파일시스템 1편 - 하드디스크
이 글은 학부 System Programming 수업을 듣고 다른 자료들과 함께 공부한 내용을 정리한 글입니다.
처음으로 파일시스템 자체를 보기전에 물리적인 device의 작동원리에 대해 이해를 하고 파일시스템을 보게되면 더 이해가 쉽습니다. 이번 편에서는 하드디스크에 대해 다룰 것입니다.
이번 편은 이전의 운영체제 3편 - 컴퓨터 구조와 I/O 글의 I/O 부분을 이해하고보면 도움이 됩니다.
Disk Interface
가볍에 Disk의 Interface를 알아보자.
Disk는 많은 sector라는 것으로 이루어져 있고 각 sector는 읽거나 sector에 값을 쓸 수 있다. sector에는 번호가 있는데 0 부터 n - 1 까지 있다고 하면 총 n개의 sector가 disk에 있다고 할 수 있다.
우리는 disk를 sector의 리스트로 생각할 수 있고 이 sector 들의 리스트가 disk의 address space를 결정한다.
sector는 특별한 이유가 있지 않은이상 512byte의 크기를 가진다.
다만 파일시스템에서는 block 이라는 단위로 디스크에 접근하는데 이는 4KB이다. 즉 파일시스템은 block 단위로 디스크에 읽고 쓴다.
하지만 disk에서는 sector 단위(512byte)에서의 write만 atomic을 제공한다. 즉 block write를 하면 연속된 8개의 sector에 데이터를 쓴다. 그러나 각 sector 단위에서의 atomic만 보장하므로 write 하는 순간 disk에 문제가 생기면 block의 일부분만 쓰여지는 문제가 발생할 수 있다. 이를 torn write이라고 부른다.
