파일시스템 3편 - 파일시스템이란?
이 글은 학부 System Programming 수업을 듣고 파일시스템 관련내용을 정리한 글입니다.
파일(File)이란?
파일은 무엇일까?
파일은 linear array of bytes 이다. 이게 무슨말일까?
이전 운영체제 메모리편에서 보았듯이 address space는 sparse 하다. 즉 프로세스가 사용하는 주소공간은 중간부분을 사용하지 않고 비어있을 수 있다. 그러므로 효율적으로 사용하고자 multi-level page table을 사용하곤 했었다.
이와 다르게 파일은 linear array of bytes로 중간이 비어있지 않다. 그리고 파일은 byte addressable하다. Byte 단위로 접근이 가능하다는 것이다. 그리고 여기서의 linear array는 밑에서 보겠지만 logical한 block이 linear하다는 것이다.
Address space와 파일을 표로 비교해보자.
만약 Address space를 잘 모른다면 운영체제 메모리편을 참고하자.
| File | Address Space |
|---|---|
| Variable length | Fixed length |
| Persistent | Volatile |
| 연속적 | 비연속적 |
Address space는 fixed space이다. 즉 주소공간이 48bit이라면 248의 주소공간이 있다. 반면 파일은 variable한 길이를 가진다.
또 파일은 연속적이라고 표현하는데, 예를들어 파일은 이부분에 쓰고 이부분은 비워두고 하는 개념이 아니다. 하지만 Address space는 가능하다.
그럼 파일로 Database를 구현할 수 있을까?
구현할 수 있다. 다만 Database에서 제공하는 여러 기능들도 동일하게 구현을 한다면 말이다.
하지만 운영체제는 general한 서비스를 구현하는 것이 목적이고, 데이터베이스는 말그대로 data에 대한 더 구체적인 목적을 가지고 있기때문에 이 둘은 지향점이 다르다.
파일시스템(File System)
파일시스템이란 무엇일까? 파일시스템은 순수한 software이다. memory처럼 성능향상을 위해 추가적인 hardware(MMU)를 도입하거나 하는 것없이 순수한 software로 작성되었다.
파일시스템은 크게 2가지 의미를 가지고 있다.
먼저 파일은 Abstraction이다. 즉, 사용자인 우리는 파일이 정확히 디스크 어디에 있는지 모른다.
하지만 파일을 구현하려면 디스크가 있어야한다. 파일을 write하는 것과 디스크에 저장되는 것과 연결이 되어있어야 구현할 수 있을것이다.
이런 관점에서 파일시스템의 첫번째 의미로는 파일시스템은 physical storage의 종류에 관계없이 프로세스에게 read와 write을 할 수 있게끔 파일과 physical storage block간의 매핑을 제공해준다.
File blocks를 disk blocks로 매핑예시
| File block number | Disk block number |
|---|---|
| 1 | 108 |
| 2 | 3010 |
| 3 | 3011 |
이렇기에 사용자는 파일을 쓸때 이 파일이 실제 어디에 저장되는지 고민을 할 필요가 없다. 그 마법을 파일시스템이 부린다.
Block
파일은 block 단위로 자를 수 있다. 이 block은 대부분 page 크기에 맞춘다. 즉 4KB에 맞춘다.
만약 1MB 짜리 파일은 256개의 block으로 나뉜다.
왜 block size를 page size로 맞출까?
왜냐하면 파일을 읽거나 할때 block을 들고와서 memory에 써주어야 하기 때문이다. 다만 어떤 파일시스템은 4MB 파일 block을 가지는 파일시스템도 존재한다. 대신 block을 메모리에 써줄때에는 contiguous한 4MB page 묶음을 확보하기 쉬지않다.
다시 파일시스템으로 돌아가서 파일시스템의 두번째 의미를 살펴보자.
파일시스템은 디스크에 들어가있는 파일 전체를 총칭한다. 즉, 파일시스템이 파일들의 집합이라는 의미이다. 파일시스템에 따라서 파일들의 배치나 구성이 달라진다. 파일시스템은 Windows는 NTFS를 사용하고 Linux는 ext4 등을 사용한다.
즉 파일시스템의 첫번째 의미로는 software로서의 의미에 가까운 반면 두번째 의미로는 파일자체의 집합을 의미한다.
파일시스템을 그림으로 나타내면 다음과 같다.
