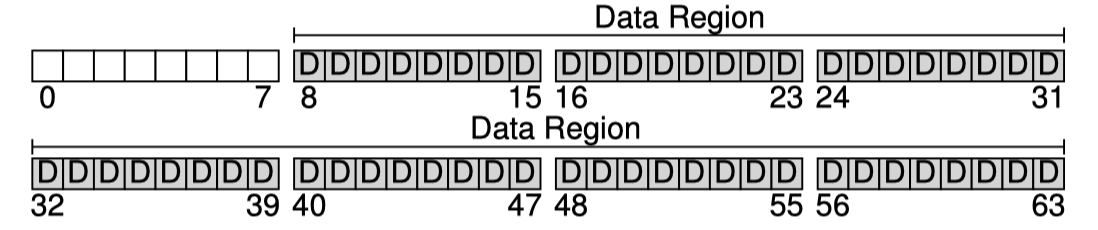
아래는 우리의 disk partition 에 대한 그림이다. 총 64개의 block 들로 나누어져 있고 각 block의 주소는 0부터 63까지이다.
disk partition 의 크기는 64 * 4 KB 인 아주 작은 partition 이다.

우리는 이 block 들에 무엇을 저장해야할까? 가장먼저 user data 가 떠오를 것이다. 실제로도 파일시스템의 대부분의 데이터는 user data 이다.
이런 user data 가 담기는 부분의 영역을 data region 이라고 부르자. 그리고 간단하게 64개의 block 중 56개를 data region 이라고 미리 정해두자.
위에서 보았듯이 파일시스템에서 각 파일을 추적하기위해 metadata 가 필요하다. 즉 inode 가 필요하다.
각 파일의 data block 의 위치가 어떻게 되는지, 파일의 크기는 어떻게되는지 등을 저장한다.
우리는 이런 inode 들 또한 disk 에 저장해야한다. 이들을 저장하기 위한 영역도 미리 정해두자. 64개의 block 중 5개를 잡고 이 영역을 inode table 이라고 하자.
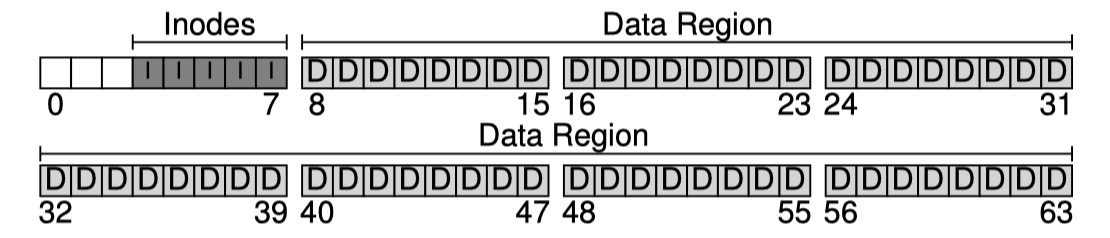
inode의 크기는 보통 그렇게 크지는 않다. inode 한개가 256 byte 라고 가정하자. 그러면 4KB 크기인 block 1개에는 64개의 inode를 저장할 수 있다.
그러므로 우리의 inode table 은 5개의 block 으로 구성되어 있으므로 총 80개의 inode를 저장할 수 있겠다. 이는 우리가 설계한 vsfs 에서 가질 수 있는 최대 파일개수와 같다.
실제 파일시스템에서는 훨씬 더 큰 크기의 disk를 가지고, 단순하게 더 큰 크기의 inode table 영역을 잡을 수 있기때문에 훨씬 더 많은 파일을 가질 수 있다.
우리는 inode table 영역을 할당하고 이를 I 로 표시하였고 date region 영역을 D 로 표시하였다. 하지만 궁극적으로 inode 나 data block 이 할당되어있는지를 추적할 수 있는 장치가 필요하다. 이런 할당여부에 대한 추적은 어떤 파일시스템이든 꼭 필요한 내용이다.
이런 할당여부를 추적하기 위해 여러가지 방법을 생각해볼 수 있지만 우리는 간단하게 bitmap 을 활용하여 표시할 것이다. 2개의 bitmap을 사용하여 한 개는 inode bitmap 으로 사용하고 다른 한개는 data bitmap 으로 사용한다.
