파일시스템 2편 - Flash 그리고 SSD
이 글은 학부 System Programming 수업을 듣고 다른 자료들과 함께 공부한 내용을 정리한 글입니다.
이전 포스트의 하드디스크에 이어 이번 포스트에서는 Flash 그리고 SSD에 대해 알아볼 것입니다.
이번 편은 이전의 운영체제 3편 - 컴퓨터 구조와 I/O 글의 I/O 부분을 이해하고보면 도움이 됩니다.
Flash Memory
하드디스크와 다르게 Flash는 메모리나 CPU처럼 트랜지스터 들로 구성이 되어있다. 즉 disk의 arm이 움직이거나 platter가 회전하는 물리적인 움직임이 없다.
Reliability 측면에서도 disk에 비해 훌륭한 편이다. Disk는 물리적인 head crash가 날수도 있고, dead block(더이상 사용할 수 없는 block) 자체가 생길 수 있다. 물리적으로 읽고 쓰기 때문이다. 그리고 disk는 생각보다 자주깨진다.
이와는 다르게 Flash는 순수한 silicon으로 구성되어 있으며 전자적으로 동작하기에 더 신뢰성이 높다. Flash는 또한 매우 빠른 access time을 제공하고 power가 적게드는 반도체 특성으로 disk에 비해 매우매우 저전력이다. Flash Memory는 여러타입이 있는데 보통은 NAND-Flash를 의미한다.
다만 Flash가 가진 특이한 특성들 때문에 이를 해결하기 위해 몇가지 기법들을 적용해야한다. 이들은 밑에서 자세히 알아볼 것이다.
Flash chip은 하나의 transistor의 1개 이상의 bit를 저장할 수 있다. SLC(Single-Level Cell) flash는 오직 1개의 bit만 transistor에 저장할 수 있고, MLC(Multi-Level Cell) flash는 2개의 bit를 저장할 수 있다. 그러므로 00, 01, 10, 11을 저장할 수 있다. TLC(Triple-Level Cell) flash는 3개의 bit를 저장가능하다. 전반적으로 SLC가 더 성능이 좋고 가격이 비싸다.
Block and Page
이를 설명하기 전에 명확히 해야할게 여기서도 block과 page 용어가 등장한다. 하지만 Flash에서 말하는 block과 page는 디스크에서의 block 그리고 virtual 메모리에서의 page와 다르다.
Flash는 크기에 대해 두가지 단위를 사용하는데 그것이 block과 page이다.
전형적으로 block은 128KB 혹은 256KB 의 크기를 가진다. page는 이보다 작은 2KB 혹은 4KB의 크기를 가진다.
Flash는 여러개의 block들로 이루어져 있고 1개의 block은 여러개의 page를 가진다.
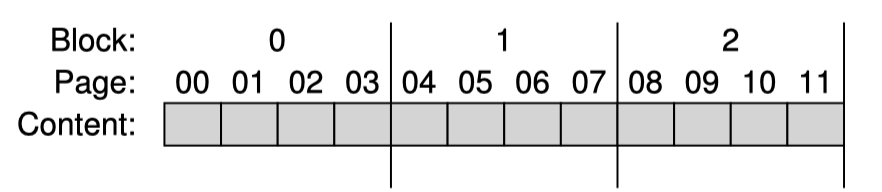
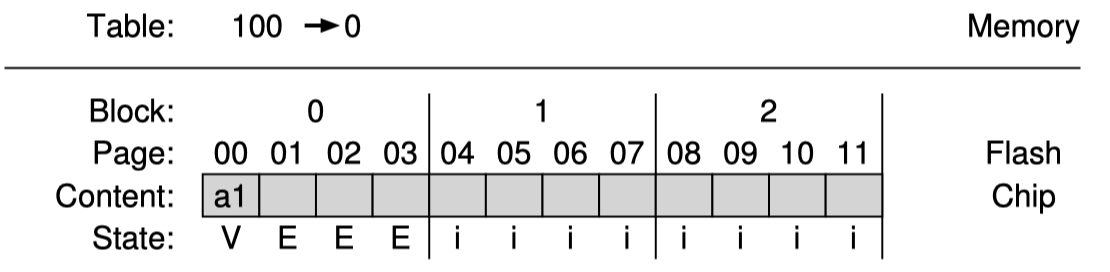
위 그림은 아주 간단하게 표현한 Flash chip의 구성이며 총 3개의 block, 그리고 각 block은 4개의 page로 구성되어 있다.
Basic Flash Operations
Flash chip 에서 제공하는 기본적인 3개의 low-level operation 들이 있다. read, erase, program 이 3가지이다.
Read
Read는 읽으려는 page number를 받아 page 1개를 읽어들인다. 보통 page를 읽어들이는데 10 micro sec 정도 걸리며 읽으려는 location에 무관하다. 즉 disk처럼 이전에 실행한 operation에 따라 head 위치와 rotation에 의존하는 방식이 아니며 어떤 location이라도 균일한 높은 읽기성능을 제공한다.
Erase
Flash는 page에 쓰기전에 page가 속한 block 전체의 지움이 선행되어야 한다. 즉 page가 속한 block을 먼저 erase해야한다. 그러므로 erase 전에 block을 memory나 다른 flash block에 copy 해놓아야 한다. Block이 지워지면 모든 bit이 1로 설정된다. erase operation은 비싼 작업이며 millisecond 단위이다.
erase가 되면 해당 block은 program 가능한 상태가 된다.
Program
Block에 erase가 먼저 진행된 page에 program을 할 수 있다. erase가 진행되었으니 해당 block은 모든 bit이 1로 설정되어있을 것이다. 이 1로 설정되어 있는 bit를 적절하게 0으로 바꾸면서 데이터를 write 하는데 이를 program이라고 한다. program은 erase에 비해 빠른편이며 100 micro sec 정도 걸린다.