밑에서 보게되겠지만 서로 인접해있는 sector들을 읽는 것이 random한 위치의 sector들을 읽어들이는 것보다 훨씬 빠르다.
Disk Structure
우선 대략적인 그림을 보며 Disk 구조를 알아보자.
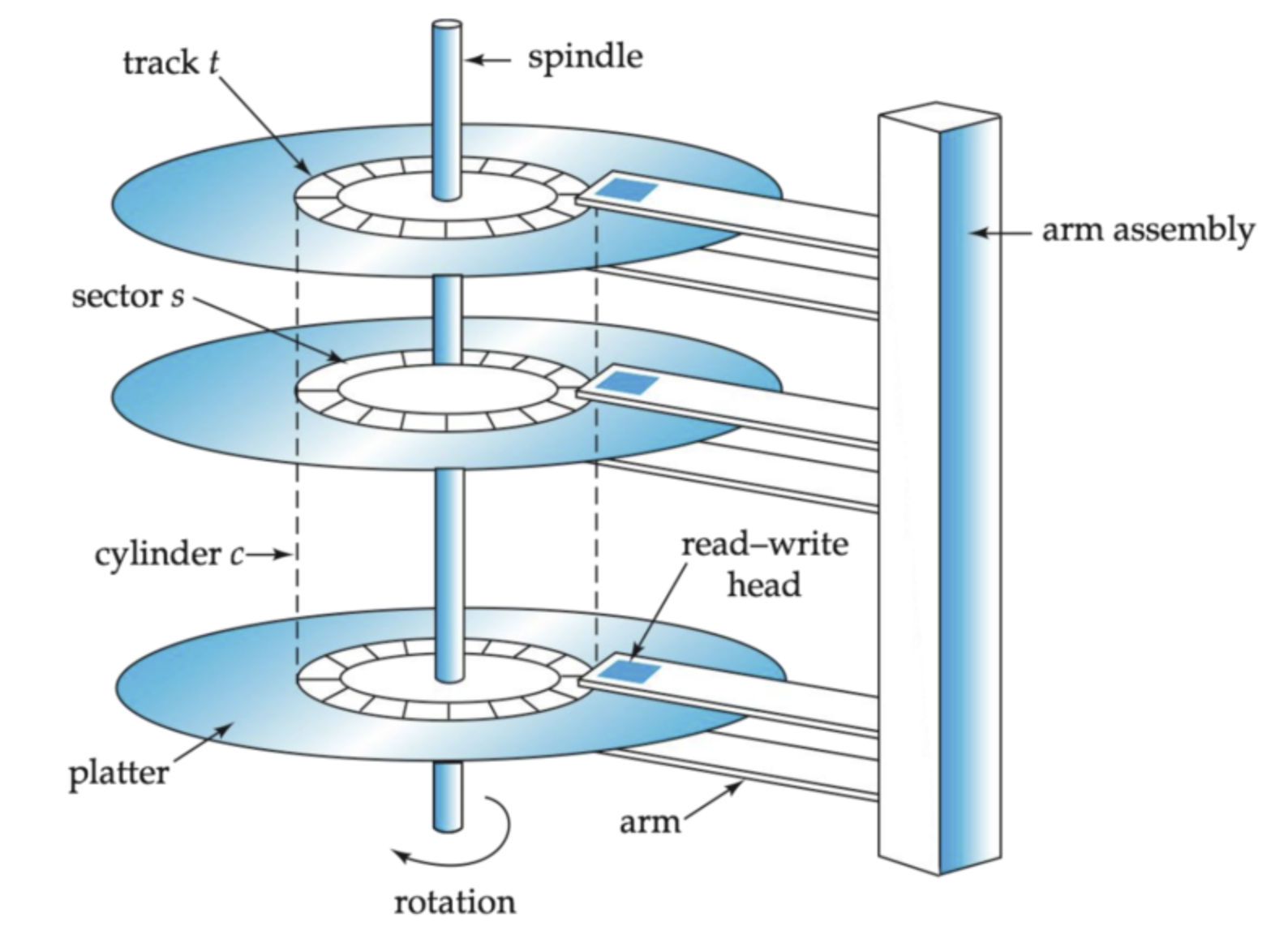
platter
디스크는 최소 하나이상의 platter들로 이루어져 있다.
위 그림에서 CD처럼 생긴 것을 platter라고 부른다. platter는 원형의 강한 재질로 이루어진 표면들로 구성되어 있고 이곳에 전자기적으로 데이터를 영구히 저장한다.
platter는 윗부분, 밑부분 각각 데이터를 저장할 수 있다.
보통 platter는 알루미늄으로 만들고 겉부분을 아주 얇은 자기성 성질을 가진 층으로 코팅한다. 이 부분에 자기성 성질을 가지므로 데이터를 영구히 저장할 수 있다.
그리고 이 platter는 가운데 spindle이라는 것에 붙어있으며, 이 spindle은 모터에 연결되어있어 platter들을 회전하도록 한다.
이런 회전율을 RPM(Rotations Per Minute)으로 보통 측정하며 요즘에는 보통 7200rpm 부터 15000rpm 까지 가진다.
10000rpm은 single rotation이 대략적으로 6ms정도 걸린다.
일반적으로 platter는 계속해서 회전을 하고있다.
track
위에서 본 sector들이 원형으로 배치된다. 이런 원형 하나를 track이라고 부른다. 하나의 platter 표현에는 수천개의 track이 존재하며 거의 사람머리카락 수준의 두께를 가지고있다.
하나의 track에 대한 대략적인 그림은 다음과 같다.