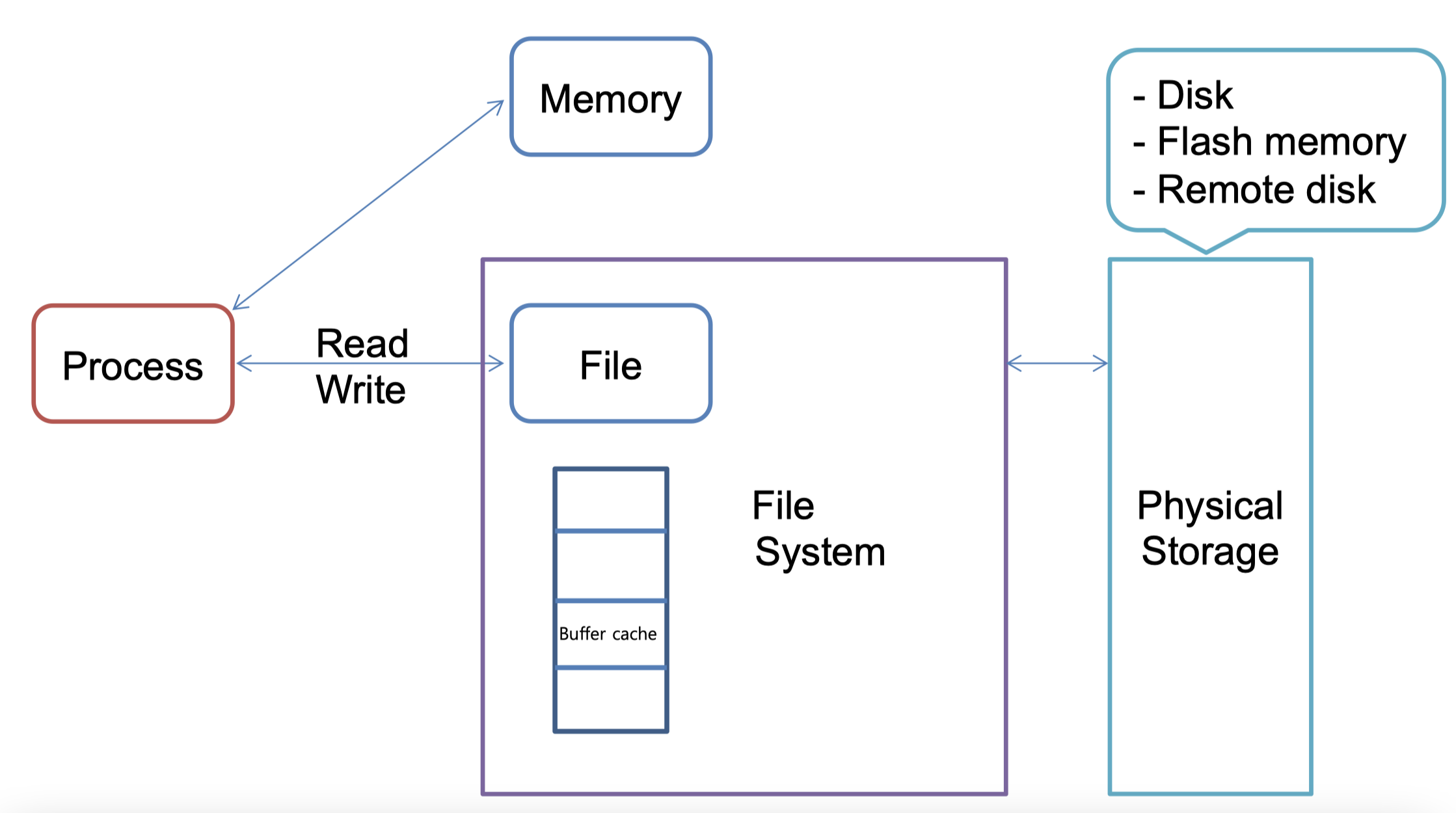
위에서의 Buffer cache 라는 것은 다음편에서 보겠지만 디스크에서 읽어온 내용을 메모리에 저장해둔 것이다. 그래서 파일을 읽는다는 것은 Buffer cache를 읽는 것이다. Buffer cache는 Kernel 영역 메모리에 위치하는데 파일시스템이 Kernel mode로 돌아가기 때문이다. 이정도로만 우선 알고있자.
Metadata
metadata는 간단하게 파일에 대한 data이다. 위에서 본 파일시스템의 block 매핑정보 자체도 metadata이다.
metadata를 살펴보는 이유는 파일시스템이 하는 일이 metadata를 관리하는 것이기 때문이다. 파일시스템에 따라서 파일들의 metadata 구성이 달라진다.
파일의 metadata에는 파일의 이름, 타입, 파일크기, storage의 block 위치, protection 관련정보들이 존재한다. 이 외에도 시간관련 data, inode(index node), directory 정보 등이 존재한다.
inode라는 것은 나중에 더 자세히 보겠지만 위에서 본 매핑정보를 가지고 있는 파일시스템에서의 핵심적인 data structure이다. 파일마다 inode가 한개씩 존재하며 metadata에 파일 개수만큼의 inode가 존재한다.
directory 혹은 폴더 라는 개념은 결국 metadata들을 모아놓은 개념이라고 볼 수 있겠다.
Metadata and caching
Metadata는 어디에 저장이 될까? metadata는 디스크에 저장이 되어 persistence가 제공된다.
우리는 파일에 접근할때 먼저 metadata를 접근하고 그 metadata에서 data 위치를 읽어서 다시 그 data에 접근해야 한다. 즉 최소한 metadata에 한번은 접근을 해야한다는 것이다.
이는 마치 메모리에서 메모리에 접근하기 위해 page table을 먼저 읽고 그 다음 적절한 physical memory address로 변환하여 다시 메모리에 접근하는 문제와 같다. 즉 메모리에 접근하기 위해 메모리를 2번 접근하는 문제이다. 이를 극복하기 위해 TLB를 사용하여 page mapping을 캐싱한다.
이와 비슷한 이유로 metadata도 캐싱한다. metadata의 캐싱은 위에서 살짝 살펴보았던 Buffer cache와는 다르다. 말그대로 metadata 캐싱은 metadata를 위한 캐싱이다.
그래서 운영체제는 부팅할때 맨처음 metadata들을 읽은다음 이들을 미리 캐싱한다.
metadata 캐싱은 asynchronous update를 사용한다. metadata 변경이 일어날때 cache를 업데이트하고 나중에 disk에 저장한다. 즉 metadata 수정이 메모리에서 수정된다는 의미이다. 그러면 inconsistency를 어떻게 처리할 수 있을까? 만약 metadata 수정이 되었지만 이 내용이 disk에 반영되지 못하고 컴퓨터가 종료되면 어떻게될까?