Flash chip의 각 page는 metadata 정보를 담을 수 있는 조그만 공간이 존재한다. 이곳에 state 정보를 담고있다.
Page는 INVALID 상태에서 시작한다. Block이 erase 되었으면 그 안에있는 page 들은 ERASED 상태가 된다. 이들은 programmable 한 상태이다. page에 program을 하면 VALID 상태가 되며 이는 내용이 써져있는 상태이고 읽을 수 있는 상태임을 뜻한다.
Page는 한번 program 된 이후에 이 내용을 바꾸기 위해서는 해당 page의 block을 먼저 erase해야한다.
다음 예제를 보며 이해하면 쉽다. block마다 4개의 page가 있는 구조에서 page에 program 하는 과정을 표현했다.
1 | |
Flash chip Reliability
Flash에서 read는 굉장히 쉽고 그냥 읽으면된다. disk보다 훨씬 빠른 access time을 제공하고 random read 성능이 뛰어나다. SLC의 경우 10 micro sec만 걸릴뿐이다. Disk는 읽기도 millisecond 단위였던걸 기억하자.
하지만 Flash의 물리적인 특성상 page에 쓰기위해서는 해당 block이 먼저 지워져야 한다. 이를 Program / Erase 라고 하여 PE cycle이라고 부른다. 하지만 block에 PE cycle이 반복될시 flash chip에 reliability 문제가 생긴다.
Flash에서는 block 당 가능한 P/E cycle 횟수가 한정적이다. MLC(Multiple-Level Cell) 에서는 1만번의 P/E cycle 수명을 가진다. SLC는 이보다 높은 10만번의 P/E cycle 수명을 가진다.
이를 넘어가면 그 block이 unstable 해진다. 조금 더 정확히는 bit를 0과 1을 구분하기가 점점 어려운 상태가 되므로 그 block은 더이상 사용되지 못하게 된다. 이를 wear out 이라고 부른다.
따라서 Flash에서는 wear out을 해결하기 위한 또다른 숙제가 존재한다.
또 다른 reliability 문제로는 disturbance라는 문제가 존재한다. Flash의 page를 읽을때 같은 block에 있는 주변의 page들의 bit를 flip할 수 있는 가능성이 있다. 이를 read disturb라고 부르며 block erase 이후의 page read count의 threshold를 넘어가면 해당 문제가 일어날 가능성이 높다고 한다. 이를 해결하기 위한 숙제도 존재한다.
Flash to SSD
이제 flash chip의 특성에 대해 어느정도 알아보았다. 이 flash chip 하나로는 storage로 활용하기 힘들고 flash chip 여러개를 모아 flash 기반의 SSD를 만든다.
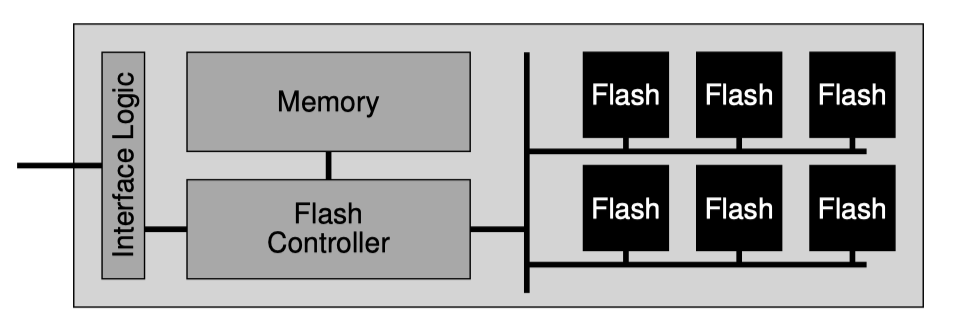
표준 storage 인터페이스는 block 기반으로 512 byte인 sector 크기 단위로 읽고 쓰여질 수 있다.
flash 기반의 SSD의 역할중 하나가 내부적으로는 flash를 사용하지만 그 위에서 이 standard storage block 인터페이스를 외부에 제공하는 것이다.
내부적으로 SSD는 여러개의 flash chip 들로 구성되어 있으며 위 구조에서도 볼수있듯이 내부에 SRAM 같은 메모리도 존재한다. 이 메모리로 캐싱이나 buffering에 활용한다. 그리고 device operation을 위한 control logic을 포함한다.
이 control logic 에서 해야하는 주된 내용은 client로부터의 read, write를 내부적으로 적절하게 flash operation으로 변환하는 것이다. FTL(Flash Translation Layer)가 이 역할을 하게된다.
FTL은 logical block 기반의 read, write 요청을 받고 이를 flash의 read, erase, program operation 으로 적절하게 변환한다. 그리고 FTL은 이런 작업들을 높은 성능과 높은 reliability를 제공하면서 진행해야 하는 책임도 가지고 있다.
높은 성능을 위해 여러개의 flash chip들을 병렬로 활용하기도 한다.
그리고 flash 특성상 INVALID 혹은 VALID 상태에 있는 page에 program을 하기 위해서는 반드시 그 block은 먼저 erase가 선행이 되어야 하는데 page 1개만 변환하려 해도 전체 block을 다시 써야하는 문제가 있다. 이를 쓰기 증폭, 즉 write amplification 이라고 부르는데 이를 줄이기 위한 노력도 같이한다.
그리고 높은 reliability를 제공하기 위해 wear out 문제도 고려해야한다. 한개의 block에만 PE cycle을 하는 것이 아닌 최대한 모든 block에 균등하게 처리되도록 해야 wear out을 막을 수 있다. 이를 wear leveling 이라고 한다.