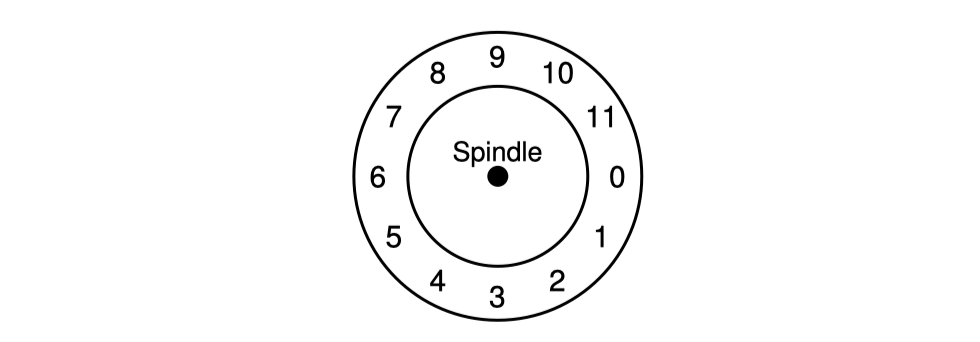
이 track은 12개의 sector들로 이루어져 있고 각 sector들은 512byte이다. 각 sector들에는 주소가 있는데 여기에서는 0 부터 11까지 존재한다.
cylinder
Cylinder는 각 platter들에 같은 반지름을 가진 track들을 의미한다. 위 그림을 보고 이해할 수 있다.
Read & Write
platter의 표면으로부터 데이터를 읽고 쓰기 위해서는 disk의 전자기적 패턴을 읽어들이거나 이를 쓸 수 있어야 한다.
이러한 것들이 disk head를 통해 가능하다.
head는 platter 표면마다 한개씩 존재하며 이 head 들은 disk arm이라는 것에 붙어있다. 표면을 따라 움직이며 이들을 움직임으로서 적절한 track에 접근할 수 있다.
위에서 platter는 시계반대방향으로 회전하며, track이 회전하면서 head가 적절한 sector위에 놓여지면서 올바른 데이터를 읽고 쓸수 있다.
Disk Access
위에서 본 track 그림을 다시보자.
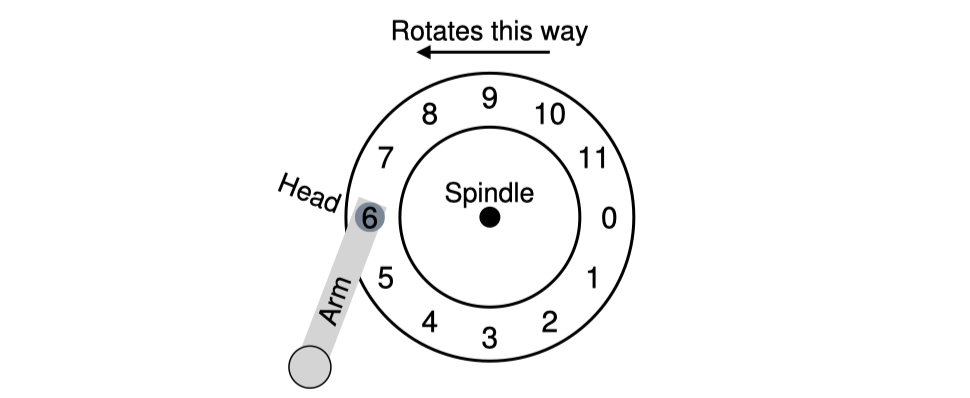
Rotational Delay
head가 6번 sector위에 놓여있는 상황에서 sector 0을 읽어야 하는 요청을 디스크가 받았다고 하자. 이를 어떻게 읽을 수 있을까?
여기서는 그냥 sector 0이 head위에 오도록 rotate 시키면된다.
이를 회전시키는데 시간이 걸리는데 이를 rotational delay라고 부른다.
위 예제에서 rotational delay가 R이라면 sector 0까지 회전하는데에는 R/2의 시간이 걸린다.
만약 sector 5를 읽어야 한다면 전체 한바퀴를 돌려야하므로 R의 시간이 걸린다.
