파일시스템 2편 - RAID
이 글은 학부 System Programming 수업을 듣고 다른 자료들과 함께 공부한 내용을 정리한 글입니다.
이전 포스트의 하드디스크에 이어 이번 포스트에서는 RAID에 대해 알아볼 것입니다.
이번 편은 이전의 운영체제 3편 - 컴퓨터 구조와 I/O 글의 I/O 부분을 이해하고보면 도움이 됩니다.
What is RAID?
RAID는 Redundant Array of Inexpensive Disks의 약자이다. 즉 여러개의 disk를 사용해서 더 빠르고, 더 크고, 더 신뢰성 있는 disk 시스템을 구축하는 방식이다.
외부적으로 보는 관점에서는 RAID는 그냥 disk와 동일하다. 외부에서는 그저 큰 disk처럼 바라볼 뿐이다. disk와 동일하게 block의 묶음을 읽고 쓸수있다. 하지만 RAID 내부적으로는 시스템을 관리하는 프로세서도 존재하고 메모리도 존재하며 무엇보다 여러개의 disk로 구성되어 있다.
RAID는 왜 쓰는 것일까?
RAID를 사용하면 먼저 성능상으로 이득을 볼 수 있다. 여러개의 disk에 병렬로 I/O를 할 수 있다. 그리고 용량(capacity)측면에서도 이득을 볼 수 있다. 한개의 disk 크기를 넘어서는 크기를 저장할 수 있기 때문이다.
그리고 신뢰성(reliability)도 더 높은데 RAID를 구성하는 방식에 따라 다를 수 있지만 데이터를 여러 disk에 중복해서 저장함으로서 single disk failure에 대해 극복할 수 있고 외부에서는 single disk failure가 일어나도 아무 일도 일어나지 않은 것처럼 수행할 수 있다.
RAID Internals
파일시스템 밑에서 RAID는 그저 매우 크고 신뢰성있고 빠른 disk 처럼 보일뿐이다. single disk처럼 linear array of blocks로 보이고 각 block은 파일시스템에 의해 읽고 쓰여질 수 있다.
파일시스템이 RAID에 logical block에 대해 I/O 요청을 하면 RAID는 내부적으로 여러 disk를 가지고 있는데 어떤 disk에 접근해서 physical I/O를 할 지 결정하고, 수행한 후 그 결과를 반환한다. 이 physical I/O를 어떻게 수행할 것인가는 밑에서 볼 RAID level에 따라 다르다.
간단하게 RAID가 각 disk의 copy본을 들고있는 mirrored RAID 라고 해보자. 그러면 write을 수행할 때 각 block들을 disk에 2번씩 써주어야 한다.
RAID Evaluation
RAID를 구성하는 방법은 여러가지가 있다. 구성하는 방법에 따라 특징 그리고 장단점이 존재하는데 이런 특징을 수치로 측정할 수 있으로면 비교하기 쉽다. 그래서 우리는 3가지 측면에서 RAID의 특징을 측정할 것이다.
capacity
먼저 capacity이다. B개의 block을 저장할 수 있는 N개의 disk가 있다. 클라이언트는 RAID에 얼마나 많은 용량을 저장할 수 있을까?
중복없이 저장한다면 N * B가 되겠다. 각 block마다 copy본을 둔다면 N * B / 2가 되겠다.
reliability
두번째는 reliability 즉 신뢰성이다. RAID가 몇개의 disk failure 까지 허용할 수 있을까에 대해 이야기한다.
performance
마지막은 performance이다. Performance는 측정하기 조금 힘들 수 있는데 RAID에 요청되는 작업의 종류에 의존하는 경우가 많기 때문이다.
RAID performance를 측정할때는 크게 2가지 측면을 고려할 것인데 첫번째는 single-request latency이다. RAID에서 single I/O 요청에 대해 어떤 latency를 가지는지를 측명하면 얼마나 해당 RAID가 병렬성을 가지고 있는지 그대로 이해할 수 있다.
두번째는 steady-state throughput 이다. 어떤 규칙적인 요청이 왔을때 그때의 처리량을 의미한다. 예를들어 여러개의 요청이 동시에 왔을때 그때의 RAID 전체의 bandwidth를 측정할 수 있겠다.