또 위에서 본 disturbance를 최소화하기위해 erased 된 block에 page를 낮은 page부터 높은 page 순서로 program 하는 방법을 택한다.
FTL 구현
어떻게 하면 FTL을 구현할 수 있을까?
간단하게 logical page number 그대로 physical page number 로 매핑을 해주는 FTL이 있다고 생각해보자.
이 방식이라면 그대로 매핑해주는 방식이기에 logical page N 에 대해 read 요청이 오면 그대로 physical page N 을 읽어 반환한다. read에는 큰 문제가 없다.
write를 생각해볼때, write 요청이 오면 flash 특성상 해당 page의 block을 erase 한 후 그 block의 page로 다시 program 해야한다. 그래야 다음 read에 대해 동일한 physical page N을 읽을 수 있도록 보장할 수 있다.
이 방식으로 FTL을 구현하면 첫번째로 성능측면에서 문제가 있고 reliability 문제도 존재한다.
flash의 특성으로 page에 write을 할때마다 해당 block의 모든 page를 먼저 읽어들이고, 해당 block을 erase, 그리고 이 block의 page에 다시 program을 해주어야한다. 이를 매 write 마다 해주어야 하므로 디스크의 write보다 느리다.
그리고 파일시스템의 metadata 혹은 data block이 업데이트 될때마다 같은 block이 PE cycle을 반복하게 되므로 그 block은 빠르게 wear out이 될 것이다. 이처럼 write 요청을 다른 여러 물리 block에 균일하게 배정하지 않으면 block이 빠르게 wear out 된다. 그러므로 direct로 logical page를 그대로 physical page로 매핑하는 방식은 좋은방법이 아니다.
Log-Structured FTL
여기서는 log structured 방식을 설명하는데 이는 storage device 뿐만아니라 file system 에서도 유용한 아이디어이다. 대부분의 FTL은 log structured 방식을 사용한다. 이를 살펴보자.
Log-Structured 방식에서는 logical page에 write 요청이 왔을시, 현재까지 쓰여진 block에 바로 다음 free spot에 데이터를 쓴다. 이런 방식을 logging 이라고 부른다.
하지만 이런 방식으로 쓰면 read를 할때 logical page가 어떤 physical page에 쓰여졌는지 기록을 해놓아야 하므로 mapping table이 필요하다.
예시를 보며 이해해보자.
클라이언트는 그저 device를 sector 단위인 512 byte(혹은 sector의 group)로 읽고 쓸수있는 전형적인 disk 라고 생각한다는걸 잊지말자. 여기서의 클라이언트는 파일시스템이라고 하자.
예시를 간단하게 하기위해 몇가지 가정을 하자.
- 파일시스템은 4KB 단위의 chunk로 데이터를 read, write 한다.
- SSD는 16KB의 block들로 이루어져있고 각 block은 4KB의 page들로 이루어져 있다.
클라이언트는 다음 순서로 operation을 요청한다.
- 데이터 “a1”을 logical block
100에 write한다. - 데이터 “a2”을 logical block
101에 write한다. - 데이터 “b1”을 logical block
2000에 write한다. - 데이터 “b2”을 logical block
2001에 write한다.
여기서의 logical block number는 flash의 block과는 다름을 주의하자.
위 요청을 받았을때 초기의 SSD는 모든 block의 page들이 INVALID 상태이므로 어느 block에 이를 program하든지 erase가 먼저 선행되어야 한다. FTL이 이를 block 0에 program 한다고 가정했을때 먼저 block 0을 erase 한다.
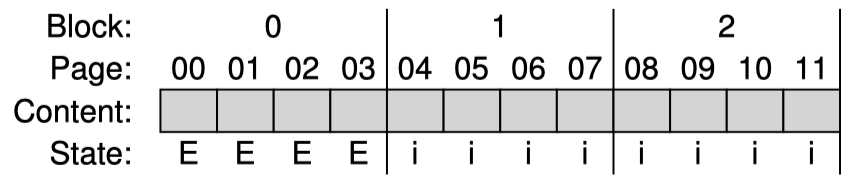
block 0 은 이제 program을 할 수 있는 상태이다. 대부분의 SSD는 앞에서 본 disturbance(read 시 주변 셀들을 변경할 수 있음) 문제를 줄이기 위해 page를 앞에서부터 차례로 쓴다.
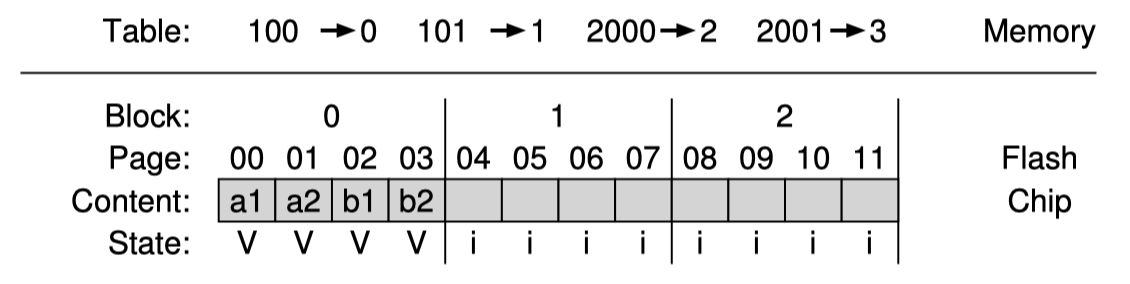
그러면 처음 logical block 100에 대한 요청을 physical page 0에 write한다.