Seek time
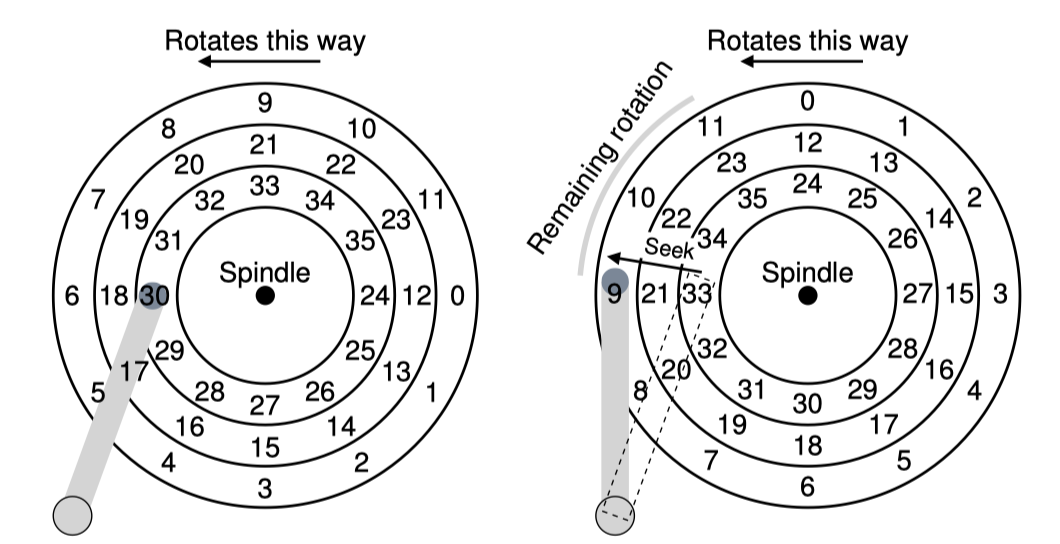
위의 왼쪽 그림에서 현재 head는 가장 안쪽 track에 sector 30번 위에 놓여있다.
여기서 sector 11번을 읽으라는 요청이 들어오면 어떻게 해야할까?
Disk는 먼저 head를 sector 11번이 있는 track으로 이동을 해야한다.
이러한 과정을 seek라고 한다. 그리고 이에 걸리는 시간을 seek time이라고 한다.
위의 오른쪽 그림에서 sector 11번을 읽기위해 head가 세번째 track으로 이동했다. 그 와중에 platter 또한 회전했다는 것을 알 수 있다. 현재 sector 9에 head가 위치하므로 rotational delay만 기다리면 원하는 sector를 읽을 수 있겠다.
Transfer Delay
위의 예제에서 sector 11번이 head를 지날때 데이터를 읽거나 데이터를 write한다.
이를 transfer라고 한다. 그리고 이에 걸리는 시간을 transfer delay라고 한다.
보통 transfer delay는 I/O Bus를 통해 memory에 저장이 될때까지의 시간을 포함한다. 여기서 disk head가 읽어들이는 시간과 이를 DMA engine이 읽어들이는 시간보다 가장 영향을 많이 받는 것은 I/O Bus의 latency 이다. DMA engine은 충분히 빠르다.
그래서 결국 데이터를 읽거나 쓰려면 원하는 track을 seek하고 적절한 sector에 접근하기 위해 rotational delay를 기다리고 그리고 transfer 하게된다.
Track skew
보통 track의 경계를 넘어 head가 왔다갔다 할때에도 rotational delay를 줄여 연속적인 읽기가 가능하도록 sector 번호를 배치한다. 아래 그림을 보자.