일단 처리하지 못한다. 그래서 OS에서 파일시스템에서 failure semantics가 보장되지 않는다고 한다. 물론 찾아보면 Journaling file system 같은 failure semantics를 보장해줄 수 있는 파일시스템이 존재한다. 혹은 checkpoint 같은 값을 써서 추가적인 failure semantics를 보장하기도 한다.
metadata caching 말고도 Directory cache 라는 것도 존재한다. 이는 directory에 대한 cache로 hit율이 99% 이상으로 매우 높은편이다.
Journaling File System
저널링 파일시스템이라고 부른다.
이는 file system에 변경사항을 반영하기 전에, journal 이라는 circular log의 변경사항을 보고 이를 기반으로 추적하는 파일시스템이다.
이를 활용하면 시스템 충돌이 발생했을때 빠르게 복구하면서 data inconsistency를 방지할 수 있다.
현재 리눅스에서 채택하고있는 ext4 파일시스템은 저널링 파일시스템이다. 파일시스템에서 보통 128MB 정도의 연속된 block을 미리 예약하고 이 공간을 Journal로 사용한다. 즉 중요한 데이터들을 이 공간에 빠르게 write한다. ext4 파일시스템은 여러가지 모드로 설정할 수 있는데 기본적인 방식은
포렌식
포렌식은 지워진 파일을 복구한다. 어떻게 이것이 가능할까?
파일을 지울때 실제 파일의 데이터를 지우는 것이 아닌 해당 파일에 해당하는 metadata를 지운다. 그래서 파일삭제는 파일크기에 관계없이 보통 빠르게 진행된다.
결국 실제 파일의 데이터는 디스크 어딘가에 남아있는데 이를 가르키고 있는 metadata들이 전부 삭제된 상황이다. 그래서 포렌식은 파일시스템의 매핑방식과 disk 데이터를 적절하게 보고 실제 데이터들을 찾아낸다.
File System layout
파일시스템의 레이아웃을 보면 다음과 같다.
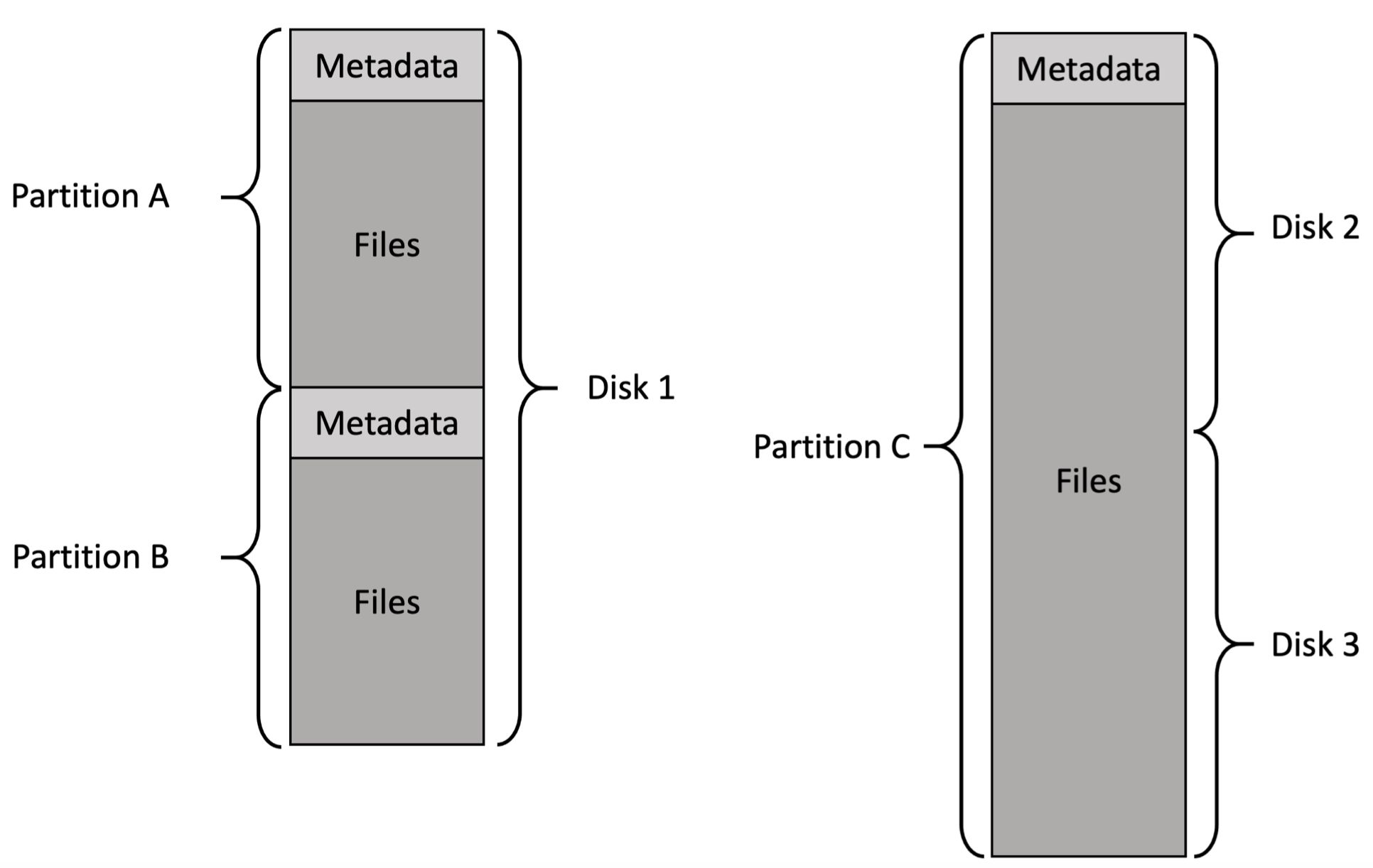
왼쪽 그림을 보면 하나의 디스크에 partion을 나누어서 partition마다 다른 파일시스템을 올릴 수 있다. 또 오른쪽 그림을 보면 여러 디스크를 묶어서 하나의 partition을 만들 수도 있다. 이는 디스크 경계를 넘어서는 파일을 만들 수 있다는 뜻과도 같다.