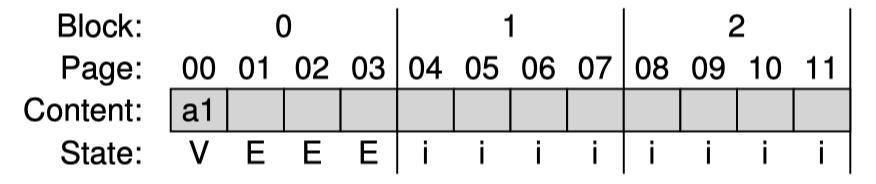
위처럼 physical page 0에 data가 쓰여졌다. 만약 파일시스템이 logical block 100을 다시 읽으려면 어떤 처리를 해주어야할까? FTL은 read 요청을 받았을때 logical block을 physical page로 적절하게 mapping 해줄 수 있어야한다. 이를 위해 in-memory mapping table을 만들어 기록하자.
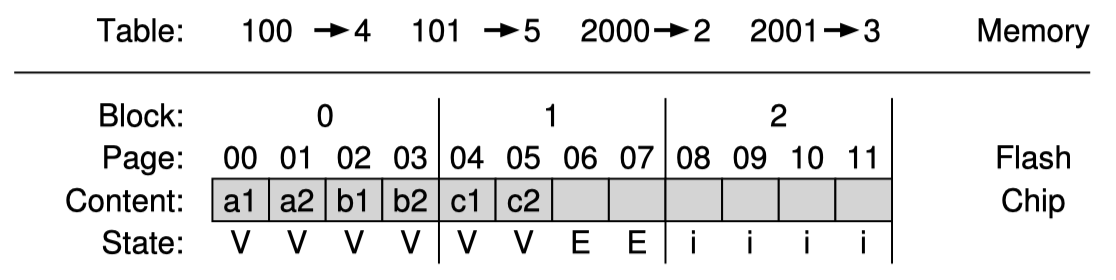
SSD에 write을 할때에는 현재까지 작성한 block의 다음 비어있는 page에 program한다. 그리고 이에 대한 정보를 mapping table에 기록한다. 다음 해당 page들에 대한 read요청이 왔을때 client로 부터 온 logical block 을 physical page로 mapping table을 이용해 변환하여 실제로 어떤 physical page를 봐야하는지 결정한다. 나머지 3개의 logical block도 다 쓰게되면 다음과 같다.
최종상태는 위와같은 그림이 될 것이다.
이런 logging 기반의 구조는 성능적으로 뛰어난데 매번 write 할때마다 block을 erase할 필요가 없다. 그리고 reliability 측면에서도 FTL이 write 시 여러 block을 골고루 사용하도록 설계할 수 있으며 이 덕에 device의 수명을 늘릴 수 있다. 이런 해결을 wear leveling한다 라고 표현한다.
하지만 이런 logging 기반 구조는 단점이 존재하는데 logical block을 수정해야 할때에는 garbage가 생긴다. 새로운 page에 다시 program 하므로 이전에 있던 page는 garbage가 된다. 그래서 SSD는 주기적으로 이런 garbage들을 정리하고 free space를 확보하는 garbage collection을 진행해야한다. 과도한 GC는 write amplification을 발생시키고 성능을 낮춘다.
그리고 mapping table을 관리해야 하는 문제도 있다. mapping table이 클수록 그만큼 더 큰 memory를 요구하게 된다.
mapping table을 in-memory로 관리하는데 power가 꺼지면 어떻게 될까? memory는 휘발성으로 당연히 날아간다. 하지만 mapping table이 없으면 read operation을 처리해주지 못하므로 SSD는 mapping table을 복구할 수 있는 장치를 마련해야한다.
간단하게는 각 page에 out-of-band(OOB)라는 영역에 mapping 정보를 기입해놓을 수 있다. 이를 기반으로 SSD를 켤때 모든 page들을 읽어 mapping table을 재구성할 수 있다. 하지만 모든 page를 scan해야 하므로 성능이 좋지않다.
최근에는 복잡한 logging과 checkpoint 방식의 기법으로 빠른 recovery를 지원한다.
Garbage Collection
위의 예제를 다시 이어서 보면 마지막에는 page 0과 1에 각각 logical block 100 그리고 101 이 매핑되어 있었다. 만약 logical block 100과 101을 다시 write 하면 어떻게될까?
다음 block의 free page에 쓰여질 것이다. 그리고 page 0과 1은 VALID 상태이지만 최신버전이 아니므로 garbage이다.
log-structure 기반의 device는 garbage를 계속 만들어내므로 free space를 더 확보하기 위해 garbage collection을 진행해야한다. 이는 최신 SSD에서도 고려해야하는 중요한 요소이다.
GC의 기본적인 과정은 이와같다.
- 최소 1개이상의 garbage page를 가지고 있는 block을 찾는다.
- 그 block의 아직 live 한 page들을 읽는다.
- 읽은 live한 page들을 log(block)에 쓴다. 그리고 기존 block을 erase 하여 새로운 write에 사용할 수 있도록 한다.
GC가 이 과정을 수행하기 위해 어떤 page가 live 한지 혹은 garbage 인지 판단할 수 있어야하는데, 간단하게는 mapping table 을 이용할 수 있다. mapping table에는 실제 physical page들이 명시되어있으므로 이들이 live한 page이다.