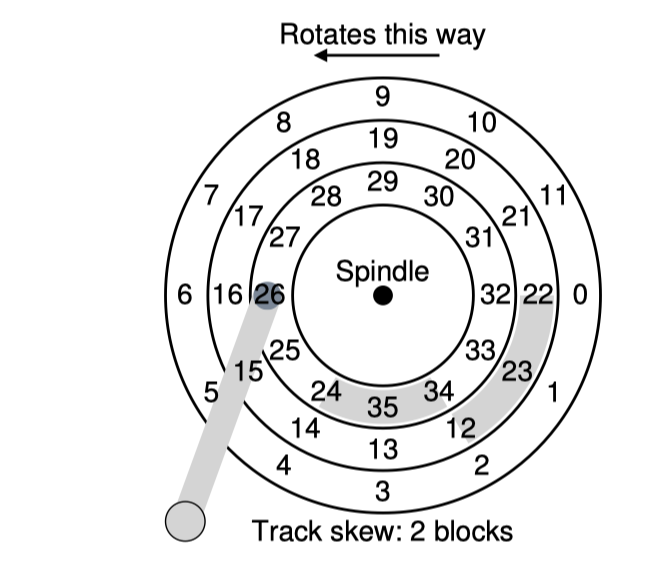
위 그림에서 읽고 싶은 sector 번호가 22, 23, 24, 25라고 하자.
head가 가장 가까운 다음 track으로 이동한다고 하더라도 head를 정확하게 reposition하는 시간이 필요하다.
이런 시간들을 고려하여 sector을 위와같이 배치한다면 sector 22, 23까지 읽고 head를 옮겨 seek time이 지나면 head가 sector 24번에 위치함으로서 서로 다른 track에 위치한 연속적인 sector를 읽어들일때 rotational delay를 줄일 수 있다는 것이다.
위에서는 각 track에서 sector의 시작점이 2개씩 차이난다.
Multi-zoned
track이 바깥쪽에 있을수록 원형구조상 sector들을 더 많이 가질 수 밖에 없다.
그래서 연속적인 track을 묶어 이들을 각각 zone이라고 부르고, 같은 zone에 있는 track들은 같은 sector 개수를 가진다. 원형의 가장 바깥쪽에 위치한 zone들의 track은 가장 많은 sector 개수를 가진다.
Cache
요즘 대부분의 disk 안에는 캐시가 존재한다. 이를 track buffer라고 부르며 보통 작은 크기의 메모리로 구성된다.
예를들어 특정 sector을 읽어야하는 요청이 들어오면, 그 track의 모든 sector를 읽고 buffer에 저장해놓는다.
Write 연산은 크게 두가지 방식으로 캐시를 활용할 수 있다.
첫번째로는 write 요청을 memory에만 써놓고 이를 비동기적으로 disk에 동기화시킨다. 이는 write 요청에 대한 응답이 매우 빠르지만 disk에 반드시 쓰여졌음을 보장할 수 없다. 이런 방식을 write back이라고 부른다.
두번째로는 실제로 write 요청시 disk에 쓰고 buffer을 날려버릴 수 있다. 이런 방식을 write through라고 부른다.
I/O 시간 계산
결국 Disk I/O 시간은 다음과 같이 계산된다.
TI/O = Tseek + Trotation + Ttransfer
Disk에서는 Rate of I/O라는 단위로 성능을 측정해서 비교하곤 한다. Rate of I/O는 간단하게 1초동안 얼마나 I/O를 처리할 수 있는가로 이해할 수 있다. Rate of I/O는 일정시간동안 I/O를 처리하고 transfer 할 수 있는 크기를 I/O를 처리하는데 걸린 시간으로 나누면 된다.
RI/O = Sizetransfer / TI/O
예제로 disk의 random access와 sequential access의 Rate of I/O를 측정해보자.
예제의 기준으로 사용한 disk는 Seagate의 높은 성능을 가진 SCSI drive인 Cheetah 15K.5와 SATA drive인 Barracuda이다. 이에 대한 스펙은 다음과 같다.
| Cheetah 15K.5 | Barracuda | |
|---|---|---|
| Capacity | 300 GB | 1 TB |
| RPM | 15,000 | 7,200 |
| Average Seek | 4ms | 9ms |
| Max Transfer | 125 MB/s | 105 MB/s |
| Platters | 4 | 4 |
| Cache | 16 MB | 16/32 MB |
| Connects via | SCSI | SATA |
먼저 random location의 4KB 크기의 read가 발생할때 시간이 얼마나 걸릴지 계산해보자.