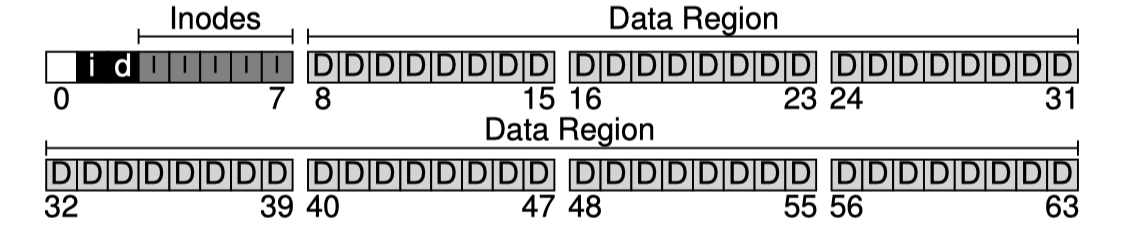
각 bitmap 을 각각 한 개의 block 에 할당했다. block 한개는 4KB 이므로 약 3만 2천개의 bitmap을 저장할 수 있다. 우리는 80개의 inode 그리고 56개의 data block 을 가질 수 있기때문에 bitmap 을 과도하게 크게 설계했지만 간단한 예제이므로 그렇다고 하고 넘어가자.
그리고 0번째 block 이 남아있다. 이를 super block 으로 할당하자. super block 은 파일시스템의 정보를 포함한다.
파일시스템에 몇 개의 inode가 있는지 몇개의 data block을 사용하는지 inode table 은 몇번째 block 에서 시작하는지 등의 정보를 담고있다.
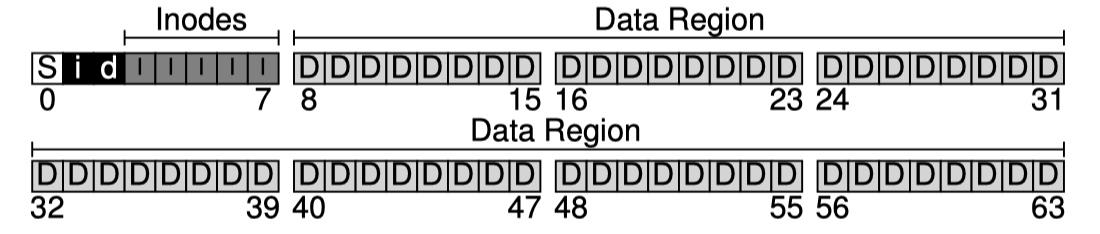
그래서 파일시스템을 mount 하면 OS가 먼저 super block을 읽어서 어느부분 부터 읽어들여야 하는지 알아낸다.
inode는 보통 inode 마다 할당되는 번호가 있다. 이 vsfs 에서는 총 80개의 inode를 담을 수 있으므로 0번부터 79번까지 번호가 존재한다.
따라서 파일시스템이 특정번호의 inode에 접근이 필요할때에면 inode의 번호로 바로 주소를 계산해서 접근할 수 있다.
보통 disk는 sector 단위로 접근이 가능하기 때문에 (inode table 시작주소 + (N * sizeof(inode)) / 512 로 나누면 sector 번호를 알아낼 수 있다.
inode table의 시작주소는 super block 을 보고 알아낼 수 있다.
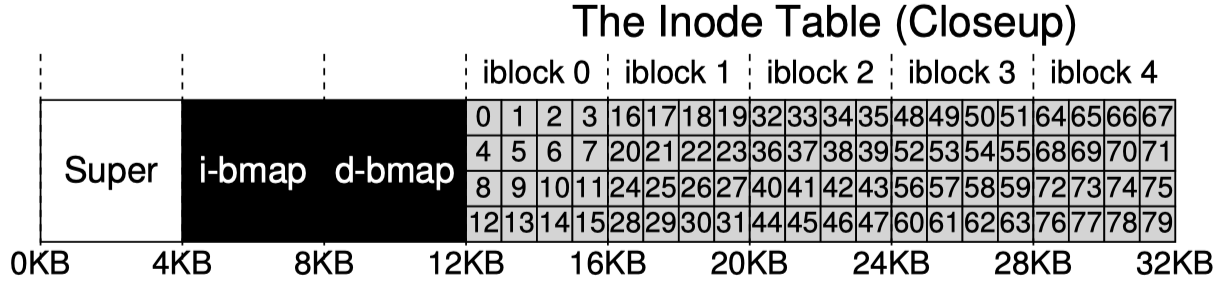
파일을 새로 만들어야 할때에는 inode bitmap을 보고 비어있는 곳을 찾아 inode 를 새로 할당하고, data block 도 data bitmap 을 보고 비어있는 block 을 찾아 할당한다.
이 vsfs 예제를 보고 파일시스템 구현의 감을 잡으면 된다.