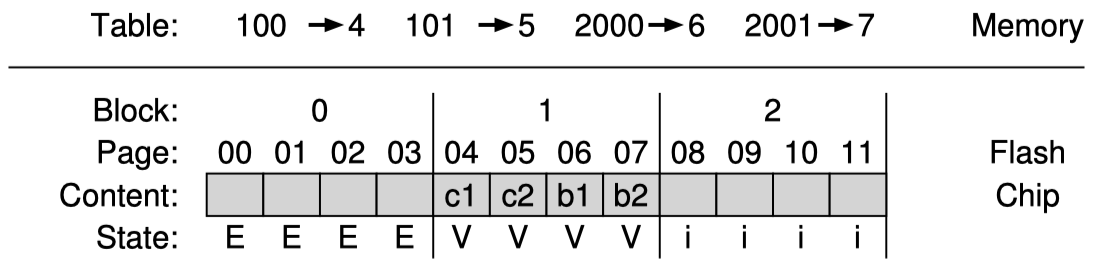
이런 방식으로 위의 예제에서 logical block 100과 101에 각각 데이터 “c1”과 “c2”를 다시 쓰게되면 다음과 같이된다.
현재 mapping table을 보게되면 page 0과 1이 garbage인 것을 알 수 있다. 그러므로 block 0 에 있는 live한 page인 page 2와 3을 읽어 이들을 log에 쓴다. 즉 다음 free space에 쓰고 block 0을 erase 하여 다음 program operation에서 활용할 수 있도록 한다.
따라서 mapping table도 새로 update 되고 block 0 도 erase된 상태가 되었다.
이처럼 GC는 live data를 판단하기 위한 read 그리고 이들을 copy 하여 rewrite, 만약 block이 전부 dead page들로 이루어져 있으면 erase 까지 진행하므로 비싼 작업이다. 그래서 현대 SSD에서는 추가적으로 flash 용량을 더 두어서 device가 바쁘지 않을때 background 에서 GC를 수행하도록 한다. flash 용량을 더 두게되면 data cleaning에 사용할 수 있고 storage bandwidth도 높일 수 있다.
Mapping Table
위에서 확인했듯이 Log-Structured 방식은 mapping table이 필요하다. 다만 이 mapping table 크기가 문제이다. 예를들어 4KB page로 구성되어있는 1TB의 SSD가 있다고 할때 mapping table entry가 4byte라면 mapping table의 크기는 1GB가 된다. 즉 mapping table 만을 위해서 1GB의 memory가 필요한 것이다.
이를 극복하기 위한 Block-Based Mapping 방식과 최근 많은 SSD에서 채택하는 Hybrid Mapping 방식을 알아볼 것이다.
Block-Based Mapping
Block 기반 mapping은 page 별로 mapping을 하는게 아니라 block 단위로 mapping을 한다.
이렇게 block 단위로 매핑을 하면 mapping table의 크기는 size of block / size of page 로 나눈 값으로 줄일 수 있다. 예를들어 block 1개에 4개의 page가 들어간다면 page-based mapping 방식에 비해 mapping table의 크기를 4분의 1로 줄일 수 있다.
간단하게 예시를 보며 이해해보자.
위에서 본 예시와 조금 다르게 지금 우리가 logical block 2000, 2001, 2002, 2003 까지 각각 데이터 a, b, c, d를 write한 상태라고 하자.
block 단위로 mapping을 하므로 block 번호의 맨 뒤 2bit만 offset으로 활용하고 그 앞부분은 block number로 활용할 수 있다. 마치 page table 에서 page number와 offset으로 물리메모리를 찾는 방식과 비슷하다.
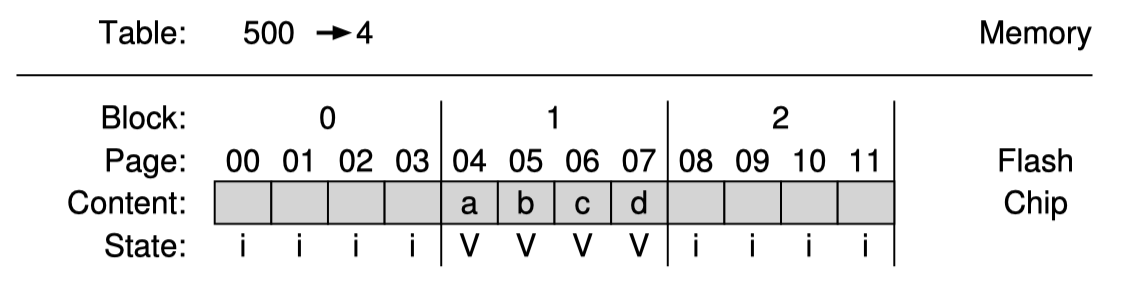
따라서 2000, 2001, 2002, 2003 은 각각 offset 0, 1, 2, 3을 가지고 block number는 같다. 예시에서는 block 1개에 page가 4개 있고 위의 write을 physical page 4에 할당하였으므로 mapping table에 500 -> 4로 기록한다.
read 요청이 왔을때에는 logical block 번호를 4로 나눈 값으로 physical page number를 찾고 offset으로 page 순서를 계산할 수 있다.
하지만 Block-Based Mapping은 성능적으로 많이 좋지않다. 문제는 작은 단위의 write이 일어날때 발생한다. 작은 단위의 write이 발생해도 old block 전체를 읽어 새로운 block에 다시 써줘야한다. 이런 data 복사는 write amplification 으로 이어진다.
만약 위의 예제에서 logical block 2002를 다른값으로 수정하면 어떻게될까?
FTL은 logical block 2000, 2001, 2003을 읽고 이들을 다른 block에 새로 써주어야 한다. 그리고 block 1은 erase될 수 있다.