또 그림에는 metadata가 전부 맨 앞에있는데 이는 logical한 그림임을 참고하면 좋겠다. 나중에 조금 더 자세한 layout을 살펴보게 될 것이다.
File Operations
File을 읽을때 우리는 어떤 과정을 거칠까? 먼저 file을 open하고 그 다음 read or write을 하고 이를 close 해주어야 한다. 여기서의 open, read, close는 모두 시스템콜이다.
open(2)
int open(const char *pathname, int flags);
open은 파일의 path를 인자로 받아 파일을 open한다.
open을 호출하면 file descriptor를 반환받는다.
file descriptor는 음수가 아닌 숫자로 handle 이라고도 부른다. handle은 자동차의 핸들과 같은 의미인데, 자동차의 핸들은 바퀴를 돌려주는 것처럼 우리는 이 handle을 이용해 파일을 조작할 수 있다.
read(2)
ssize_t read(int fd, void *buf, size_t count);
read는 file descriptor를 인자로 받는다. 그리고 읽을 byte 수인 count를 인자로 받고 결과값을 buf에 넣어준다.
close(2)
int close(int fd)
file descriptor를 닫는다.
read, write는 어떤 파일을 읽겠다는 것을 나타내는 file descriptor를 인자로 받는다. 나중에 네트워크쪽에서도 socket 이라는 것이 있는데 socket의 생성에도 file descriptor를 반환받는다. 이를 가지고 send, recv를 하게된다.
우리는 read, write로 파일을 읽거나 쓸때 정확히 어디를 읽고 어디를 쓰겠다라는 위치를 전달하지 않는다. 그럼에도 파일을 계속해서 읽고 쓸수있다. 이것이 어떻게 가능할까?
리눅스는 내부적으로 current-file-position 포인터를 프로세스마다 들고있다. 그래서 프로세스가 파일을 읽거나 쓸때 해당 프로세스가 어디까지 작업했는지 이 포인터에 기록한다.
이 current-file-position을 변경하기 위해 seek 이라는 시스템콜을 제공한다.
여기서 알 수 있듯이 파일은 메모리랑은 다르다. 메모리는 seek이 필요없고 random access가 가능하다. 하지만 파일은 linear 하게만 왔다갔다 할 수 있으며 random access가 불가능하다.
open, close의 역할
File은 프로세스가 공유할 수 있다. 즉 파일 A가 있을때 프로세스1도 A를 읽을 수 있고, 프로세스2도 A를 읽을 수 있다. 이를 지원하기 위해서는 이 파일 A가 어떤 프로세스에게 읽히고 있다는 것을 내부적으로 저장해야한다. 그렇지 않으면 프로세스3이 파일 A를 그냥 delete 해버릴 수도 있다.
이를 가능하게 한게 open이다. open의 대략적인 역할을 살펴보자.
먼저 파일을 읽기위해 open을 하게되면 내부적으로 파일이 실제로 존재하는 것인지 탐색한다. 만약 존재한다면 해당 파일의 metadata를 메모리에 캐싱한다.
그 다음으로 open을 하게되면 내부적으로 open-file table이라는것이 만들어진다. open-file table은 두가지 형태로 존재하는데 하나는 per-process open-file table이고 또다른 하나는 system-wide open-file table이다.
이름으로 유추할 수 있듯이 per-process open-file table은 프로세스별로 존재하는 open-file table이고, system-wide open-file table은 시스템의 모든 open된 파일들에 대한 open-file table이다.
per-process open-file table에는 각 프로세스에서 유지하는 state를 저장한다. 예를들어 프로세스가 파일을 읽을때 내부적으로 파일을 어디를 읽고있는지를 나타내는 current-file-position 포인터를 저장한다.
system-wide open-file table에는 file open count, file access date, file location 등을 저장한다. open을 하면 file open count를 1 증가시키고, close를 하면 file open count를 1 감소시킨다.
delete는 system-wide open-file table에서 file open count가 0인지 확인을 한 후 이루어진다. 누군가 이를 open 하고있다면 delete 할 수 없다.
다음 그림을 보자.