먼저 Chheta 15K.5 의 경우이다.
Tseek = 4ms, Trotation = 2ms, Ttransfer = 30 micro sec
average seek time은 표에서 찾을 수 있다.
rotation은 15000rpm을 가지므로 한번 rotate시 4ms 걸린다. 보통 평균으로 절반을 회전하므로 2ms로 계산한다.
transfer time은 125 Mega Byte per sec을 역산하면 30 micro sec이 걸린다. 대략적으로 4KB의 I/O 시간은 6ms 가 되겠다.
그러므로 이를 기반으로 Rate of I/O를 계산하면 Cheetah 15K.5의 random access read의 RI/O는 대략적으로 0.66MB/s 이다.
만약 sequential read 이고 100MB 대상으로 파일을 읽는다고 해보자. 이 경우에는 sequential read이므로 1 seek, 1 rotation 그리고 대량의 transfer time이 걸릴 것이다.(물론 sector들이 여러개의 track에 있을 수 있지만 그냥 가정이다.)
4KB에 30 micro sec의 시간이 걸렸으므로 100MB에는 768ms가 걸린다. 대략적으로 800ms 걸린다고 가정한다면 100MB의 read에는 800ms가 걸린다.
이를 기준으로 sequential read의 RI/O는 125MB/s 이다.
Barracuda도 이와 동일하게 계산하면 결과는 다음과 같다.
| Cheetah 15K.5 | Barracuda | |
|---|---|---|
| RI/O Random | 0.66 MB/s | 0.31 MB/s |
| RI/O Sequential | 125 MB/s | 105 MB/s |
위의 결과를 보면 Random access와 Sequential access의 성능차이는 어마어마 하다. 거의 200배, 300배 차이가 나는 것을 볼 수있다.
또한 제품마다 특성이 다르며 각 용도에 따라 올바르게 disk를 선택하는 것이 좋다.
예를들어 RPM 수치가 높다고 반드시 좋은 것은 아니다. RPM이 높아질수록 안정성이 떨어지기 때문이다. 데이터를 오랫동안 안정적으로 보관하려면 낮은 RPM 제품을 선택하는게 도움이 될 수 있다.
Disk Scheduling
위에서 성능을 보았듯이 disk I/O는 millisecond 단위로 동작하기 때문에 비용이 꽤 높은 작업이다. 따라서 전통적으로 OS는 이를 개선하기 위해 I/O 작업들의 순서를 결정하는 역할도 같이 했다.
Kernel 내부 disk controller에 Disk I/O 요청을 담아두는 queue를 두고 이 queue를 보고 알고리즘에 따라 순서를 변경한다.
Scheduling에는 여러가지 방식이 있는데 이를 하나하나 상세히 알아보지는 않을 것이다. 이해하는데 난이도도 어렵지 않으며 우리가 Disk scheduling을 걱정할 필요가 없기때문이다. 이는 이미 기술이 다 완성되었다고 판단할 수 있으며 우리가 scheduling 알고리즘을 바꾸거나 할 경우는 없다.
Disk Scheduling 알고리즘에는 seek time을 최소화하는 SSTF, 엘레베이터 알고리즘과 비슷한 SCAN 방식 등이 존재한다.
하지만 이들은 head의 움직임에 대한 cost만 고려하지 rotate는 고려하지 않는다. 이들을 해결하기 위한 알고리즘이 SPTF 알고리즘이다.
SPTF(Shortest Position Time First)
SPTF는 어떤 정해진 알고리즘이라는 느낌보다는 그 때의 경우에 따라 적절하게 처리하는 알고리즘이라고 이해하면 쉽다.
아래의 예시를 보자.