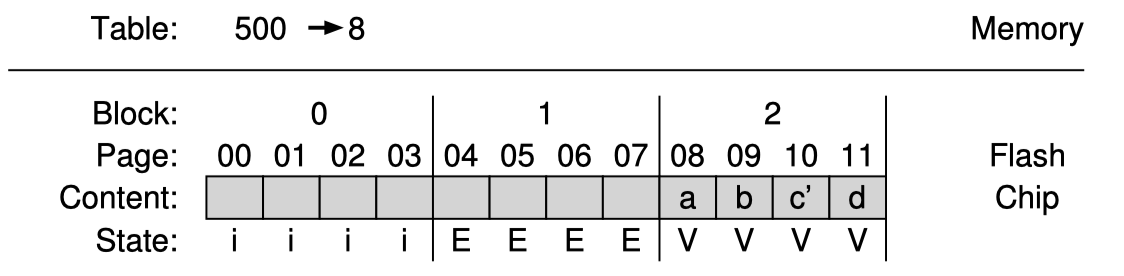
이처럼 mapping table 크기관점에서는 훨씬 작은 크기를 가져갈 수 있기때문에 좋은 해결책일 수 있으나 성능이 매우 좋지않아 이 방식을 그대로는 활용하기 힘들다.
Hybrid Mapping
많은 현대 SSD 제품들은 Hybrid Mapping 방식을 사용한다. 이를 알아보자.
Hybrid Mapping은 이름에서 유추할 수 있듯이 block-based mapping과 page-based mapping을 함께 사용한다.
먼저 FTL은 몇개의 block들을 erased 상태로 남겨두고 모든 write를 이 block들에 쓴다. 이 block 들을 log blocks 라고 부른다. Hybrid Mapping 에서는 page에 대한 write을 log block의 아무 위치에 쓸수있도록 고안되었기 때문에 이 log block에 속한 block들에 한하여 page-based mapping table을 가진다.
따라서 FTL은 두종류의 mapping table을 사용한다. 먼저 log block 들을 대상으로 작은 크기의 page-based mapping table을 가지고 나머지 부분인 data table에 대해 block-based mapping table을 가진다. logical block에 대한 read 요청이 오면 먼저 log table을 확인하고 없다면 그때 data table을 확인한다. (mapping table을 확인한다는 것이다.)
Hybrid Mapping에서 중요한 것은 log block을 작게 유지하는 것이다. 그러려면 주기적으로 log block을 검사해 이들을 data block으로 만들어 block-based mapping을 사용하도록 해야한다. 예제를 보며 이해해보자.
FTL이 이미 logical page 1000, 1001, 1002, 1003을 write을 한 상태이고, 값을 각각 a, b, c, d 라고 하자. 이들은 physical block 2에 쓰였다.
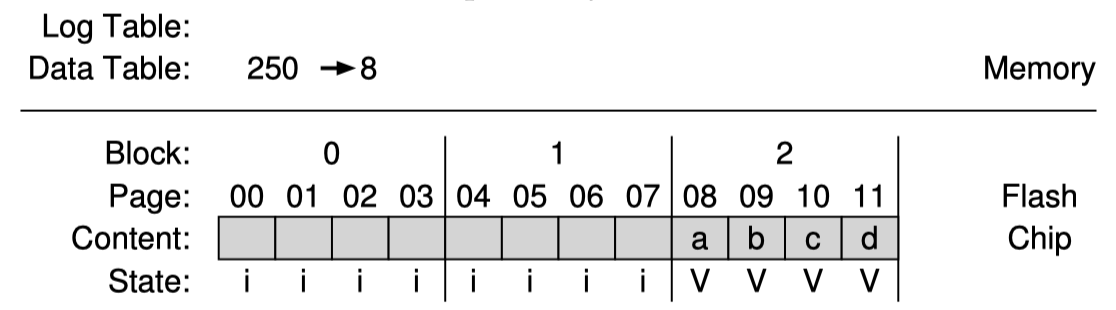
그런데 파일시스템이 logical page 1000, 1001, 1002, 1003 순서대로 하나씩 수정했다고 해보자. 이때 program 할 수 있는 log block은 block 0 이라고 해보자. 그러면 다음과 같은 상태가 된다.
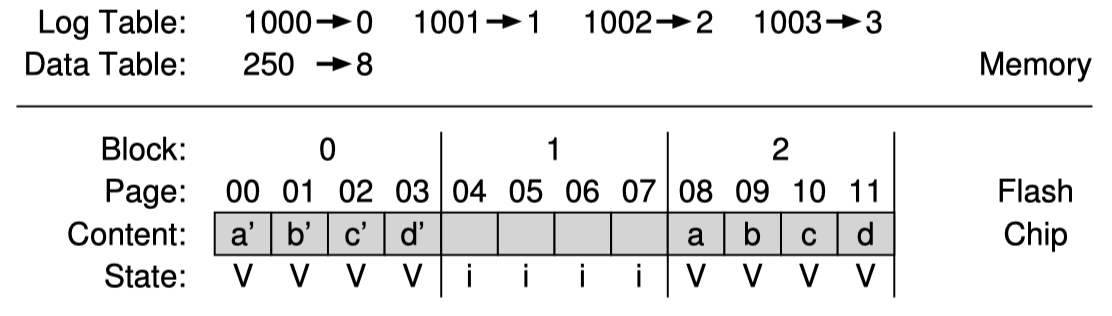
log block에 대해서는 page-based mapping을 사용하는 것을 주목하라.
운이 좋게도 이전에 block 2 에 쓰였던 순서와 동일하게 block 0 에 쓰여졌으므로 FTL은 switch merge라는 것을 진행할 수 있다. 여기서는 block 0 이 data block이 되고 block-based mapping 방식으로 변경될 수 있다. 그리고 block 2는 erase될 수 있다. 이는 FTL이 가질 수 있는 최상의 시나리오다. 결과는 다음과 같다.