이들을 조금 더 자세히 측정하기 위해 각 요청에 대한 내용들이 두가지 종류가 있다고 가정한다. sequential과 random이다.
sequential workload는 요청들이 큰 단위의 연속된 block을 읽는 요청들로 이루어져 있다고 가정한다. 이런 sequential workload는 큰 파일을 읽어 특정 키워드를 찾고싶을때처럼 자주 오는 요청들이다.
random workload는 각 요청은 매우 작은 크기의 block을 읽는 요청들이고 각 요청들은 서로 다른 disk location을 대상으로 한다. 예를들어 처음 4KB에 대해 logical address 10에 접근하고 그다음은 logical address 55,000 그 다음은 logical address 4,500 에 접근하는 방식이다. 이런 random workload는 database에서 빈번하게 일어난다.
위의 sequential, random workload는 disk의 특성으로 인해 각각 다른 performance 특징을 가진다.
sequential access에서는 disk는 가장 효율적인 방식으로 동작한다. seek time과 rotational delay에 매우 적은 시간을 사용하므로 대부분의 시간을 data transfer에 활용할 수 있다.
다만 random access의 경우는 대부분의 시간을 seek time과 rotational delay에 사용하므로 상대적으로 data transfer에는 작은 시간을 할애할 수밖에 없다.
그래서 이런 차이점을 더 명확히 확인하기 위해 sequential workload 에서는 S MB/s 로 data transfer가 가능하다고 하고, random workload 에서는 R MB/s 속도로 data transfer가 가능하다고 하자. 보통은 S가 R보다 훨씬 크다. 이 측정치를 밑에서 RAID level 별로 계산해보며 성능을 비교해볼 것이다.
밑에서는 몇가지 RAID 종류들을 보게될 것이다. RAID Level 0(striping), RAID Level 1(leveling), RAID Levels 4, 5(parity-based redundancy)이다.
RAID Level 0: Striping
RAID 0은 striping으로 더 잘 알려져 있다. 이 방식은 capacity와 performance 측면에서 높은 결과를 낸다.
striping은 말그대로 줄무늬 방식이라고 이해해도 좋다. striping 방식에서는 각 block들을 여러 disk에 걸쳐 줄무늬처럼 배열한다. 다음 그림을 보자.

여기서는 4개의 disk를 사용했다. striping의 기본 아이디어는 block의 array를 라운드로빈 방식으로 disk에 하나씩 할당한다. 이 방식은 large sequential read 요청에 대해 병렬로 처리할 수 있도록 설계한 방식이다.
위의 예에서는 1개의 block(4KB) 기준으로 라운드로빈으로 disk에 할당하였는데 다음과 같이 할당할수도 있다.

여기서는 다음 disk로 넘어가기 전에 2개의 block(8KB)를 할당하고 다음 disk로 넘어갔다. 이 단위를 chunk size라고 한다. 여기서는 8KB의 chunk size를 사용하였다.
Chunk Size
chunk size는 performance에 영향을 많이 끼친다. 작은 chunk size를 사용한다면 많은 파일들이 여러 disk에 striped 되어 저장될 것이다. 그러므로 파일 read write 시에 병렬성을 증가시킬 수 있을것이다.
다만 block에 접근하기 위한 positioning time(seek time + rotational delay)가 증가한다. 왜냐하면 여러 disk에 병렬로 읽거나 쓰게될때 결국 완료시간은 가장 오랜시간이 걸린 positioning time에 의해 결정되기 때문이다.
chunk size를 크게잡으면 어떨까?
작은 크기의 파일에 대해선은 read, write에 병렬성은 떨어질 것이다. 그러나 positioning time이 줄어들 것이다. 만약 작은 크기의 파일의 크기가 chunk size보다 작아 single disk에 저장된다면 그 single disk 에서의 positioning time이 결정한다.
그러므로 최적의 chunk size를 찾기 위해서는 어떤 요청들을 위주로 처리할지에 대한 지식이 먼저 있으면 결정하기 좋다.
대부분은 큰 chunk size(64KB)를 사용하고는 한다.
RAID 0 Evaluation
RAID 0 에서 capacity, reliability, performance를 측정해보자.
먼저 capacity는 간단하다. B개의 block들로 이루어진 N개의 disk가 있다면 N * B의 block을 저장할 수 있다.
reliability도 간단한데 striping 방식에서는 reliability가 좋지 않다. 하나의 disk가 fail이 나더라도 바로 data loss로 이어진다.
performance는 위에서 본 sequential workload의 S와 random workload의 R을 구해보며 비교해보자.
sequential transfer size는 평균적으로 10MB, random transfer size는 평균적으로 10KB라고 가정하자. 이들을 전송하는데 속도가 얼마인지 계산해보자.
Disk의 spec은 다음과 같다.