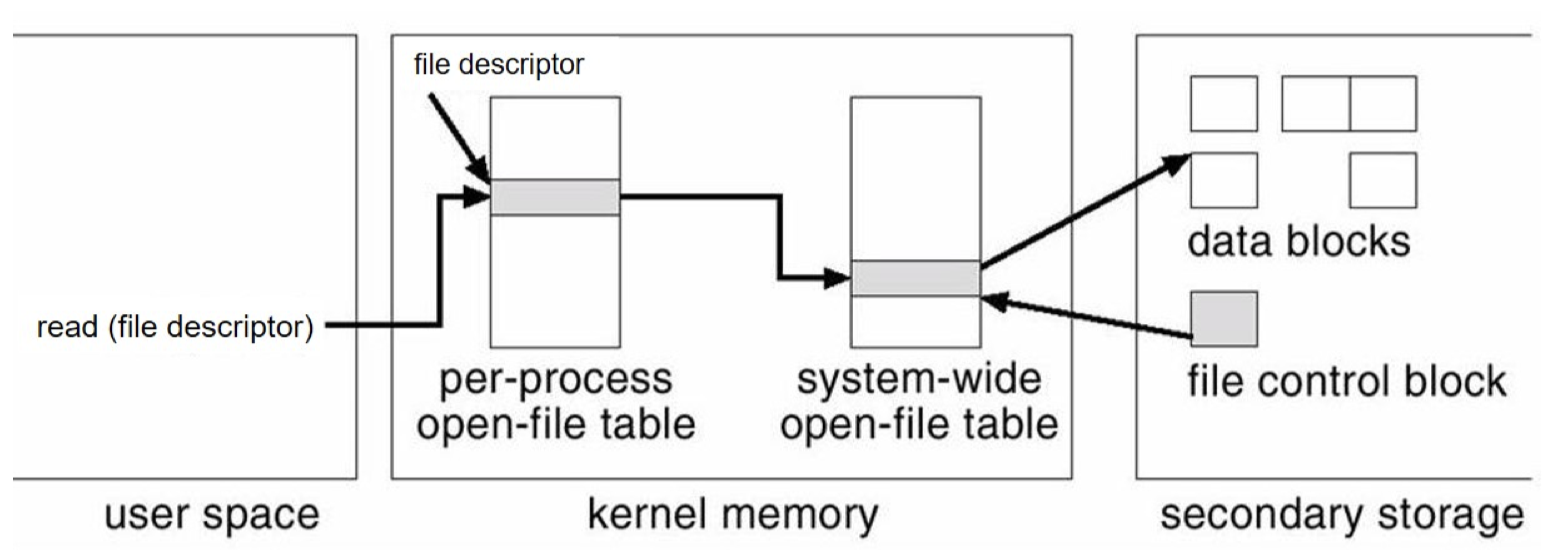
open은 per-process open-file table에서의 index 주소를 반환한다. 이것이 file descriptor 이다.
그리고 per-process open-file table에서의 값은 다시 그 파일의 system-wide open-file table entry를 가리킨다. 그리고 system-wide open-file table은 다시 그 파일의 metadata를 가리킨다.
이 metadata는 open할때에 메모리에 캐싱하게되며 flush daemon에 의해 disk에는 asynchronous하게 update된다.
만약 프로세스가 파일에 대해 close 하는 것을 까먹고 exit 했으면 어떻게 될까? system-wide open-file table에서의 file open count가 줄지 않았으므로 영원히 파일삭제는 못하는 것일까? 그렇지 않다.
실제로 close를 하지 않아도 file open count는 정상적으로 count 된다.
PCB(Process Control Block)에 해당 프로세스가 어떤 파일을 open 하였는지 이미 다 기록을 하고있기 때문에 close를 하지않고 exit하여도 이 내용을 보고 close count를 유지한다.
리눅스에서 file descriptor 0, 1, 2는 미리 정해져 있다. 0은 표준입력, 1은 표준출력, 2는 표준에러이다.
Directory
Directory는 파일을 나누어 저장하는 방법이다.
초창기에는 Single-level directory를 사용했다. 이는 한 사용자에 대해서 단일 directory만 생성하는 방식으로 하부 directory를 만들지 못한다.

이 글을 쓸때만 해도 안드로이드, iOS는 single-level directory였다. 이렇게 설계한 이유는 단순하기 때문이다.
나중에는 우리가 흔히 알고 사용하고 있는 tree structure directory를 만들었다. 이는 sub-directory를 생성할 수 있다.
다만 tree structure에는 root가 존재해야하며, acyclic graph 이여야 한다.
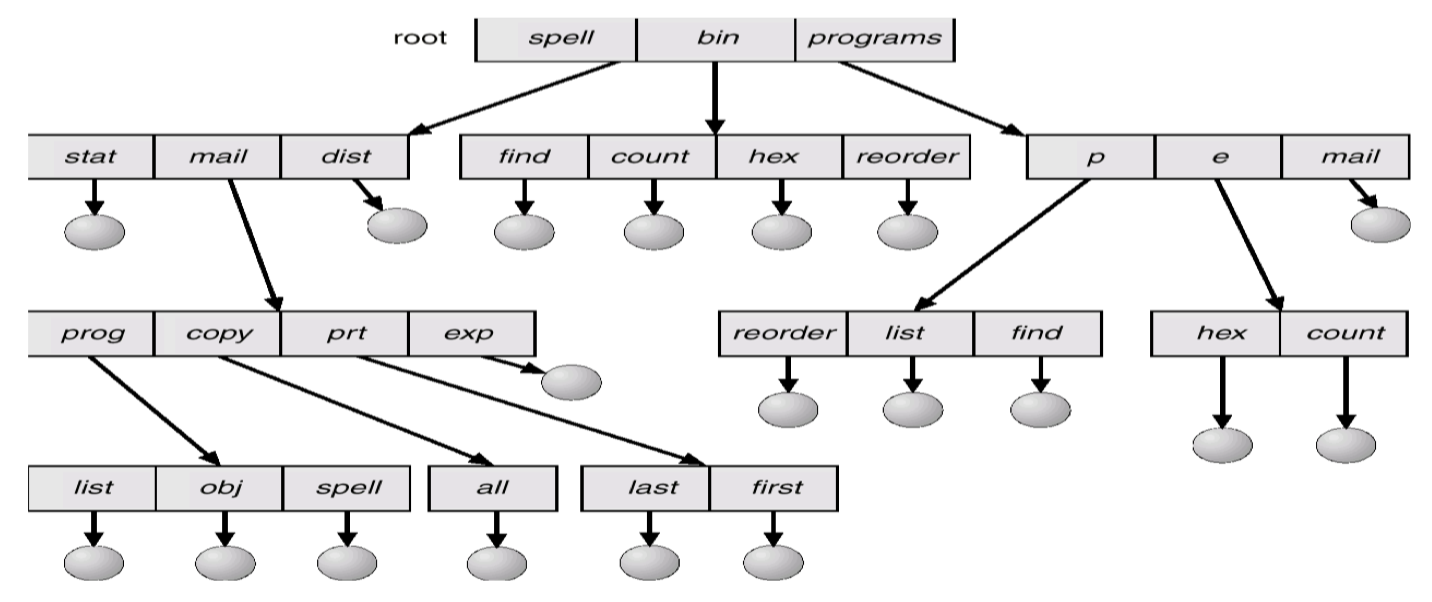
Link
File이나 directory의 공유를 허용하지 않으므로 이를 위해 두가지 종류의 link를 제공한다.
soft link, hard link이다.