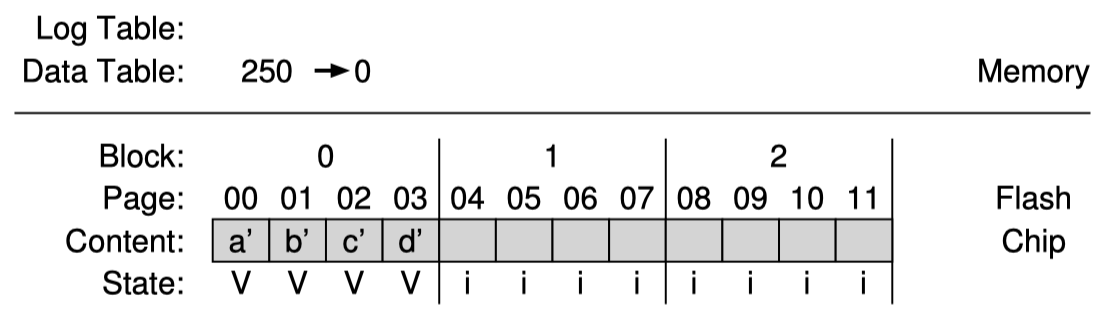
page-based mapping이 모두 block-based mapping으로 대체되었고 block 2는 erase 되어 log block으로 사용할 수 있게 되었다.
만약 이와 같은 최상의 시나리오가 아니라 파일시스템이 logical page 1000, 1001 만 수정했다고 하면 어떻게 될까? 다음과 같은 상태가 될 것이다.
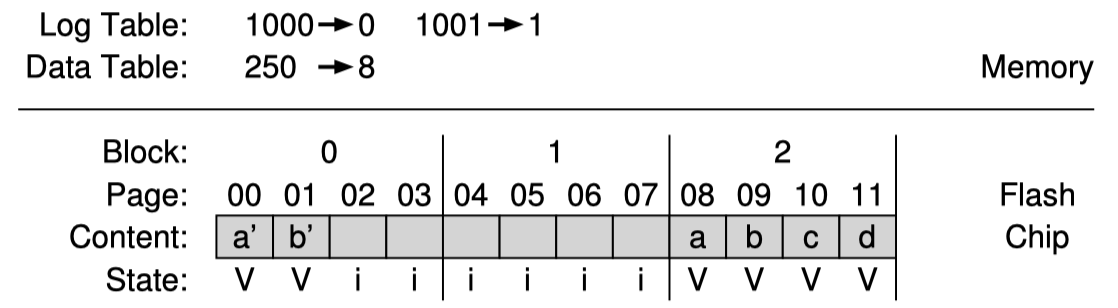
여기서 page 들을 합쳐 재구성하기위해서 FTL은 partial merge라는 것을 진행할 수 있다. physical block 2에서 logical block 1002, 1003 을 읽어 이 내용을 다시 log block에 append 한다. 그러면 결국 결과는 위의 switch merge와 같아진다. 다만 여기서는 추가적인 read, write가 필요하므로 write amplification이 증가할 수 있다.
만약에 최악의 상황에서 logical block 0, 4, 8, 12 가 physical block A 에 써있다고 하자. 그러면 이 log block 들을 data block로 변경하기 위해서는 logical block 1, 2, 3 이 써져있는 physical page를 찾아 이들을 읽고 새로운 block에 logical block 0, 1, 2, 3을 차례로 써주어야한다. 그다음 logical block 5, 6, 7 이 써져있는 page를 찾아 다시 새로운 block에 써준다. 그리고 이들을 data block으로 만든다. 이를 full merge 방식이라고 부르며, 이 full merge는 성능상 좋지않으므로 자주 실행되면 안된다.
Wear Leveling
FTL은 반드시 wear leveling을 구현해야 한다. FTL은 이를 위해 최대한 모든 block에 균등하게 write하려고 노력한다.
앞서본 log-structured 방식은 구현자체가 write를 여러 block에 나누어할 수 있고 GC 또한 wear leveling에 도움이 된다. 하지만 몇몇 data block들은 오랜 수명을 가지고있어 수정되지 않고 계속 변하지 않고 그대로 저장되어 있을 수 있다. 이들은 정상적인 data로 GC 대상도 아니다.
전체 block을 대상으로 write을 균일하게 써야하는 FTL 입장에서는 이런 long-lived data 가 문제일 수 있다. 이를 극복하기 위해 FTL은 주기적으로 모든 live data를 읽고 다른 block에 다시 write하는 작업을 진행한다.
이는 write amplification을 증가시키고 성능저하를 일으킬 수 있지만 모든 block이 동일한 수명을 가지게 할 수 있다. 이 방법 말고도 많은 알고리즘이 이미 고안되어 있다.
SSD Architecture
SSD 전체구조를 그림으로 한번 보고가자.