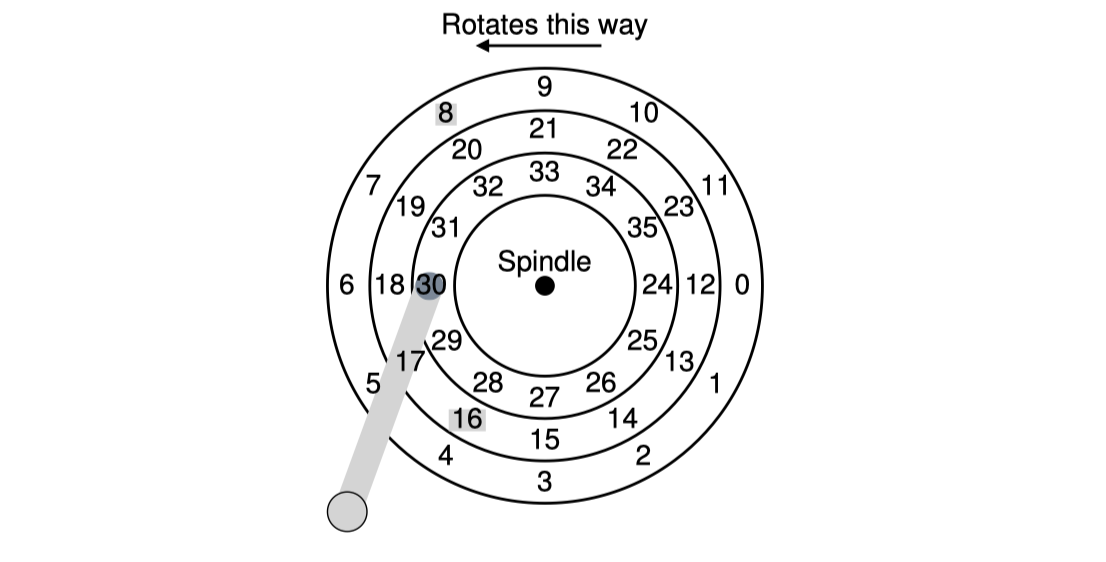
현재 head가 sector 30번에 있고 그 다음에 방문해야 하는 sector가 16과 8이 있다. 어느 sector를 먼저 방문해야할까?
이는 경우에 따라 다르다.
만약 seek time이 rotational delay보다 훨씬 오래걸린다면 sector 16번부터 방문하는 것이 합리적일 것이다. 만약 그 반대인 rotational delay가 훨씬 길면 어떨까? 이 경우에는 sector 8번을 먼저 방문하는 것이 합리적이다.
요즘의 disk들은 seek time와 rotational delay가 대략적으로 비슷하다. 그러므로 각각 spec과 상황에 따라 적절하게 결정하는 것이 SPTF의 핵심이다.
SPTF는 OS에서 구현하기는 힘들고 device 내부에서 각자의 상황에 맞게 구현되고는 한다.
Scheduling은 어디서?
Disk Scheduling은 결국 어디서 일어날까?
위에서도 살짝 언급했듯이 예전에는 Disk scheduling을 모두 OS에서만 처리했다. OS에서 기다리고 있는 request 들을 queueing 하고 있다가 다음 request를 요청할때 이 queue에서 적절한 request를 선택하여 disk에 요청했다.
요즘은 disk 자체가 내부적으로 각자 device에 맞는 뛰어난 scheduling 기법을 내재하고있다. 그리고 OS도 적절하게 OS가 판단한 sector 번호를 disk에 요청하면 disk도 이를 queueing 하고 적절하게 구현한 알고리즘에 따라 처리한다.
또 한가지 볼만한 점은 OS 레벨에서 연속된 sector에 대한 요청이 있을시 이들을 merge한다.
예를들어 read 요청이 33, 8, 34 순서로 도착했다면 OS는 이를 보고 33, 34을 2개의 sector를 대상으로 하는 1 개의 request로 merge한다. 이는 disk 오버헤드를 크게 줄여준다.