Soft Link
soft link는 symbolic name의 개념이다. 삭제시 link만 삭제된다. 리눅스에 흔히 사용하는 symlink와 동일하다. 윈도우에서는 shortcut(바로가기)가 있다. 우리가 윈도우에서도 shortcut을 삭제하면 shortcut이 삭제되지 실제 파일이 삭제되지는 않는다.
Hard Link
실제 파일을 가리키는 alias이다. 삭제시 이 파일을 보고있는 process가 없다면 삭제한다.
그림을 보고 이해하면 쉽게 이해할 수 있다.
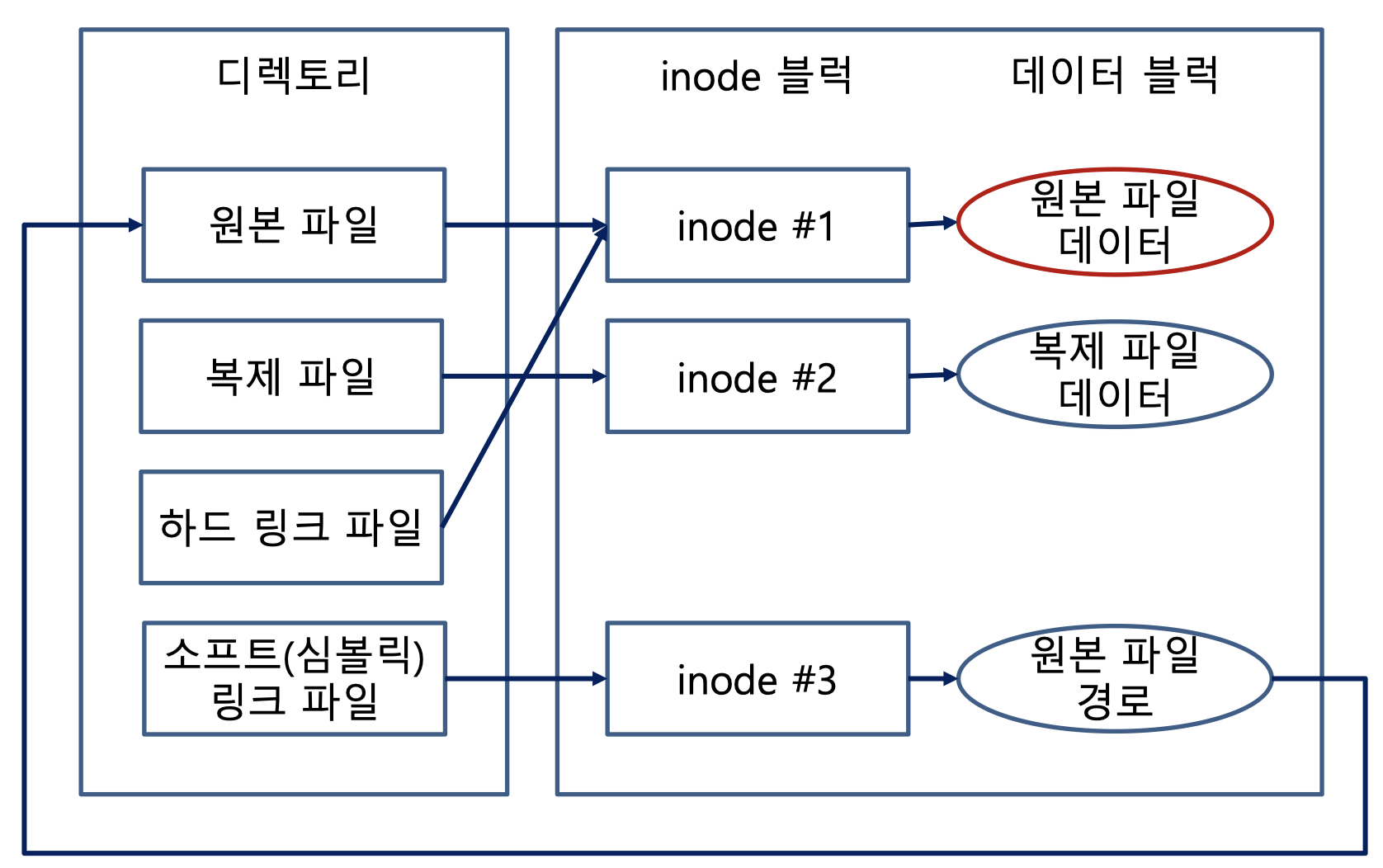
각 원본파일들에 대한 inode는 항상 존재한다. inode는 이 파일의 metadata를 의미한다.
내가 만약 파일을 복사(cp)하였다면 데이터도 복사되고 이를 가르키는 새로운 inode도 생성된다. 실제로 파일을 복사하는 개념이다.
hard link를 보자.
hard link는 원본파일의 inode를 그냥 가리킨다. 그래서 삭제시 실제 파일이 지워지는 개념이다.