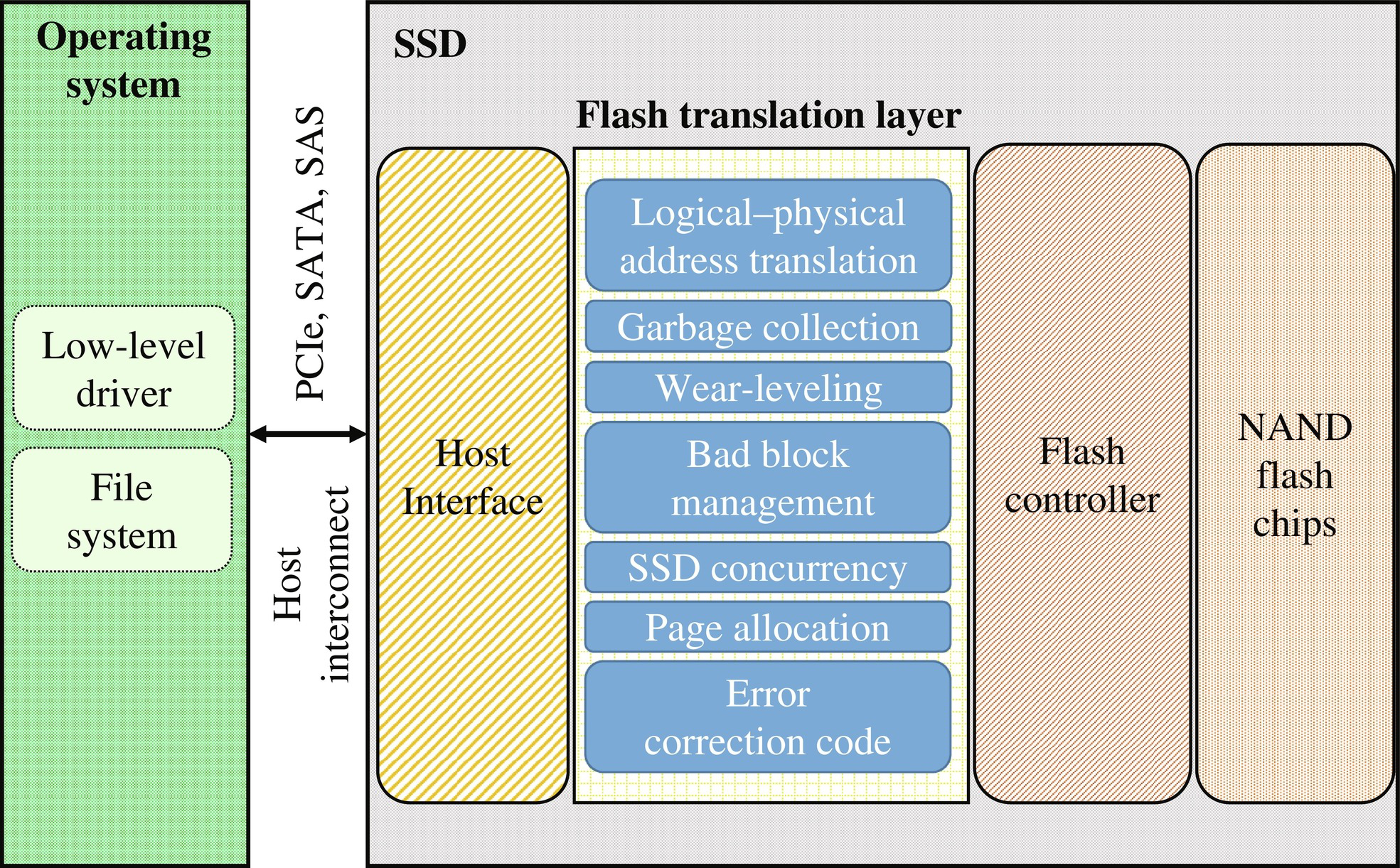
FTL layer를 보고 어떤 일들을 하고있고 이들을 왜 해야하는지 이제 이해를 할 수 있을것이다.
Performance
SSD는 하드디스크처럼 모터로 돌아가는 기게적인 부분이 없이 전자적으로 작동한다. 성능측면에서 SSD와 하드디스크를 비교를 해보자.
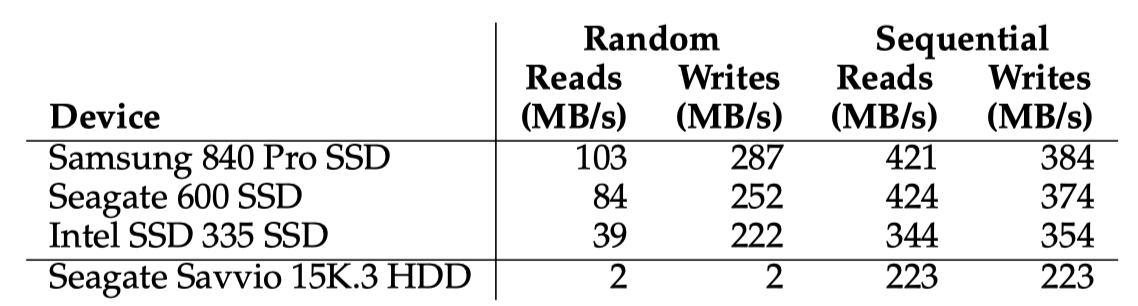
Random I/O의 경우 하드디스크는 거의 1초에 몇백개의 byte만 처리할 수 있는반면 SSD는 훨씬많이 할 수 있다. SSD는 random I/O를 거의 몇십 몇백 MB/s 로 처리할 수 있으므로 아주 높은 성능을 가진다.
Sequential I/O를 보면 SSD가 더 빠르긴 하지만 하드디스크도 괜찮은 선택일 수 있다. 하드디스크도 충분히 좋은 성능을 내고 있음을 볼 수 있다.
조금 특이한건 SSD의 random write이 매우 좋은 성능을 가지고 있는데 이는 대부분의 SSD가 채택하고 있는 log-structured 구조 덕분이다. 이는 random write을 sequential write처럼 동작하도록 FTL이 처리하기 때문이다.
또 SSD에서 random read 보다는 sequential read가 더 빠른걸 볼 수 있는데, 이는 sequential read는 read에 대한 operation을 큰 data 를 대상으로 한번에 받을 수 있기 때문이다. random read는 매번 각기 다른 주소에 대한 read 요청을 받아야 한다. 그러므로 처리량이 sequential read가 더 높을 수 밖에 없다. 경우에 따라 내부적으로 가진 cache의 영향도 있을 수 있다.
SSD가 하드디스크에 비해 가격이 높으므로 사용하려는 시스템에 따라 높은 성능과 random read performace가 중요한 시스템은 SSD를, 엄청난 양의 데이터를 저장해야하는 data center를 구축해야 하는 경우는 하드디스크가 가성비 측면에서 좋은 선택이 될 수 있겠다.