- Average seek time: 7ms
- Average rotational delay: 3ms
- Transfer rate of disk: 50MB/s
S는 (Amound of Data) / (Time to access) 이므로 10MB / (7ms + 3ms + 200ms) = 47.62 MB/s 와 같다. Time to access는 seek time + rotational delay와 10MB를 전송하는데 200ms가 걸리므로 이를 합치면 계산할 수 있다.R은 10KB / 10.195ms = 0.981 MB/s이다. 10KB를 전송하는데 0.195ms가 걸린다.
이 S와 R은 disk 1개에서 고려한 속도이다.
이처럼 striping의 performace를 보게되면 single-block request에 대해서는 single disk 성능과 동일하다.
하지만 sequential, random workload 관점에서 볼때 sequential workload는 하나의 disk가 S의 속도를 낼때 N개의 disk가 있다면 전체 처리량은 S * N이 되겠다.
randon workload 에서의 전체 처리량은 R * N이 된다.
RAID Level 1: Mirroring
RAID Level 1은 mirroring으로 잘 알려져있다. Mirrored System에서는 각 block에 대해 copy본을 같이 저장함으로서 disk failure를 극복할 수 있다. 전형적인 mirroring 방식은 다음과 같다.

위의 방식에서는 RAID는 물리적으로 두개의 물리적 copy를 저장한다. disk 0은 disk 1과 동일한 내용을 들고있고 disk 2는 disk 3과 동일한 내용을 들고있다. 데이터들은 이 mirror pair들에 걸쳐 striped 된다.
disk들에 copy본들을 어디에 위치시킬지는 여러가지 방법이 있는데 위에서 본 방식은 가장 일반적인 방식으로 이런 방식을 RAID-10이라고 부르기도 한다. stripe of mirror로 RAID1+0 라는 의미이다.
disk read를 할때는 복제본 disk 두개중 어디에서 읽어도 상관없다. 다만 write은 두개의 disk에 모두 써주어야 한다. 이 2번의 write은 병렬로 처리할 수 있다.
또 위의 경우 복제본을 2개 저장했는데 이를 mirroring level이라고도 한다. 여기서는 mirroring level이 2이다.
RAID 1 Evaluation
RAID 1 에서 capacity를 먼저보자. capacity 관점에서 RAID 1은 비용이 비싸다. mirroring level 2 에서는 전체 용량의 절반만 저장할 수 있으므로 capacity는 N * B / 2가 되겠다.
reliability의 관점에서는 좋다. 아무 disk 1개의 failure를 허용할 수 있다. 사실 정확히는 최대 N/2개의 disk failure 까지 허용가능하다. 위에서 본 예제에서도 만약 운이 좋게도 disk 0과 disk 2가 동시에 fail 했다고 하더라도 data loss가 발생하지 않는다. 운이 좋게 각 copy 본을 저장하는 disk가 중복없이 fail이 발생했기 때문이다.
performance 관점을 살펴보자. single read request는 single disk와 성능이 동일하다.
다만 single write request는 살짝 더 latency가 늘어날 수 있는데, 각 copy 본을 병렬로 write한다고 하더라도 완료되는 시점은 두개의 disk중 더 오래걸린 시간이기 때문이다.
steady-state throughput을 살펴보자.
sequential write에서는 각 logical write은 두개의 physical write으로 나누어진다. 그러므로 mirroring 방식에서 전체 bandwidth는 (N / 2) * S가 된다. 최대 bandwidth의 절반밖에 안된다.
sequential read도 똑같은데 얼핏 생각하면 각 logical read를 모든 disk에 나누어 처리하면 상황이 더 나아질 것 같지만 disk의 물리적 특성을 생각하면 그렇지 않다. 예를들어 위의 그림에서 block 0 부터 7까지 읽는다고 했을때 block 0은 disk 0에서, block 1은 disk 2에서, block 2는 disk 1에서 block 3은 disk 3에서 읽는다고 해보자. disk 0에서는 block 0을 읽고 그다음 block 4를 읽으면 될 것 같지만 어차피 중간에 block 2가 존재하기 때문에 rotation 하면서 이를 지나가야한다. 그러므로 성능향상이 없다. 그러므로 sequential read 에서의 전체 bandwidth도 N / 2) * S와 같다.
Random read는 mirroring 방식에서 best case이다. read를 전체 disk에 분산시킬 수 있으므로 N * R MB/s의 대역폭을 가진다.
Random write은 sequential write과 동일하게 두개의 physical write로 나누어지므로 (N / 2) * R MB/s 이다.
RAID Level 5: Rotating Parity
RAID Level 5에서는 parity 정보를 활용한다.