이와 다르게 soft link는 inode를 새로 만든다. 다만 이 inode가 가르키는 데이터에는 원래 파일의 경로가 들어가있다. 그래서 이 원래파일의 경로를 보고 다시 파일에 접근한다. 위의 예제에서는 soft link의 파일을 읽을때에는 결국 inode #1을 통해 원본을 읽게된다.
그러므로 soft link 삭제시 본인의 inode를 삭제하므로 원본파일은 삭제되지 않는다.
Mount
Mount는 directory와 disk를 분리하는 개념이다.
Mount는 비어있는 directory에 임의의 device를 붙일 수 있다. 비어있는 directory라는 것을 강조한 이유는 다른 device가 mount 되어있지 않아있어야 한다는 것이다. 만약 이미 mount되어있다면 기존의 것을 unmount 해야한다.
파일시스템을 사용하려면 mount를 해야한다.
그림을 보고 이해해보자.
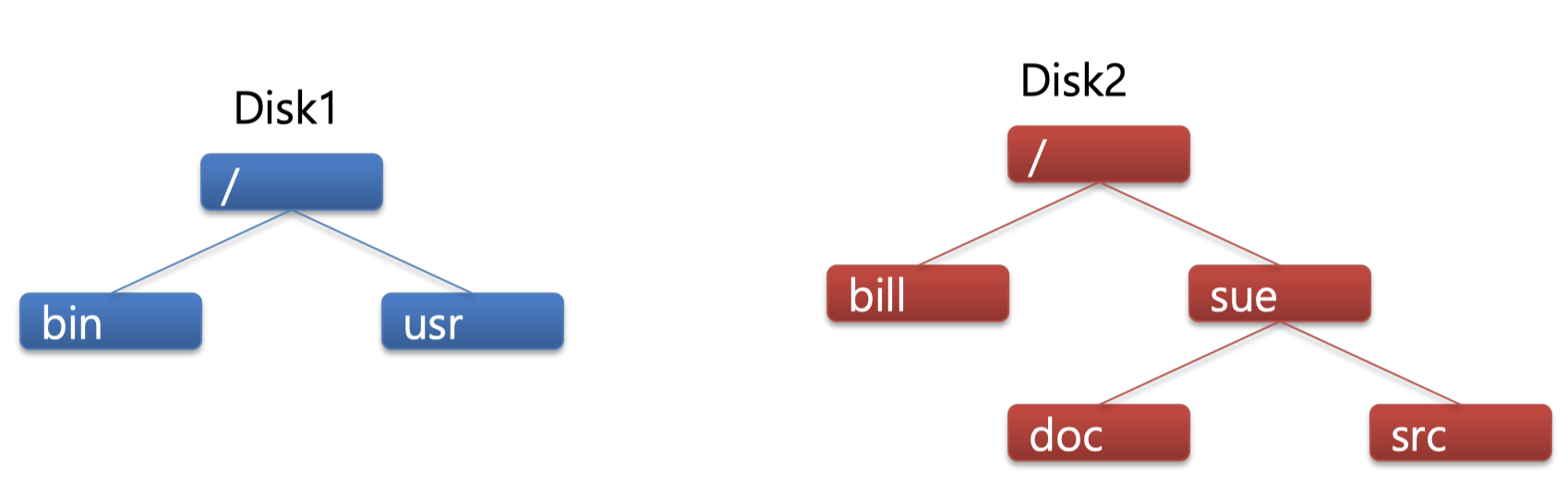
이와같이 두개의 disk가 있고 각각 파일시스템의 directory들이 이와 같다고 해보자.
disk2를 disk1의 비어있는 /usr/ directory에 mount를 해보자.$ mount disk2 /usr/
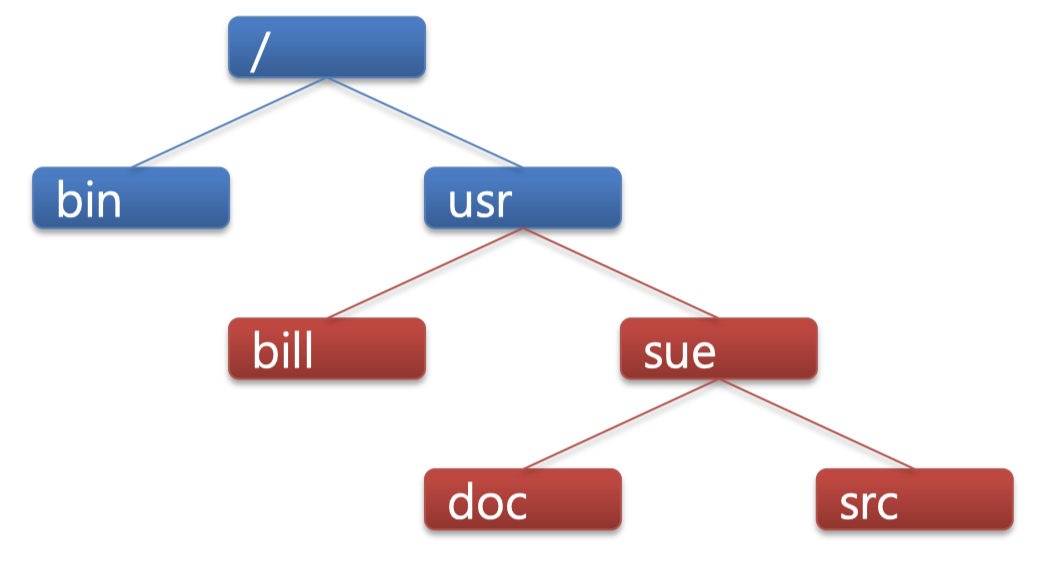
이처럼 mount를 하면 /usr/bill로 접근이 가능하다. 사용자는 disk1, disk2를 알 필요가 없이 그저 path로 접근하면 된다. 사용자는 본인이 어떤 device로 접근하고 있는지 알필요가 없다. 그러므로 mount는 scaleability가 좋고 device가 바뀌어도 사용자는 영향받지 않으므로 distributed File System으로 확장이 매우 용이하다. NFS(Network File System)을 사용하여 mount를 하게되면 다른 머신에 있는 file system을 local에서 나의 local에서 사용하는 것처럼 접근할 수 있다.
리눅스는 시스템이 부팅할때 mount를 통해 device tree를 결정한다.
Windows를 보면 c: 드라이브가 존재한다. 이는 c:의 device를 분리하지않고 미리 directory를 고정시키고 미리 정해놓은 것이다. 또 다른 device를 추가하면 d:, e: 로 추가된다. 이는 일반 사용자의 편의성을 고려한 방식으로 우리가 살펴보았던 directory와 disk를 분리하는 mount 방식이랑 다르다.
Namespace
namespace는 그냥 unique하고 식별가능한 이름이 있는 공간이라고 생각하면 된다.
위에서 본 mount는 namespace를 define한다. 프로세스들의 file namespace는 동일하게 mount 된 곳을 가진다면 서로 동일한 namespace를 보게 된다.chroot를 사용하면 프로세스별로 격리된 file namespace를 만들 수 있다. 즉 프로세스마다 서로 다른 루트를 가질 수 있도록 설정할 수 있다. 이는 컨테이너 기술에서 핵심적인 부분을 맡고있다.
Protection
이전에 보았던 운영체제 메모리편에서 프로세스는 protection domain을 가진다고 했다. 그리고 일반 프로세스가 kernel에 접근하려고 하면 접근을 할 수 없다. page table entry에 read, write에 대한 권한을 설정하며 권한관리를 하고있다.
하지만 파일은 이와는 다른 access control에 대한 정책을 가지고 있다.
어떤 방식을 채택하고 있는지 바로 말하기 전에 어떻게하면 파일에 대한 access control을 구현할 수 있을까 생각해보자.
protection을 어느 것을 주체로 할지부터 정해야한다.
예를들어 프로세스를 기준으로 protection을 할 수도 있을 것이다. 예를들어 프로세스 A는 파일 1번과 2번에 접근할 수 있도록 access control을 설정하도록 설계할 수 있겠다. 실제로 이런 방식의 file protection을 구현한 운영체제도 존재한다.
접근의 종류는 어떤 것으로 정해야할까? read, write 등의 권한종류가 있고 프로세스가 특정 파일에 대해 write 권한을 가진다면 이 파일을 삭제할 수 있도록 해야할까?
이는 구현하기 나름이며 각각 장단점이 있다.
우리는 unix 계열의 File Protection을 살펴보도록 하자.
Linux에서는 프로세스가 아닌 파일을 주체로하여 사용자에게 파일권한을 부여한다고 정했다.
그리고 access type을 다음과 같이 3가지로 정의했다.
- Read
- Write
- Execute
그리고 파일의 사용자들을 세가지로 분류하였다.
- owner : 파일을 만든 사람
- group : 사용자들의 집합
- public : 이외의 모든 사용자
그리고 access model을 위의 세가지 분류를 활용해 bit level로 protection을 정의한다. 이것이 무슨말인지 예제로 알아보자.
각 사용자들의 분류마다 RWX(Read, Write, eXecute) 순서의 bit를 정의하고 각 bit가 설정이 되어있으면 그에 대한 권한이 있다고 표현한다.
RWX가 7이면 R(4) + W(2) + X(1) 이므로 모든 bit가 설정되어있으므로 읽기, 쓰기, 실행권한이 모두 있는 것이다.
RWX가 6이라면 R(4) + W(2) 이므로 실행권한은 없으며 읽기, 쓰기 권한은 있는 것이다.
이에 대한 RWX를 owner, group, public 순으로 나열한다.
즉 파일에 대해 protection이 761로 설정이 되어있다면 owner(7), group(6), public(1) 로 설정되어 있다는 의미이다.
프로세스를 실행한 사용자가 파일의 owner라면 7이므로 이 프로세스는 read, write, execute를 할 수 있다는 의미이다.
만약 owner는 아니지만 파일에 설정된 group에 속한 사용자라면 6이므로 읽고 쓸수는 있지만 파일을 실행할 수는 없다.
만약 이 group에도 속하지 못한 사용자라면 public으로 파일을 실행만 가능하며 읽고 쓸수는 없다.
보통 text file은 실행을 할 수 없으므로 666으로 많이 설정하기도 한다.
download 한 파일들은 자동으로 보안을 위해 파일실행을 할 수 없도록 파일권한을 설정하기도 한다.
그리고 1은 자주사용할 것 같지 않아보이지만 실제로는 kernel이 관리하는 시스템 파일들은 execute만 가능하도록 1로 설정하도록 한다.
그리고 unix 계열에서는 파일에 대해 write 권한이 있으면 파일을 삭제할 수 있다.
파일에 대한 protection mode는 chmod 명령어를 사용하여 변경할 수 있다.chmod 761 filename 을 수행하면 해당 파일의 mode가 변경되며 이 명령은 파일의 owner 혹은 root만 수행할 수 있다.
파일의 owner 또한 chown 명령어로 변경할 수 있으며, 위의 group 또한 변경이 가능하다.
group은 /etc/group에서 정의되고 파일의 group도 chgrp 명령어로 변경할 수 있다.
파일은 owner와 group 이 각각 1개씩만 존재할 수 있다.
다음편에서는 파일시스템이 어떤 방식으로 구현이 되어있는지 살펴보도록 하자.