Parity bit은 오류가 생겼는지 검사하는 bit 인데 2가지 종류가 존재한다. 짝수 parity와 홀수 parity이다.
개념은 간단한데 짝수 parity에서는 데이터의 각 bit의 값에서 parity bit를 포함한 1의 개수가 짝수가 되도록 하는 것이다. 홀수 parity는 홀수가 되도록 하는것이다. 예를들어 다음과 같다.
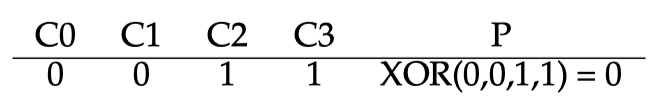
짝수 parity라면 C0, C1, C2, C3의 bit에서 1의 개수가 2개이므로 parity bit을 0으로 둔다. 그래야 짝수인 2개로 유지되기 때문이다. parity bit을 활용하면 C0, C1, C2, C3 중 한개가 유실되어도 그 값을 bit 계산으로 알아낼 수 있다.
다시 RAID로 돌아와서 RAID Level 5 방식을 그림으로 보자.
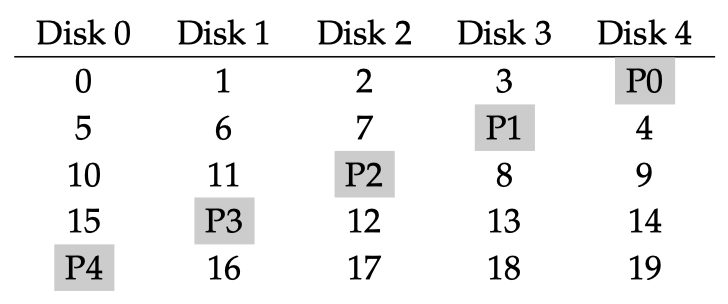
여기서는 parity bit을 disk 별로 돌아가며 설정한다. 즉 위의 block 0, 1, 2, 3의 각 block의 bit를 계산해서 그에 대한 parity bit을 disk 4에 저장한다.
RAID 5 Evalutation
capacity 부터 확인해보자. stripe 당 1개의 parity block을 두기때문에 (N - 1) * B의 용량을 가지게 된다.
reliability 는 1개의 disk failure를 허용한다. parity bit를 활용해 recovery 가능하다. 다만 2개이상의 disk failure가 나면 복구할 방법이 없다.
그렇다면 performance를 계산해보자.
single read request는 1개의 disk로 매핑되기 때문에 single disk와 성능이 동일하다.
다만 single write request는 다른데 위 예제에서 block 0에 write을 하려면 block 0을 읽고 parity block도 읽어서 parity bit를 다시 계산해야한다. 즉 read 2번, write 2번이 필요하고 read, write 각각 병렬로 처리할 수 있으므로 single disk의 latency의 약 2배정도 걸린다.
sequential read는 parity block으로 인해 (N - 1) * S MB/s의 대역폭을 가진다. sequential write도 parity bit을 같이 써주어야 하므로 (N - 1) * S MB/s가 되겠다.
random read는 모든 disk를 활용할 수 있다. 다만 random write은 (N / 4) * R MB/s을 가진다.
왜냐하면 만약 random write가 위 예제에서 block 1과 block 10에 대해 요청이 왔다면 parity bit 계산을 위해 disk 1과 disk 4를 읽어 block 1을 처리하고, disk 0과 disk 2를 읽어 block 10을 처리한다. 각 요청안에서 block data write과 parity block write은 병렬로 처리할 수 있므으로 총 4개의 I/O 가 필요하다.(disk 1의 read/write + disk 0의 read/write)
RAID Level 별로의 evaluation 결과는 다음과 같다.

Summary
reliability는 고려하지 않고 performance가 중요한 상황이라면 RAID 0 striping이 좋은 선택이 될 수 있다.
반대로 reliability가 중요하고 random I/O 성능이 중요하다면 RAID 1 mirroring이 좋은 선택이다. 다만 비용이 비싸다.
capacity와 reliability가 중요하다면 RAID 5 가 좋은 선택이다. 다만 small-write의 성능이 좋지않은면이 있다.
만약 sequential I/O가 주된 접근이고 capacity를 최대화 해야하는 상황이라면 이 경우에도 RAID 5가 좋은 선택이다.
여기서 살펴본 RAID 디자인 말고도 다른 여러가지 디자인이 존재한다. 예를들어 RAID 6은 multiple disk failure를 허용한다.
RAID는 hardware 자체로 구현되어 제공되기도 하고 software로도 구현되어 제공될 수 있다.